Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs
2404.07103
0
0
💬
Abstract
Large language models (LLMs), while exhibiting exceptional performance, suffer from hallucinations, especially on knowledge-intensive tasks. Existing works propose to augment LLMs with individual text units retrieved from external knowledge corpora to alleviate the issue. However, in many domains, texts are interconnected (e.g., academic papers in a bibliographic graph are linked by citations and co-authorships) which form a (text-attributed) graph. The knowledge in such graphs is encoded not only in single texts/nodes but also in their associated connections. To facilitate the research of augmenting LLMs with graphs, we manually construct a Graph Reasoning Benchmark dataset called GRBench, containing 1,740 questions that can be answered with the knowledge from 10 domain graphs. Then, we propose a simple and effective framework called Graph Chain-of-thought (Graph-CoT) to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. Each Graph-CoT iteration consists of three sub-steps: LLM reasoning, LLM-graph interaction, and graph execution. We conduct systematic experiments with three LLM backbones on GRBench, where Graph-CoT outperforms the baselines consistently. The code is available at https://github.com/PeterGriffinJin/Graph-CoT.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) often exhibit "hallucinations" or incorrect outputs, especially on tasks that require in-depth knowledge.
- Existing approaches try to address this by retrieving individual text units from external sources to augment the LLMs.
- However, in many domains, texts are interconnected (e.g., academic papers linked by citations and co-authorships), forming a graph structure.
- The knowledge in these graphs is encoded not only in individual texts/nodes, but also in the connections between them.
- To facilitate research on augmenting LLMs with graphs, the authors manually construct a Graph Reasoning Benchmark (GRBench) dataset with 1,740 questions that can be answered using knowledge from 10 domain graphs.
- They also propose a framework called Graph Chain-of-Thought (Graph-CoT) to enable LLMs to reason over these graph-structured knowledge sources.
Plain English Explanation
Large language models (LLMs) like GPT-3 and InstructGPT are incredibly powerful, but they can sometimes output incorrect or nonsensical information, especially on tasks that require in-depth knowledge. Researchers have tried to address this by giving the LLMs access to specific pieces of information from external sources, but this approach misses the bigger picture.
In many domains, like academic research, the information is actually organized in a graph structure, where individual texts (like papers) are connected to each other through citations, co-authorships, and other relationships. The knowledge in these graphs isn't just contained in the individual texts, but also in how they're linked together.
To help researchers study how to incorporate this graph-structured knowledge into LLMs, the authors of this paper created a new dataset called GRBench. GRBench contains 1,740 questions that can be answered using the information in 10 different domain-specific knowledge graphs. This gives researchers a way to test different approaches for augmenting LLMs with graphs.
The authors also propose a new framework called Graph Chain-of-Thought (Graph-CoT) that allows LLMs to reason about and traverse these knowledge graphs in a step-by-step fashion. This helps the LLMs better understand the interconnected nature of the information and, in turn, provide more accurate and informative responses.
Technical Explanation
The paper first highlights the issue of "hallucinations" in large language models (LLMs), where the models sometimes generate incorrect or nonsensical outputs, especially on knowledge-intensive tasks. Existing approaches have tried to address this by augmenting LLMs with individual text units retrieved from external knowledge sources.
However, the authors note that in many domains, the texts are interconnected, forming a graph structure (e.g., academic papers linked by citations and co-authorships). The knowledge in such graphs is encoded not only in the individual texts/nodes, but also in the connections between them.
To facilitate research on augmenting LLMs with graph-structured knowledge, the authors manually construct a Graph Reasoning Benchmark (GRBench) dataset. GRBench contains 1,740 questions that can be answered using the knowledge from 10 domain-specific knowledge graphs.
The authors then propose a framework called Graph Chain-of-Thought (Graph-CoT) to enable LLMs to reason over these graph-structured knowledge sources. Graph-CoT consists of three key steps:
- LLM Reasoning: The LLM generates an initial response to the given question.
- LLM-Graph Interaction: The LLM's response is used to retrieve relevant nodes and edges from the knowledge graph.
- Graph Execution: The retrieved graph elements are executed in a step-by-step fashion to produce a final answer.
Through systematic experiments with three different LLM backbones on the GRBench dataset, the authors demonstrate that the Graph-CoT framework consistently outperforms baseline approaches that do not explicitly leverage the graph structure.
