Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models
2405.12939
2
0
💬
Abstract
Recent advancements in Chain-of-Thought prompting have facilitated significant breakthroughs for Large Language Models (LLMs) in complex reasoning tasks. Current research enhances the reasoning performance of LLMs by sampling multiple reasoning chains and ensembling based on the answer frequency. However, this approach fails in scenarios where the correct answers are in the minority. We identify this as a primary factor constraining the reasoning capabilities of LLMs, a limitation that cannot be resolved solely based on the predicted answers. To address this shortcoming, we introduce a hierarchical reasoning aggregation framework AoR (Aggregation of Reasoning), which selects answers based on the evaluation of reasoning chains. Additionally, AoR incorporates dynamic sampling, adjusting the number of reasoning chains in accordance with the complexity of the task. Experimental results on a series of complex reasoning tasks show that AoR outperforms prominent ensemble methods. Further analysis reveals that AoR not only adapts various LLMs but also achieves a superior performance ceiling when compared to current methods.
Create account to get full access
Overview
- Recent advancements in Chain-of-Thought prompting have led to significant breakthroughs for Large Language Models (LLMs) in complex reasoning tasks.
- Current ensemble methods that sample multiple reasoning chains and select answers based on frequency fail in scenarios where the correct answers are in the minority.
- The paper introduces a new framework called AoR (Aggregation of Reasoning) that selects answers based on the evaluation of reasoning chains rather than just the predicted answers.
- AoR also incorporates dynamic sampling, adjusting the number of reasoning chains based on the complexity of the task.
Plain English Explanation
The paper focuses on improving the reasoning capabilities of large language models (LLMs) - powerful AI systems that can understand and generate human-like text. Recent advancements in Chain-of-Thought prompting have helped LLMs perform better on complex reasoning tasks, where they need to break down a problem, think through multiple steps, and arrive at a conclusion.
However, the current approach of sampling multiple reasoning chains and selecting the answer that appears most often has a limitation - it doesn't work well when the correct answer is in the minority. Imagine a scenario where there are 10 possible answers, and the correct one is only chosen in 2 out of the 10 reasoning chains. The current methods would still pick the incorrect answer that appears more often.
To address this, the researchers introduce a new framework called AoR (Aggregation of Reasoning). Instead of just looking at the final answers, AoR evaluates the quality of the entire reasoning process behind each answer. It then selects the answer with the strongest underlying reasoning, even if that answer was in the minority. AoR also dynamically adjusts the number of reasoning chains it generates, depending on how complex the task is.
Through experiments on a variety of complex reasoning tasks, the researchers show that AoR outperforms other prominent ensemble methods. It not only works better with different types of LLMs, but it also achieves a higher overall performance ceiling compared to current approaches.
Technical Explanation
The paper introduces a hierarchical reasoning aggregation framework called AoR (Aggregation of Reasoning) to enhance the reasoning capabilities of Large Language Models (LLMs). The key innovation is that AoR selects answers based on the evaluation of the reasoning chains, rather than simply relying on the frequency of the predicted answers.
AoR works as follows:
- It generates multiple reasoning chains for a given input, using Chain-of-Thought prompting.
- It then evaluates the quality of each reasoning chain, considering factors like logical coherence and alignment with the task requirements.
- Finally, AoR selects the answer that is supported by the strongest reasoning chain, even if that answer was in the minority among the generated chains.
Additionally, AoR incorporates a dynamic sampling mechanism, which adjusts the number of reasoning chains based on the complexity of the task. This helps ensure that the framework generates an appropriate number of chains to accurately capture the underlying reasoning.
The researchers evaluate AoR on a diverse set of complex reasoning tasks, including numerical reasoning, multi-step problem-solving, and multi-level reasoning. The results show that AoR outperforms prominent ensemble methods, such as majority voting and answer frequency-based selection. Furthermore, the analysis reveals that AoR is able to adapt to various LLM architectures and achieves a superior performance ceiling compared to current approaches.
Critical Analysis
The paper presents a well-designed framework that addresses a key limitation of existing ensemble methods for complex reasoning tasks. By evaluating the reasoning chains rather than just the final answers, AoR is able to select the correct solution even when it is in the minority.
