Agentic LLM Workflows for Generating Patient-Friendly Medical Reports

0
👀
Sign in to get full access
Overview
- Large Language Models (LLMs) are being applied in healthcare, including translating formal medical reports into patient-friendly versions.
- However, LLM outputs often require human editing and evaluation to ensure accuracy and readability.
- This paper proposes an "agentic workflow" using the Reflexion framework, which uses iterative self-reflection to improve LLM outputs.
- The pipeline was tested on 16 radiology reports and compared to a zero-shot prompting approach.
Plain English Explanation
The paper explores using Large Language Models to translate complex medical reports into language that patients can more easily understand. Currently, this process often requires a human to review and edit the LLM's output to ensure it is both medically accurate and easy for patients to read.
To address this, the researchers developed an "agentic workflow" that uses a technique called "Reflexion." This allows the LLM to repeatedly review and refine its own output, correcting any mistakes or areas that need to be made more clear for patients.
They tested this approach on 16 sample radiology reports and compared it to a "zero-shot" method where the LLM generates the patient-friendly report with no self-reflection. The results showed the Reflexion-based approach was significantly more accurate, with 94.94% of the reports correctly matching the medical codes, compared to 68.23% for the zero-shot method. Additionally, 81.25% of the Reflexion reports required no further corrections, while only 25% of the zero-shot reports were ready without edits.
This suggests the Reflexion framework provides a feasible way to efficiently generate patient-friendly medical reports that maintain medical accuracy, reducing the need for human review and editing. The researchers have made their code available online for others to build on this work.
Technical Explanation
The paper proposes a multi-agent "agentic workflow" using the Reflexion framework to generate patient-friendly versions of formal medical reports from LLMs. This approach has the LLM iteratively reflect on and refine its own output, rather than relying on a single pass.
The researchers tested this pipeline on 16 randomized radiology reports, comparing it to a zero-shot prompting approach. In the multi-agent Reflexion workflow, reports had a 94.94% accuracy rate in verifying ICD-10 codes, compared to 68.23% for zero-shot prompting.
Additionally, 81.25% of the final Reflexion-based reports required no corrections for accuracy or readability, while only 25% of the zero-shot reports met these criteria without needing modifications.
These results indicate the Reflexion-based approach can effectively generate patient-friendly medical communications that maintain medical accuracy, reducing the need for human review and editing compared to standard LLM prompting.
Critical Analysis
The paper provides a promising approach for using LLMs to communicate complex medical information to patients in an accessible way. The Reflexion framework's use of iterative self-reflection appears to significantly improve the accuracy and coherence of the LLM's outputs compared to a single-pass zero-shot approach.
However, the paper does not address some potential limitations or areas for further research. For example, it only evaluates the approach on 16 radiology reports, so more extensive testing would be needed to validate the findings across a wider range of medical domains and report types.
Additionally, the paper does not explore how well the patient-friendly reports would actually be understood by lay readers. While the accuracy and readability metrics are encouraging, real-world user testing with patients would be valuable to ensure the LLM-generated reports are truly meeting their needs.
Further research could also investigate how the Reflexion workflow could be extended or combined with other techniques, such as XAI methods, to provide even greater transparency and user trust in the LLM's reasoning process.
Overall, this paper presents a compelling direction for leveraging Large Language Models in healthcare summarization, but additional validation and exploration of the approach would help strengthen the conclusions.
Conclusion
This paper introduces an innovative "agentic workflow" using the Reflexion framework to improve the ability of Large Language Models to generate patient-friendly versions of formal medical reports. By having the LLM iteratively self-reflect and refine its outputs, the approach demonstrated significantly higher accuracy and readability compared to a standard zero-shot prompting method.
The results suggest this Reflexion-based approach could provide an efficient way to communicate clinical findings to patients while maintaining medical precision. This has important implications for improving patient engagement and understanding of their own healthcare, which can lead to better health outcomes.
