An Aggregation-Free Federated Learning for Tackling Data Heterogeneity
2404.18962
0
0

Abstract
The performance of Federated Learning (FL) hinges on the effectiveness of utilizing knowledge from distributed datasets. Traditional FL methods adopt an aggregate-then-adapt framework, where clients update local models based on a global model aggregated by the server from the previous training round. This process can cause client drift, especially with significant cross-client data heterogeneity, impacting model performance and convergence of the FL algorithm. To address these challenges, we introduce FedAF, a novel aggregation-free FL algorithm. In this framework, clients collaboratively learn condensed data by leveraging peer knowledge, the server subsequently trains the global model using the condensed data and soft labels received from the clients. FedAF inherently avoids the issue of client drift, enhances the quality of condensed data amid notable data heterogeneity, and improves the global model performance. Extensive numerical studies on several popular benchmark datasets show FedAF surpasses various state-of-the-art FL algorithms in handling label-skew and feature-skew data heterogeneity, leading to superior global model accuracy and faster convergence.
Create account to get full access
Overview
- This paper proposes a new federated learning approach called Aggregation-Free Federated Learning (AFFL) to address the challenge of data heterogeneity across different clients.
- AFFL avoids the need for model aggregation, which is a common bottleneck in traditional federated learning approaches.
- The key idea is to train separate sub-models on each client, which are then combined at the server-side to form the final model.
Plain English Explanation
The paper describes a new way of doing federated learning, which is a technique for training machine learning models across multiple devices or clients without sharing the raw data. Traditional federated learning approaches often struggle when the data on each device is very different (known as "data heterogeneity").
The new method, called Aggregation-Free Federated Learning (AFFL), avoids the need to combine or "aggregate" the models from each device. Instead, AFFL trains separate sub-models on each device, and then combines these sub-models at the central server to form the final model. This helps overcome the challenges posed by data heterogeneity, as the sub-models can specialize to the unique data on each device.
The key advantage of AFFL is that it removes the need for the costly and often problematic model aggregation step that is common in other federated learning approaches. This can make the overall system more efficient and robust to issues caused by data differences across devices.
Technical Explanation
The paper introduces Aggregation-Free Federated Learning (AFFL), a novel federated learning framework that aims to tackle the challenge of data heterogeneity across clients.
Unlike traditional federated learning approaches that rely on aggregating model updates from clients, AFFL trains separate sub-models on each client. These sub-models are then combined at the server-side to form the final model. This avoids the need for the model aggregation step, which can be a significant bottleneck in federated learning due to issues like client drift and communication constraints.
The AFFL framework consists of three key components:
-
Sub-model Training: Each client trains a unique sub-model based on its local data. This allows the sub-models to specialize to the heterogeneous data distributions on different clients.
-
Sub-model Combination: The server combines the sub-models received from clients to form the final global model. This combination step leverages techniques like knowledge distillation to effectively integrate the specialized sub-models.
-
Personalization: AFFL also supports personalized model fine-tuning on each client to further improve performance on the local data distributions.
The paper evaluates AFFL on several federated learning benchmarks and shows that it outperforms traditional federated learning approaches in terms of both model performance and communication efficiency, especially in the presence of significant data heterogeneity.
Critical Analysis
The paper presents a promising approach to address the data heterogeneity challenge in federated learning. By avoiding the need for model aggregation, AFFL can potentially overcome some of the key issues that plague traditional federated learning, such as client drift and communication bottlenecks.
However, the paper does not fully explore the limitations and tradeoffs of the AFFL approach. For example, the combination of sub-models at the server-side may introduce additional computation and storage overhead, which could be a concern for resource-constrained server environments.
Additionally, the paper does not delve into the potential privacy and security implications of the AFFL approach. Since the sub-models are shared with the server, there may be concerns around data leakage or model extraction attacks that need to be carefully considered.
Further research is needed to better understand the long-term implications of the AFFL approach, especially as it is deployed in real-world federated learning scenarios involving a large number of clients and diverse data distributions. Exploring techniques to improve the robustness and scalability of AFFL would also be valuable.
Conclusion
The Aggregation-Free Federated Learning (AFFL) approach presented in this paper offers a promising solution to the data heterogeneity challenge in federated learning. By training separate sub-models on each client and combining them at the server-side, AFFL can overcome the limitations of traditional federated learning methods that rely on model aggregation.
The key innovation of AFFL is its ability to leverage the specialized knowledge captured in the sub-models, while avoiding the issues associated with model aggregation. This can lead to improved model performance and communication efficiency, particularly in scenarios where the client data is highly heterogeneous.
