FedAC: An Adaptive Clustered Federated Learning Framework for Heterogeneous Data
2403.16460
0
0

Abstract
Clustered federated learning (CFL) is proposed to mitigate the performance deterioration stemming from data heterogeneity in federated learning (FL) by grouping similar clients for cluster-wise model training. However, current CFL methods struggle due to inadequate integration of global and intra-cluster knowledge and the absence of an efficient online model similarity metric, while treating the cluster count as a fixed hyperparameter limits flexibility and robustness. In this paper, we propose an adaptive CFL framework, named FedAC, which (1) efficiently integrates global knowledge into intra-cluster learning by decoupling neural networks and utilizing distinct aggregation methods for each submodule, significantly enhancing performance; (2) includes a costeffective online model similarity metric based on dimensionality reduction; (3) incorporates a cluster number fine-tuning module for improved adaptability and scalability in complex, heterogeneous environments. Extensive experiments show that FedAC achieves superior empirical performance, increasing the test accuracy by around 1.82% and 12.67% on CIFAR-10 and CIFAR-100 datasets, respectively, under different non-IID settings compared to SOTA methods.
Create account to get full access
Overview
- This paper proposes FedAC, a federated learning framework that adaptively clusters clients to address the challenge of heterogeneous data in federated learning.
- FedAC leverages multi-task learning and model similarity to group clients with similar data distributions, improving the overall model performance.
- The framework dynamically adjusts the client clusters throughout the training process to adapt to changing data distributions.
Plain English Explanation
Federated learning is a way for multiple devices or organizations to train a shared machine learning model without sharing their local data. This is useful when the data is sensitive or distributed across many locations. However, a key challenge in federated learning is that the data on different devices can be quite different, making it hard to train a single effective model.
FedAC addresses this by automatically grouping or "clustering" devices with similar data distributions. This allows the model to be customized for each cluster, rather than trying to fit a one-size-fits-all model. The framework also dynamically updates these clusters as the data changes over time.
The core idea is to use multi-task learning, where a shared "backbone" model is trained alongside cluster-specific "heads." The backbone learns general features, while the heads specialize the model for each cluster. FedAC also measures the similarity between model parameters to determine which clients should be grouped together.
By adaptively clustering clients and customizing the model for each group, FedAC can achieve higher overall performance compared to standard federated learning approaches, especially when the data is quite different across clients.
Technical Explanation
The key technical components of FedAC are:
-
Adaptive Clustering: FedAC dynamically groups clients into clusters based on the similarity of their local data distributions. This is done by measuring the similarity between the model parameters learned by each client.
-
Multi-Task Learning: FedAC uses a multi-task learning approach, where a shared "backbone" model is trained alongside cluster-specific "head" models. This allows the model to learn general features while also specializing for each client cluster.
-
Similarity-Aware Aggregation: When aggregating model updates from clients, FedAC weighs the updates from each client based on their model similarity to the global model. This helps to improve the convergence and robustness of the federated training process.
The authors evaluate FedAC on several benchmark datasets and show that it outperforms standard federated learning approaches, especially when the data is highly heterogeneous across clients. FedAC is able to achieve this by effectively adapting the model to the diverse data distributions present in the federated setting.
Critical Analysis
The paper provides a comprehensive technical description of the FedAC framework and demonstrates its effectiveness through thorough experimentation. However, a few potential limitations and areas for future research are worth considering:
-
Generalization to More Complex Datasets: The experiments in the paper focus on relatively simple image classification tasks. It would be valuable to see how well FedAC performs on more complex, real-world datasets, such as those encountered in federated load forecasting or federated healthcare applications.
-
Computational and Communication Overhead: Adaptively clustering clients and maintaining separate head models for each cluster may introduce additional computational and communication overhead compared to standard federated learning approaches. The authors could investigate ways to mitigate these costs while preserving the performance benefits of FedAC.
-
Robustness to Adversarial Attacks: The paper does not address the potential vulnerabilities of FedAC to adversarial attacks that may target the clustering or aggregation mechanisms. Analyzing the robustness of FedAC in such scenarios would be a valuable addition to the research.
Overall, FedAC represents an interesting and promising approach to addressing heterogeneity in federated learning, and the paper provides a solid technical foundation for further research and development in this area.
Conclusion
The FedAC framework proposed in this paper addresses a key challenge in federated learning: the presence of heterogeneous data distributions across clients. By adaptively clustering clients based on model similarity and using a multi-task learning approach, FedAC is able to achieve higher overall performance compared to standard federated learning methods.
