Communication-Efficient Model Aggregation with Layer Divergence Feedback in Federated Learning
2404.08324
0
0
Abstract
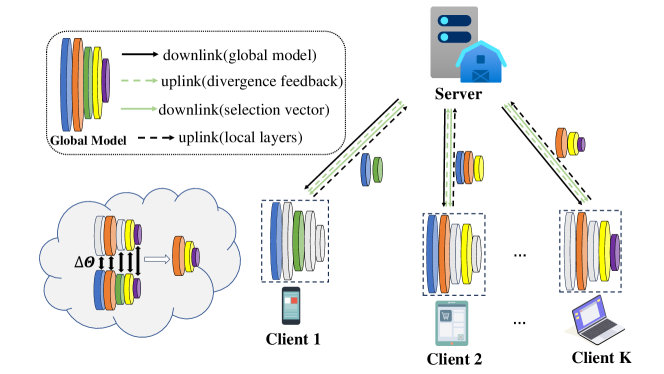
Federated Learning (FL) facilitates collaborative machine learning by training models on local datasets, and subsequently aggregating these local models at a central server. However, the frequent exchange of model parameters between clients and the central server can result in significant communication overhead during the FL training process. To solve this problem, this paper proposes a novel FL framework, the Model Aggregation with Layer Divergence Feedback mechanism (FedLDF). Specifically, we calculate model divergence between the local model and the global model from the previous round. Then through model layer divergence feedback, the distinct layers of each client are uploaded and the amount of data transferred is reduced effectively. Moreover, the convergence bound reveals that the access ratio of clients has a positive correlation with model performance. Simulation results show that our algorithm uploads local models with reduced communication overhead while upholding a superior global model performance.
Create account to get full access
Overview
- Federated learning, a distributed machine learning approach, aims to train AI models on decentralized data without sharing the raw data.
- This paper proposes a communication-efficient model aggregation technique called "Layer Divergence Feedback" (LDF) to improve the performance of federated learning systems.
- LDF selectively aggregates model updates, focusing on the layers with the highest divergence between the local and global models, to reduce the communication overhead while maintaining model accuracy.
Plain English Explanation
Federated learning is a way of training AI models without sharing the raw data directly. Instead of sending all the data to a central server, each device (like a smartphone) trains the model on its own data and only sends the model updates to the server. This helps protect the privacy of the data.
The paper introduces a new technique called "Layer Divergence Feedback" (LDF) to make this federated learning process more efficient. LDF looks at how much the model on each device differs from the overall global model. It then focuses on aggregating (or combining) only the parts of the model that have changed the most, rather than sending all the model updates. This reduces the amount of communication needed between the devices and the server, making the whole process faster and more efficient.
The key idea is that by selectively aggregating the most important model updates, LDF can maintain the accuracy of the final model while using less communication bandwidth. This could be especially useful in situations where the devices have limited network connectivity, like in rural areas or during emergencies.
Technical Explanation
The paper proposes a communication-efficient model aggregation technique called "Layer Divergence Feedback" (LDF) for federated learning. LDF selectively aggregates model updates based on the divergence between the local and global models at each layer.
Specifically, LDF works as follows:
- Each client trains its local model on its private data and computes the model updates.
- The client evaluates the divergence between its local model and the global model for each layer.
- The client then sends only the updates for the layers with the highest divergence to the server.
- The server aggregates these selective updates to update the global model.
This selective aggregation approach reduces the communication overhead compared to traditional federated learning, which sends all model updates. The paper provides a theoretical analysis to show that LDF can achieve the same convergence guarantees as full aggregation, while significantly reducing the communication cost.
The authors evaluate LDF empirically on several federated learning benchmarks, including link to "Federated Aggregation: Adaptive Federated Learning with Layer-Wise Selective Aggregation", link to "A Survey of Federated Distillation and Beyond", and link to "Conquering Communication Constraints to Enable Large-Scale Federated Learning". The results show that LDF can significantly reduce the communication cost while maintaining model performance comparable to full aggregation.