Critical Analysis
The authors have made a valuable contribution by creating the GRBench dataset and proposing the Graph-CoT framework to augment LLMs with graph-structured knowledge. However, the paper does not address some potential limitations and areas for further research:
-
Scalability: The current GRBench dataset is relatively small, with only 10 domain-specific knowledge graphs. Scaling this approach to larger, more diverse graph structures may pose challenges in terms of computational complexity and model performance.
-
Generalizability: The paper focuses on evaluating the proposed approach on the GRBench dataset, which was manually curated by the authors. It would be interesting to see how well the Graph-CoT framework performs on real-world, naturally occurring knowledge graphs from various domains.
-
Interpretability: While the step-by-step reasoning process of Graph-CoT is intended to improve the transparency of the LLM's decision-making, the paper does not provide a detailed analysis of the intermediate steps and their contribution to the final output. Improving the interpretability of the framework could further enhance its trustworthiness and adoption.
-
Robustness: The paper does not explore the resilience of the Graph-CoT framework to noisy, incomplete, or potentially adversarial graph data. Investigating the model's behavior in such scenarios would be valuable for real-world deployment.
Despite these potential areas for improvement, the paper presents an interesting and promising approach for leveraging graph-structured knowledge to enhance the capabilities of large language models. The GRBench dataset and the Graph-CoT framework can serve as valuable resources for further research in this direction.
Conclusion
This paper tackles the problem of hallucinations in large language models by proposing a framework called Graph Chain-of-Thought (Graph-CoT) that enables LLMs to reason over graph-structured knowledge sources. The authors first construct a Graph Reasoning Benchmark (GRBench) dataset to facilitate research in this area, and then demonstrate the effectiveness of the Graph-CoT approach on this benchmark.
The key insight of the paper is that the knowledge encoded in many real-world domains is not just contained in individual texts, but also in the interconnections between them. By allowing LLMs to traverse and reason over these graph structures, the authors show that the models can provide more accurate and informative outputs, particularly on knowledge-intensive tasks.
While the paper presents an important step forward, there are still opportunities for further research to address scalability, generalizability, interpretability, and robustness. Nonetheless, the GRBench dataset and the Graph-CoT framework offer valuable resources for the community to build upon and advance the state of the art in augmenting large language models with graph-structured knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
💬
GraphReason: Enhancing Reasoning Capabilities of Large Language Models through A Graph-Based Verification Approach
Lang Cao
0
0
Large Language Models (LLMs) have showcased impressive reasoning capabilities, particularly when guided by specifically designed prompts in complex reasoning tasks such as math word problems. These models typically solve tasks using a chain-of-thought approach, which not only bolsters their reasoning abilities but also provides valuable insights into their problem-solving process. However, there is still significant room for enhancing the reasoning abilities of LLMs. Some studies suggest that the integration of an LLM output verifier can boost reasoning accuracy without necessitating additional model training. In this paper, we follow these studies and introduce a novel graph-based method to further augment the reasoning capabilities of LLMs. We posit that multiple solutions to a reasoning task, generated by an LLM, can be represented as a reasoning graph due to the logical connections between intermediate steps from different reasoning paths. Therefore, we propose the Reasoning Graph Verifier (GraphReason) to analyze and verify the solutions generated by LLMs. By evaluating these graphs, models can yield more accurate and reliable results.Our experimental results show that our graph-based verification method not only significantly enhances the reasoning abilities of LLMs but also outperforms existing verifier methods in terms of improving these models' reasoning performance.
4/23/2024
💬
Logic Query of Thoughts: Guiding Large Language Models to Answer Complex Logic Queries with Knowledge Graphs
Lihui Liu, Zihao Wang, Ruizhong Qiu, Yikun Ban, Eunice Chan, Yangqiu Song, Jingrui He, Hanghang Tong
0
0
Despite the superb performance in many tasks, large language models (LLMs) bear the risk of generating hallucination or even wrong answers when confronted with tasks that demand the accuracy of knowledge. The issue becomes even more noticeable when addressing logic queries that require multiple logic reasoning steps. On the other hand, knowledge graph (KG) based question answering methods are capable of accurately identifying the correct answers with the help of knowledge graph, yet its accuracy could quickly deteriorate when the knowledge graph itself is sparse and incomplete. It remains a critical challenge on how to integrate knowledge graph reasoning with LLMs in a mutually beneficial way so as to mitigate both the hallucination problem of LLMs as well as the incompleteness issue of knowledge graphs. In this paper, we propose 'Logic-Query-of-Thoughts' (LGOT) which is the first of its kind to combine LLMs with knowledge graph based logic query reasoning. LGOT seamlessly combines knowledge graph reasoning and LLMs, effectively breaking down complex logic queries into easy to answer subquestions. Through the utilization of both knowledge graph reasoning and LLMs, it successfully derives answers for each subquestion. By aggregating these results and selecting the highest quality candidate answers for each step, LGOT achieves accurate results to complex questions. Our experimental findings demonstrate substantial performance enhancements, with up to 20% improvement over ChatGPT.