The technical contributions of the paper, including the adaptive clustering algorithm and the similarity-aware aggregation strategy, demonstrate the potential of FedAC to enable more effective federated learning in a wide range of applications, from healthcare to edge computing. As the field of federated learning continues to evolve, frameworks like FedAC will play an important role in unlocking the full potential of this distributed learning paradigm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Aggregation-Free Federated Learning for Tackling Data Heterogeneity
Yuan Wang, Huazhu Fu, Renuga Kanagavelu, Qingsong Wei, Yong Liu, Rick Siow Mong Goh
0
0
The performance of Federated Learning (FL) hinges on the effectiveness of utilizing knowledge from distributed datasets. Traditional FL methods adopt an aggregate-then-adapt framework, where clients update local models based on a global model aggregated by the server from the previous training round. This process can cause client drift, especially with significant cross-client data heterogeneity, impacting model performance and convergence of the FL algorithm. To address these challenges, we introduce FedAF, a novel aggregation-free FL algorithm. In this framework, clients collaboratively learn condensed data by leveraging peer knowledge, the server subsequently trains the global model using the condensed data and soft labels received from the clients. FedAF inherently avoids the issue of client drift, enhances the quality of condensed data amid notable data heterogeneity, and improves the global model performance. Extensive numerical studies on several popular benchmark datasets show FedAF surpasses various state-of-the-art FL algorithms in handling label-skew and feature-skew data heterogeneity, leading to superior global model accuracy and faster convergence.
5/1/2024

FedCAda: Adaptive Client-Side Optimization for Accelerated and Stable Federated Learning
Liuzhi Zhou, Yu He, Kun Zhai, Xiang Liu, Sen Liu, Xingjun Ma, Guangnan Ye, Yu-Gang Jiang, Hongfeng Chai
0
0
Federated learning (FL) has emerged as a prominent approach for collaborative training of machine learning models across distributed clients while preserving data privacy. However, the quest to balance acceleration and stability becomes a significant challenge in FL, especially on the client-side. In this paper, we introduce FedCAda, an innovative federated client adaptive algorithm designed to tackle this challenge. FedCAda leverages the Adam algorithm to adjust the correction process of the first moment estimate $m$ and the second moment estimate $v$ on the client-side and aggregate adaptive algorithm parameters on the server-side, aiming to accelerate convergence speed and communication efficiency while ensuring stability and performance. Additionally, we investigate several algorithms incorporating different adjustment functions. This comparative analysis revealed that due to the limited information contained within client models from other clients during the initial stages of federated learning, more substantial constraints need to be imposed on the parameters of the adaptive algorithm. As federated learning progresses and clients gather more global information, FedCAda gradually diminishes the impact on adaptive parameters. These findings provide insights for enhancing the robustness and efficiency of algorithmic improvements. Through extensive experiments on computer vision (CV) and natural language processing (NLP) datasets, we demonstrate that FedCAda outperforms the state-of-the-art methods in terms of adaptability, convergence, stability, and overall performance. This work contributes to adaptive algorithms for federated learning, encouraging further exploration.