The researchers have made their code publicly available, allowing others to build upon and further validate this work. Continued research in this area has the potential to unlock new capabilities for Large Language Models to serve as collaborative partners with healthcare providers in delivering clear, effective patient communications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Agentic LLM Workflows for Generating Patient-Friendly Medical Reports
Malavikha Sudarshan, Sophie Shih, Estella Yee, Alina Yang, John Zou, Cathy Chen, Quan Zhou, Leon Chen, Chinmay Singhal, George Shih
The application of Large Language Models (LLMs) in healthcare is expanding rapidly, with one potential use case being the translation of formal medical reports into patient-legible equivalents. Currently, LLM outputs often need to be edited and evaluated by a human to ensure both factual accuracy and comprehensibility, and this is true for the above use case. We aim to minimize this step by proposing an agentic workflow with the Reflexion framework, which uses iterative self-reflection to correct outputs from an LLM. This pipeline was tested and compared to zero-shot prompting on 16 randomized radiology reports. In our multi-agent approach, reports had an accuracy rate of 94.94% when looking at verification of ICD-10 codes, compared to zero-shot prompted reports, which had an accuracy rate of 68.23%. Additionally, 81.25% of the final reflected reports required no corrections for accuracy or readability, while only 25% of zero-shot prompted reports met these criteria without needing modifications. These results indicate that our approach presents a feasible method for communicating clinical findings to patients in a quick, efficient and coherent manner whilst also retaining medical accuracy. The codebase is available for viewing at http://github.com/malavikhasudarshan/Multi-Agent-Patient-Letter-Generation.
Read more8/6/2024
🌀
0
Exploring LLM Multi-Agents for ICD Coding
Rumeng Li, Xun Wang, Hong Yu
To address the limitations of Large Language Models (LLMs) in the International Classification of Diseases (ICD) coding task, where they often produce inaccurate and incomplete prediction results due to the high-dimensional and skewed distribution of the ICD codes, and often lack interpretability and reliability as well. We introduce an innovative multi-agent approach for ICD coding which mimics the ICD coding assignment procedure in real-world settings, comprising five distinct agents: the patient, physician, coder, reviewer, and adjuster. Each agent utilizes an LLM-based model tailored to their specific role within the coding process. We also integrate the system with Electronic Health Record (HER)'s SOAP (subjective, objective, assessment and plan) structure to boost the performances. We compare our method with a system of agents designed solely by LLMs and other strong baselines and evaluate it using the Medical Information Mart for Intensive Care III (MIMIC-III) dataset. Our multi-agent coding framework significantly outperforms Zero-shot Chain of Thought (CoT) prompting and self-consistency with CoT (CoT-SC) in coding common and rare ICD codes. An ablation study validates the effectiveness of the designated agent roles. it also outperforms the LLM-designed agent system. Moreover, our method achieves comparable results to state-of-the-art ICD coding methods that require extensive pre-training or fine-tuning, and outperforms them in rare code accuracy, and explainability. Additionally, we demonstrate the method's practical applicability by presenting its performance in scenarios not limited by the common or rare ICD code constraints.The proposed multi-agent method for ICD coding effectively mimics the real-world coding process and improves performance on both common and rare codes.