Critical Analysis
The proposed LDF technique addresses an important challenge in federated learning - reducing the communication overhead while preserving model accuracy. By selectively aggregating only the most important model updates, LDF can potentially enable federated learning in scenarios with limited network bandwidth or connectivity, as mentioned in the paper.
However, the paper does not discuss the potential impact of this selective aggregation on model robustness or federated learning in the presence of non-i.i.d. (non-independent and identically distributed) data, which is a common challenge in federated learning. It would be valuable to see an analysis of how LDF performs in these more realistic and challenging federated learning settings.
Additionally, the paper focuses on the convergence analysis and empirical evaluation of LDF, but does not provide much insight into the underlying reasons why certain layers exhibit higher divergence than others. Understanding these dynamics could lead to further improvements in the selective aggregation strategy.
Overall, the LDF technique presented in this paper is a promising step towards more communication-efficient federated learning, but further research is needed to fully understand its limitations and potential extensions.
Conclusion
This paper introduces a communication-efficient model aggregation technique called "Layer Divergence Feedback" (LDF) for federated learning. LDF selectively aggregates model updates based on the divergence between the local and global models at each layer, reducing the overall communication overhead while maintaining model performance.
The theoretical analysis and empirical evaluations demonstrate the effectiveness of LDF in improving the communication efficiency of federated learning, which could enable its deployment in scenarios with limited network resources. However, the paper also highlights the need for further research to address the impact of LDF on model robustness and performance in more challenging federated learning settings.
As federated learning continues to gain traction in various applications, techniques like LDF that balance communication efficiency and model accuracy will be crucial for the widespread adoption of this privacy-preserving machine learning paradigm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Efficient Model Compression for Hierarchical Federated Learning
Xi Zhu, Songcan Yu, Junbo Wang, Qinglin Yang
0
0
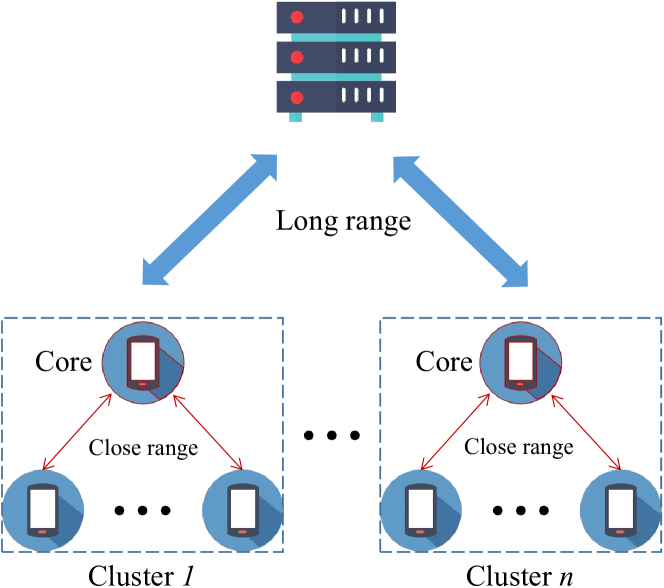
Federated learning (FL), as an emerging collaborative learning paradigm, has garnered significant attention due to its capacity to preserve privacy within distributed learning systems. In these systems, clients collaboratively train a unified neural network model using their local datasets and share model parameters rather than raw data, enhancing privacy. Predominantly, FL systems are designed for mobile and edge computing environments where training typically occurs over wireless networks. Consequently, as model sizes increase, the conventional FL frameworks increasingly consume substantial communication resources. To address this challenge and improve communication efficiency, this paper introduces a novel hierarchical FL framework that integrates the benefits of clustered FL and model compression. We present an adaptive clustering algorithm that identifies a core client and dynamically organizes clients into clusters. Furthermore, to enhance transmission efficiency, each core client implements a local aggregation with compression (LC aggregation) algorithm after collecting compressed models from other clients within the same cluster. Simulation results affirm that our proposed algorithms not only maintain comparable predictive accuracy but also significantly reduce energy consumption relative to existing FL mechanisms.