5/21/2024
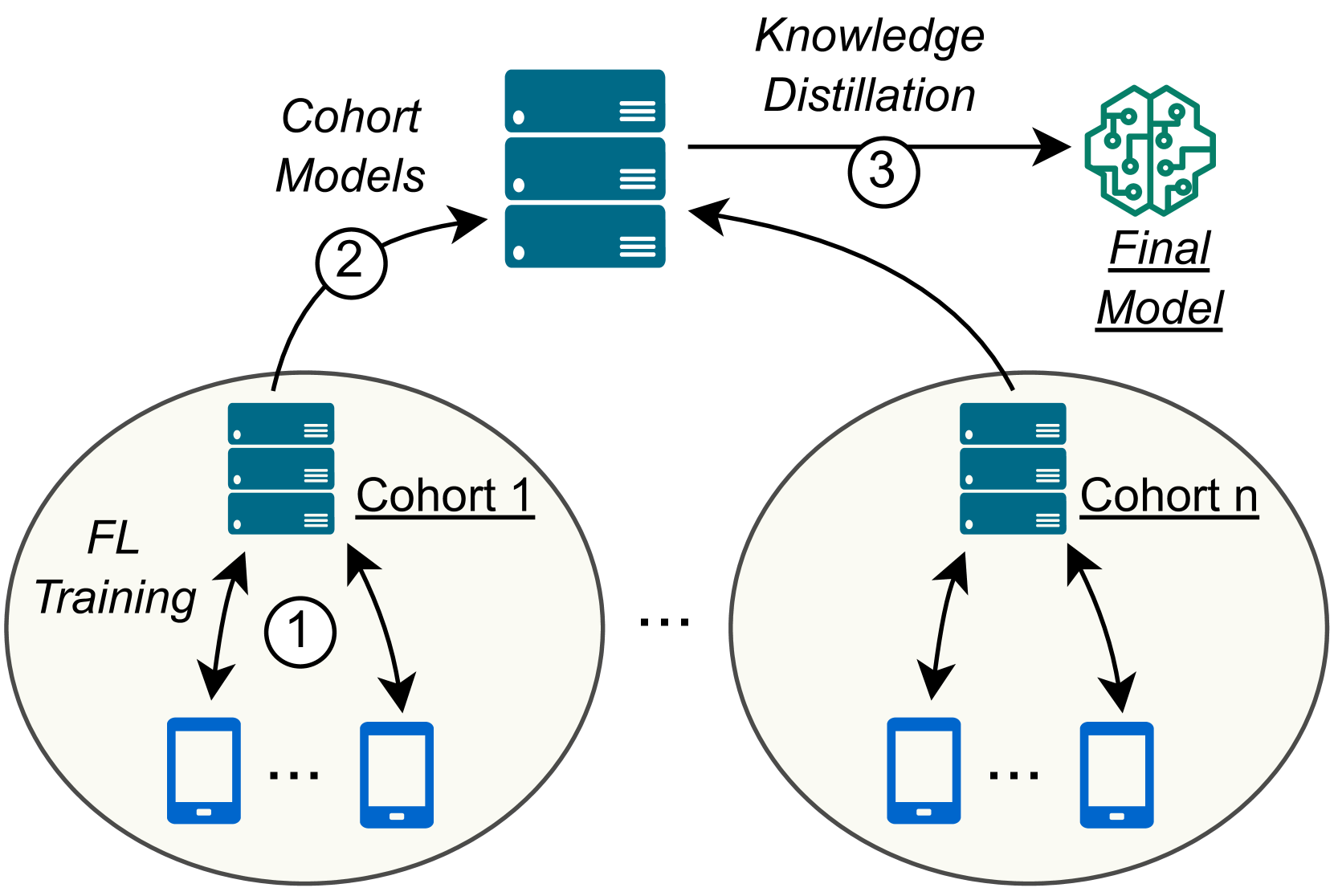
Harnessing Increased Client Participation with Cohort-Parallel Federated Learning
Akash Dhasade, Anne-Marie Kermarrec, Tuan-Anh Nguyen, Rafael Pires, Martijn de Vos
0
0
Federated Learning (FL) is a machine learning approach where nodes collaboratively train a global model. As more nodes participate in a round of FL, the effectiveness of individual model updates by nodes also diminishes. In this study, we increase the effectiveness of client updates by dividing the network into smaller partitions, or cohorts. We introduce Cohort-Parallel Federated Learning (CPFL): a novel learning approach where each cohort independently trains a global model using FL, until convergence, and the produced models by each cohort are then unified using one-shot Knowledge Distillation (KD) and a cross-domain, unlabeled dataset. The insight behind CPFL is that smaller, isolated networks converge quicker than in a one-network setting where all nodes participate. Through exhaustive experiments involving realistic traces and non-IID data distributions on the CIFAR-10 and FEMNIST image classification tasks, we investigate the balance between the number of cohorts, model accuracy, training time, and compute and communication resources. Compared to traditional FL, CPFL with four cohorts, non-IID data distribution, and CIFAR-10 yields a 1.9$times$ reduction in train time and a 1.3$times$ reduction in resource usage, with a minimal drop in test accuracy.
5/27/2024
🔗
FedRC: Tackling Diverse Distribution Shifts Challenge in Federated Learning by Robust Clustering
Yongxin Guo, Xiaoying Tang, Tao Lin
0
0
Federated Learning (FL) is a machine learning paradigm that safeguards privacy by retaining client data on edge devices. However, optimizing FL in practice can be challenging due to the diverse and heterogeneous nature of the learning system. Though recent research has focused on improving the optimization of FL when distribution shifts occur among clients, ensuring global performance when multiple types of distribution shifts occur simultaneously among clients -- such as feature distribution shift, label distribution shift, and concept shift -- remain under-explored. In this paper, we identify the learning challenges posed by the simultaneous occurrence of diverse distribution shifts and propose a clustering principle to overcome these challenges. Through our research, we find that existing methods fail to address the clustering principle. Therefore, we propose a novel clustering algorithm framework, dubbed as FedRC, which adheres to our proposed clustering principle by incorporating a bi-level optimization problem and a novel objective function. Extensive experiments demonstrate that FedRC significantly outperforms other SOTA cluster-based FL methods. Our code is available at url{https://github.com/LINs-lab/FedRC}.
6/11/2024