However, the paper does not delve into the specific criteria used for evaluating the reasoning chains. While the authors mention factors like logical coherence and alignment with the task, a more detailed explanation of the evaluation process would be helpful for understanding the inner workings of the framework.
Additionally, the paper could have explored the potential computational and memory overhead associated with generating and evaluating multiple reasoning chains, especially as the task complexity increases. This information would be valuable for understanding the practical limitations and trade-offs of the AoR approach.
Another area for further research could be the investigation of graph-based reasoning as an alternative or complementary approach to the hierarchical reasoning used in AoR. Combining different reasoning strategies may lead to even more robust and versatile LLM capabilities.
Overall, the paper presents a promising step forward in enhancing the reasoning abilities of large language models, and the AoR framework offers an intriguing solution to the shortcomings of current ensemble methods. Further exploration and refinement of the approach could yield valuable insights for the broader field of AI reasoning and problem-solving.
Conclusion
The paper introduces a novel framework called AoR (Aggregation of Reasoning) that addresses a key limitation of current ensemble methods for complex reasoning tasks with large language models (LLMs). By evaluating the reasoning chains underlying the predicted answers, rather than just the answers themselves, AoR is able to select the correct solution even when it is in the minority.
The experimental results demonstrate that AoR outperforms prominent ensemble techniques and achieves a superior performance ceiling across a variety of complex reasoning tasks. This work represents a significant advancement in enhancing the reasoning capabilities of LLMs, with potential implications for a wide range of real-world applications that require robust and reliable problem-solving abilities.
As the field of AI continues to push the boundaries of what is possible, frameworks like AoR will play an increasingly important role in unlocking the full potential of large language models and advancing the state of the art in machine reasoning and cognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

General Purpose Verification for Chain of Thought Prompting
Robert Vacareanu, Anurag Pratik, Evangelia Spiliopoulou, Zheng Qi, Giovanni Paolini, Neha Anna John, Jie Ma, Yassine Benajiba, Miguel Ballesteros
0
0
Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
5/2/2024
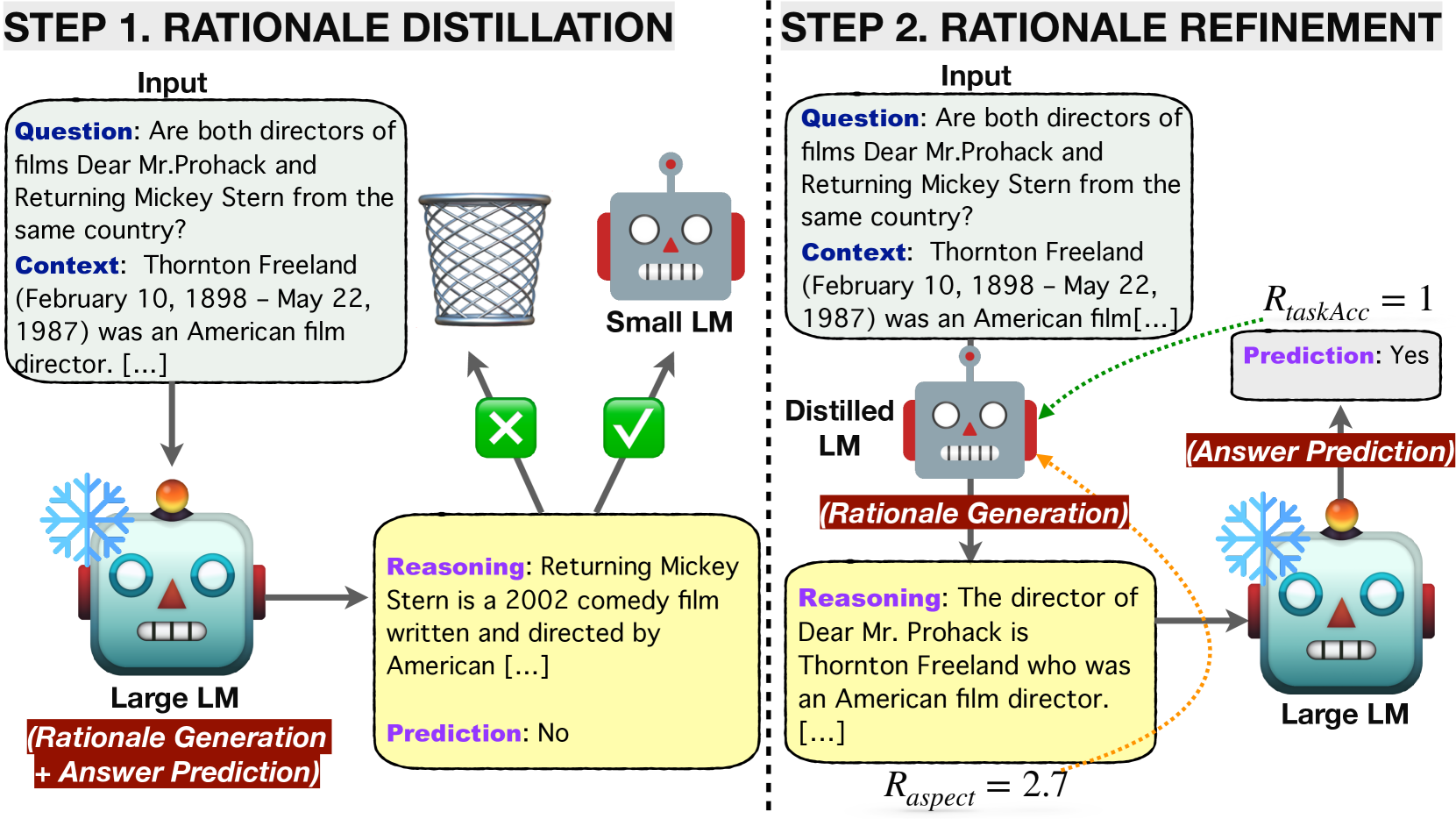
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024
💬
LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models