Read more8/15/2024
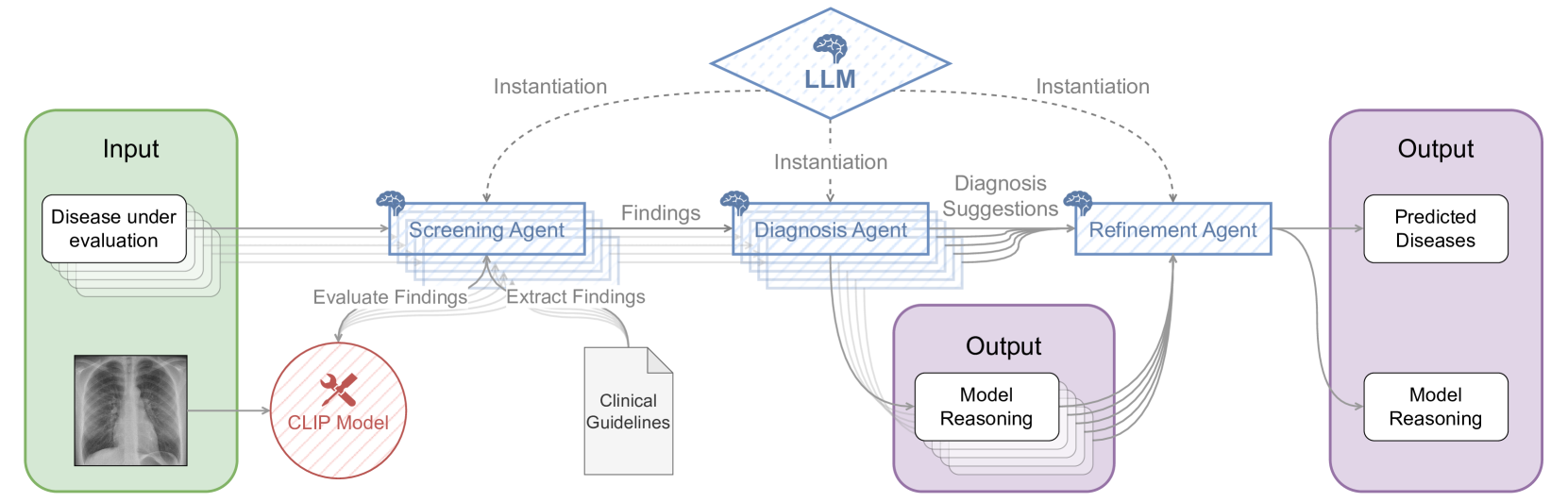
0
MAGDA: Multi-agent guideline-driven diagnostic assistance
David Bani-Harouni, Nassir Navab, Matthias Keicher
In emergency departments, rural hospitals, or clinics in less developed regions, clinicians often lack fast image analysis by trained radiologists, which can have a detrimental effect on patients' healthcare. Large Language Models (LLMs) have the potential to alleviate some pressure from these clinicians by providing insights that can help them in their decision-making. While these LLMs achieve high test results on medical exams showcasing their great theoretical medical knowledge, they tend not to follow medical guidelines. In this work, we introduce a new approach for zero-shot guideline-driven decision support. We model a system of multiple LLM agents augmented with a contrastive vision-language model that collaborate to reach a patient diagnosis. After providing the agents with simple diagnostic guidelines, they will synthesize prompts and screen the image for findings following these guidelines. Finally, they provide understandable chain-of-thought reasoning for their diagnosis, which is then self-refined to consider inter-dependencies between diseases. As our method is zero-shot, it is adaptable to settings with rare diseases, where training data is limited, but expert-crafted disease descriptions are available. We evaluate our method on two chest X-ray datasets, CheXpert and ChestX-ray 14 Longtail, showcasing performance improvement over existing zero-shot methods and generalizability to rare diseases.
Read more9/11/2024
💬
0
MedAgents: Large Language Models as Collaborators for Zero-shot Medical Reasoning
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, Mark Gerstein
Large language models (LLMs), despite their remarkable progress across various general domains, encounter significant barriers in medicine and healthcare. This field faces unique challenges such as domain-specific terminologies and reasoning over specialized knowledge. To address these issues, we propose MedAgents, a novel multi-disciplinary collaboration framework for the medical domain. MedAgents leverages LLM-based agents in a role-playing setting that participate in a collaborative multi-round discussion, thereby enhancing LLM proficiency and reasoning capabilities. This training-free framework encompasses five critical steps: gathering domain experts, proposing individual analyses, summarising these analyses into a report, iterating over discussions until a consensus is reached, and ultimately making a decision. Our work focuses on the zero-shot setting, which is applicable in real-world scenarios. Experimental results on nine datasets (MedQA, MedMCQA, PubMedQA, and six subtasks from MMLU) establish that our proposed MedAgents framework excels at mining and harnessing the medical expertise within LLMs, as well as extending its reasoning abilities. Our code can be found at https://github.com/gersteinlab/MedAgents.
Read more6/6/2024