5/29/2024

An Aggregation-Free Federated Learning for Tackling Data Heterogeneity
Yuan Wang, Huazhu Fu, Renuga Kanagavelu, Qingsong Wei, Yong Liu, Rick Siow Mong Goh
0
0
The performance of Federated Learning (FL) hinges on the effectiveness of utilizing knowledge from distributed datasets. Traditional FL methods adopt an aggregate-then-adapt framework, where clients update local models based on a global model aggregated by the server from the previous training round. This process can cause client drift, especially with significant cross-client data heterogeneity, impacting model performance and convergence of the FL algorithm. To address these challenges, we introduce FedAF, a novel aggregation-free FL algorithm. In this framework, clients collaboratively learn condensed data by leveraging peer knowledge, the server subsequently trains the global model using the condensed data and soft labels received from the clients. FedAF inherently avoids the issue of client drift, enhances the quality of condensed data amid notable data heterogeneity, and improves the global model performance. Extensive numerical studies on several popular benchmark datasets show FedAF surpasses various state-of-the-art FL algorithms in handling label-skew and feature-skew data heterogeneity, leading to superior global model accuracy and faster convergence.
5/1/2024
📈
Robust Model Aggregation for Heterogeneous Federated Learning: Analysis and Optimizations
Yumeng Shao, Jun Li, Long Shi, Kang Wei, Ming Ding, Qianmu Li, Zengxiang Li, Wen Chen, Shi Jin
0
0
Conventional synchronous federated learning (SFL) frameworks suffer from performance degradation in heterogeneous systems due to imbalanced local data size and diverse computing power on the client side. To address this problem, asynchronous FL (AFL) and semi-asynchronous FL have been proposed to recover the performance loss by allowing asynchronous aggregation. However, asynchronous aggregation incurs a new problem of inconsistency between local updates and global updates. Motivated by the issues of conventional SFL and AFL, we first propose a time-driven SFL (T-SFL) framework for heterogeneous systems. The core idea of T-SFL is that the server aggregates the models from different clients, each with varying numbers of iterations, at regular time intervals. To evaluate the learning performance of T-SFL, we provide an upper bound on the global loss function. Further, we optimize the aggregation weights to minimize the developed upper bound. Then, we develop a discriminative model selection (DMS) algorithm that removes local models from clients whose number of iterations falls below a predetermined threshold. In particular, this algorithm ensures that each client's aggregation weight accurately reflects its true contribution to the global model update, thereby improving the efficiency and robustness of the system. To validate the effectiveness of T-SFL with the DMS algorithm, we conduct extensive experiments using several popular datasets including MNIST, Cifar-10, Fashion-MNIST, and SVHN. The experimental results demonstrate that T-SFL with the DMS algorithm can reduce the latency of conventional SFL by 50%, while achieving an average 3% improvement in learning accuracy over state-of-the-art AFL algorithms.
5/14/2024
🔮
FedAgg: Adaptive Federated Learning with Aggregated Gradients
Wenhao Yuan, Xuehe Wang
0
0
Federated Learning (FL) has emerged as a pivotal paradigm within distributed model training, facilitating collaboration among multiple devices to refine a shared model, harnessing their respective datasets as orchestrated by a central server, while ensuring the localization of private data. Nonetheless, the non-independent-and-identically-distributed (Non-IID) data generated on heterogeneous clients and the incessant information exchange among participants may markedly impede training efficacy and retard the convergence rate. In this paper, we refine the conventional stochastic gradient descent (SGD) methodology by introducing aggregated gradients at each local training epoch and propose an adaptive learning rate iterative algorithm that concerns the divergence between local and average parameters. To surmount the obstacle that acquiring other clients' local information, we introduce the mean-field approach by leveraging two mean-field terms to approximately estimate the average local parameters and gradients over time in a manner that precludes the need for local information exchange among clients and design the decentralized adaptive learning rate for each client. Through meticulous theoretical analysis, we provide a robust convergence guarantee for our proposed algorithm and ensure its wide applicability. Our numerical experiments substantiate the superiority of our framework in comparison with existing state-of-the-art FL strategies for enhancing model performance and accelerating convergence rate under IID and Non-IID data distributions.
4/15/2024