Shibo Hao, Yi Gu, Haotian Luo, Tianyang Liu, Xiyan Shao, Xinyuan Wang, Shuhua Xie, Haodi Ma, Adithya Samavedhi, Qiyue Gao, Zhen Wang, Zhiting Hu
0
0
Generating accurate step-by-step reasoning is essential for Large Language Models (LLMs) to address complex problems and enhance robustness and interpretability. Despite the flux of research on developing advanced reasoning approaches, systematically analyzing the diverse LLMs and reasoning strategies in generating reasoning chains remains a significant challenge. The difficulties stem from the lack of two key elements: (1) an automatic method for evaluating the generated reasoning chains on different tasks, and (2) a unified formalism and implementation of the diverse reasoning approaches for systematic comparison. This paper aims to close the gap: (1) We introduce AutoRace for fully automated reasoning chain evaluation. Existing metrics rely on expensive human annotations or pre-defined LLM prompts not adaptable to different tasks. In contrast, AutoRace automatically creates detailed evaluation criteria tailored for each task, and uses GPT-4 for accurate evaluation following the criteria. (2) We develop LLM Reasoners, a library for standardized modular implementation of existing and new reasoning algorithms, under a unified formulation of the search, reward, and world model components. With the new evaluation and library, (3) we conduct extensive study of different reasoning approaches (e.g., CoT, ToT, RAP). The analysis reveals interesting findings about different factors contributing to reasoning, including the reward-guidance, breadth-vs-depth in search, world model, and prompt formats, etc.
4/9/2024

CoTAR: Chain-of-Thought Attribution Reasoning with Multi-level Granularity
Moshe Berchansky, Daniel Fleischer, Moshe Wasserblat, Peter Izsak
0
0
State-of-the-art performance in QA tasks is currently achieved by systems employing Large Language Models (LLMs), however these models tend to hallucinate information in their responses. One approach focuses on enhancing the generation process by incorporating attribution from the given input to the output. However, the challenge of identifying appropriate attributions and verifying their accuracy against a source is a complex task that requires significant improvements in assessing such systems. We introduce an attribution-oriented Chain-of-Thought reasoning method to enhance the accuracy of attributions. This approach focuses the reasoning process on generating an attribution-centric output. Evaluations on two context-enhanced question-answering datasets using GPT-4 demonstrate improved accuracy and correctness of attributions. In addition, the combination of our method with finetuning enhances the response and attribution accuracy of two smaller LLMs, showing their potential to outperform GPT-4 in some cases.
4/17/2024