4/16/2024
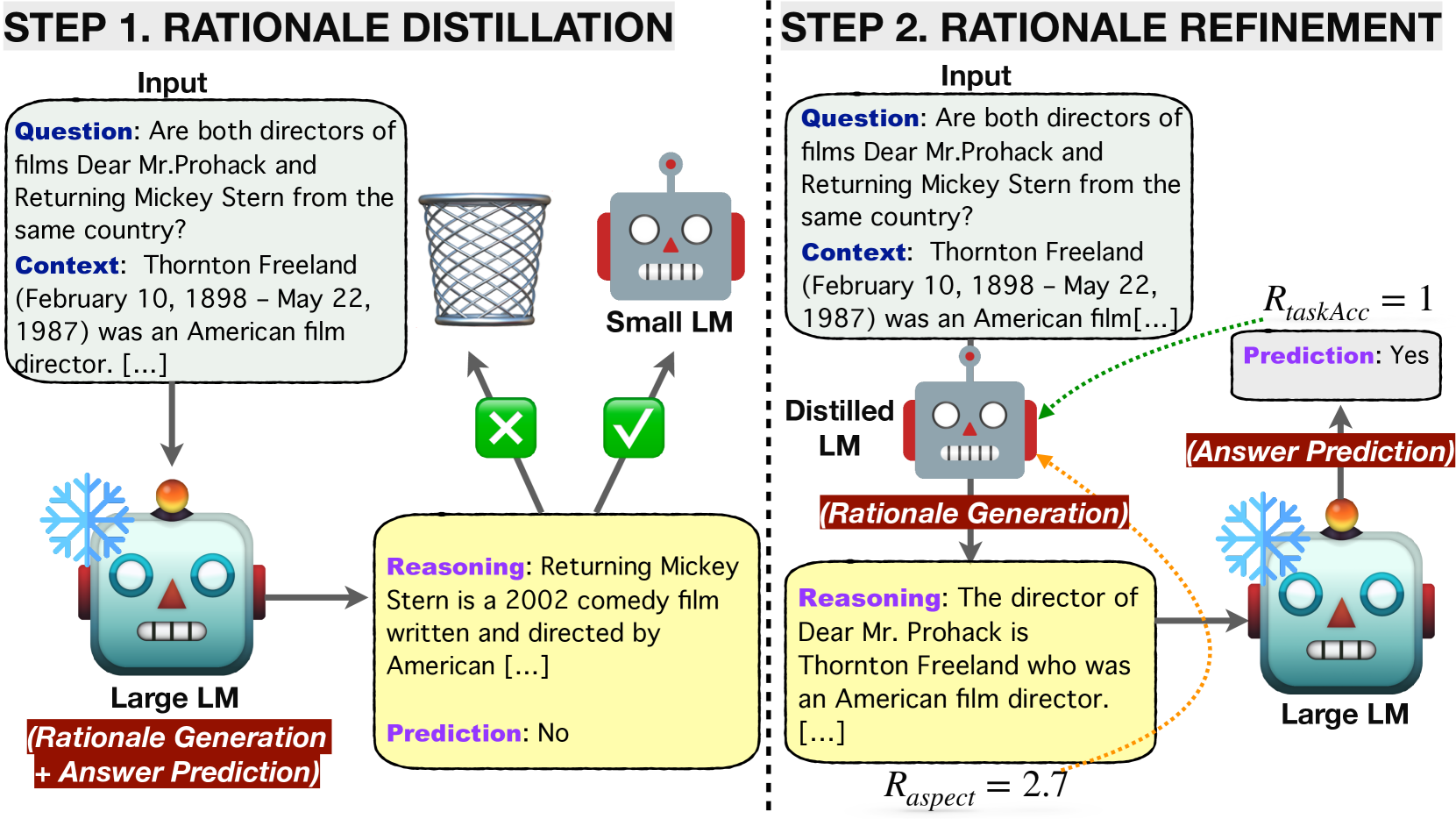
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024