While the paper provides a solid technical foundation for AFFL, further research is needed to fully understand its long-term implications and potential limitations. Nonetheless, the AFFL approach represents an important step forward in the field of federated learning, and its potential impacts on real-world applications are worth exploring further.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Robust Model Aggregation for Heterogeneous Federated Learning: Analysis and Optimizations
Yumeng Shao, Jun Li, Long Shi, Kang Wei, Ming Ding, Qianmu Li, Zengxiang Li, Wen Chen, Shi Jin
0
0
Conventional synchronous federated learning (SFL) frameworks suffer from performance degradation in heterogeneous systems due to imbalanced local data size and diverse computing power on the client side. To address this problem, asynchronous FL (AFL) and semi-asynchronous FL have been proposed to recover the performance loss by allowing asynchronous aggregation. However, asynchronous aggregation incurs a new problem of inconsistency between local updates and global updates. Motivated by the issues of conventional SFL and AFL, we first propose a time-driven SFL (T-SFL) framework for heterogeneous systems. The core idea of T-SFL is that the server aggregates the models from different clients, each with varying numbers of iterations, at regular time intervals. To evaluate the learning performance of T-SFL, we provide an upper bound on the global loss function. Further, we optimize the aggregation weights to minimize the developed upper bound. Then, we develop a discriminative model selection (DMS) algorithm that removes local models from clients whose number of iterations falls below a predetermined threshold. In particular, this algorithm ensures that each client's aggregation weight accurately reflects its true contribution to the global model update, thereby improving the efficiency and robustness of the system. To validate the effectiveness of T-SFL with the DMS algorithm, we conduct extensive experiments using several popular datasets including MNIST, Cifar-10, Fashion-MNIST, and SVHN. The experimental results demonstrate that T-SFL with the DMS algorithm can reduce the latency of conventional SFL by 50%, while achieving an average 3% improvement in learning accuracy over state-of-the-art AFL algorithms.
5/14/2024

FedAC: An Adaptive Clustered Federated Learning Framework for Heterogeneous Data
Yuxin Zhang, Haoyu Chen, Zheng Lin, Zhe Chen, Jin Zhao
0
0
Clustered federated learning (CFL) is proposed to mitigate the performance deterioration stemming from data heterogeneity in federated learning (FL) by grouping similar clients for cluster-wise model training. However, current CFL methods struggle due to inadequate integration of global and intra-cluster knowledge and the absence of an efficient online model similarity metric, while treating the cluster count as a fixed hyperparameter limits flexibility and robustness. In this paper, we propose an adaptive CFL framework, named FedAC, which (1) efficiently integrates global knowledge into intra-cluster learning by decoupling neural networks and utilizing distinct aggregation methods for each submodule, significantly enhancing performance; (2) includes a costeffective online model similarity metric based on dimensionality reduction; (3) incorporates a cluster number fine-tuning module for improved adaptability and scalability in complex, heterogeneous environments. Extensive experiments show that FedAC achieves superior empirical performance, increasing the test accuracy by around 1.82% and 12.67% on CIFAR-10 and CIFAR-100 datasets, respectively, under different non-IID settings compared to SOTA methods.
4/1/2024
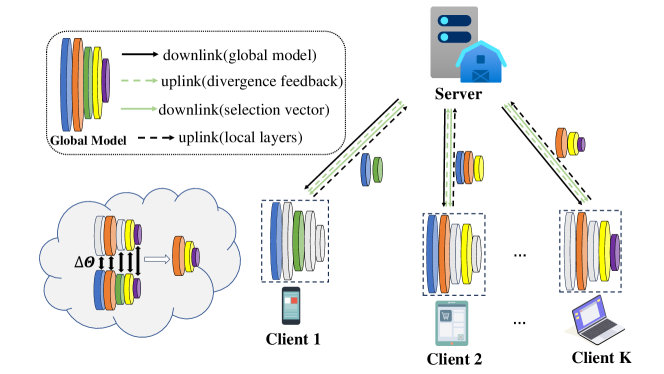
Communication-Efficient Model Aggregation with Layer Divergence Feedback in Federated Learning
Liwei Wang, Jun Li, Wen Chen, Qingqing Wu, Ming Ding
0
0
Federated Learning (FL) facilitates collaborative machine learning by training models on local datasets, and subsequently aggregating these local models at a central server. However, the frequent exchange of model parameters between clients and the central server can result in significant communication overhead during the FL training process. To solve this problem, this paper proposes a novel FL framework, the Model Aggregation with Layer Divergence Feedback mechanism (FedLDF). Specifically, we calculate model divergence between the local model and the global model from the previous round. Then through model layer divergence feedback, the distinct layers of each client are uploaded and the amount of data transferred is reduced effectively. Moreover, the convergence bound reveals that the access ratio of clients has a positive correlation with model performance. Simulation results show that our algorithm uploads local models with reduced communication overhead while upholding a superior global model performance.
4/15/2024
🤯
Analytic Federated Learning
Huiping Zhuang, Run He, Kai Tong, Di Fang, Han Sun, Haoran Li, Tianyi Chen, Ziqian Zeng
0
0
In this paper, we introduce analytic federated learning (AFL), a new training paradigm that brings analytical (i.e., closed-form) solutions to the federated learning (FL) community. Our AFL draws inspiration from analytic learning -- a gradient-free technique that trains neural networks with analytical solutions in one epoch. In the local client training stage, the AFL facilitates a one-epoch training, eliminating the necessity for multi-epoch updates. In the aggregation stage, we derive an absolute aggregation (AA) law. This AA law allows a single-round aggregation, removing the need for multiple aggregation rounds. More importantly, the AFL exhibits a textit{weight-invariant} property, meaning that regardless of how the full dataset is distributed among clients, the aggregated result remains identical. This could spawn various potentials, such as data heterogeneity invariance, client-number invariance, absolute convergence, and being hyperparameter-free (our AFL is the first hyperparameter-free method in FL history). We conduct experiments across various FL settings including extremely non-IID ones, and scenarios with a large number of clients (e.g., $ge 1000$). In all these settings, our AFL constantly performs competitively while existing FL techniques encounter various obstacles. Code is available at url{https://github.com/ZHUANGHP/Analytic-federated-learning}
5/28/2024