Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
2404.03414
0
0
Abstract
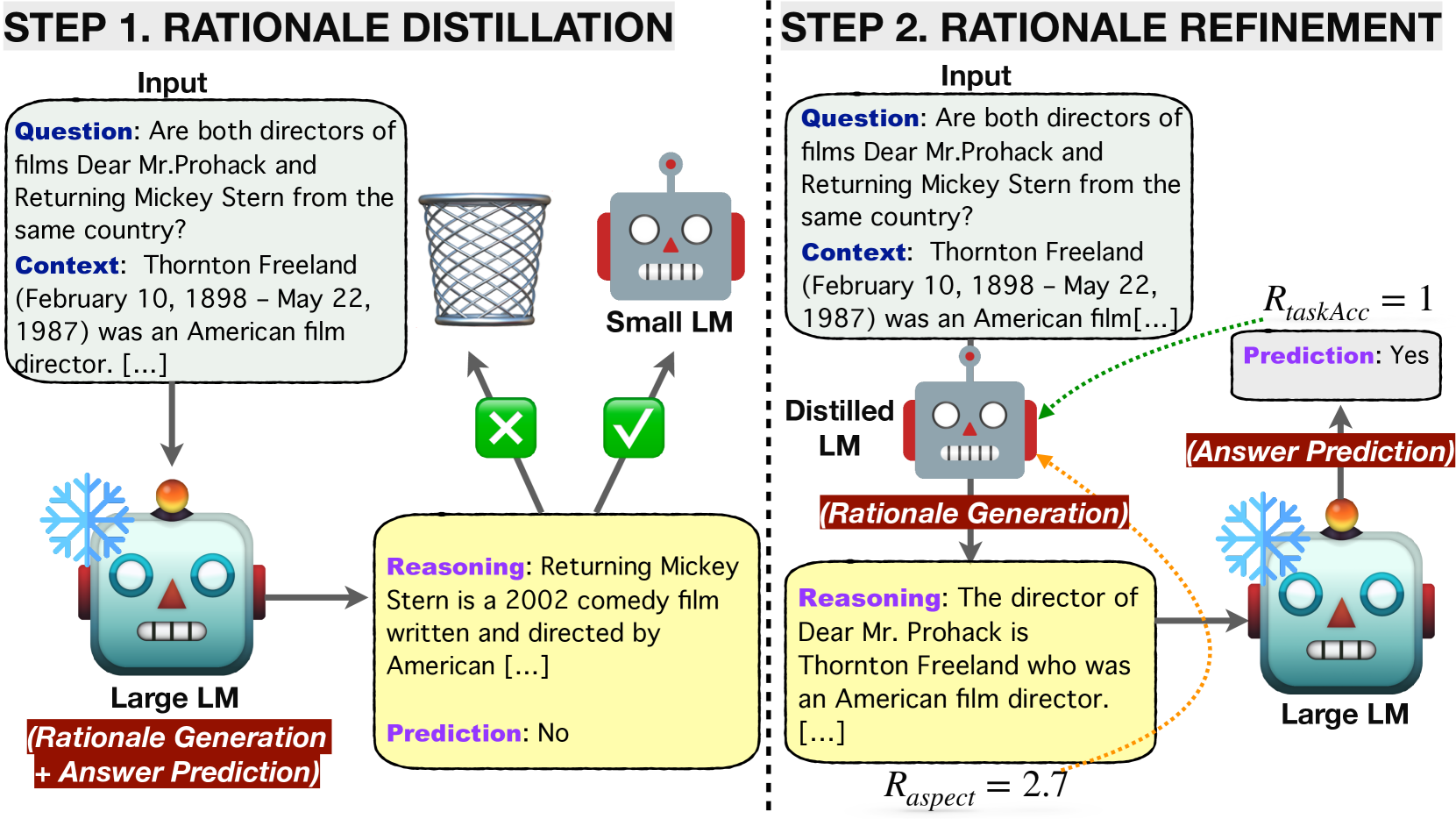
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a novel approach called "LM-Guided Chain-of-Thought" to help large language models (LLMs) reason more effectively.
- The key idea is to leverage smaller, specialized language models to guide the reasoning process of LLMs, leading to improved performance on challenging cognitive tasks.
- The researchers demonstrate the effectiveness of this approach on a diverse set of tasks, including question answering, logical reasoning, and common sense reasoning.
Plain English Explanation
The paper presents a new way to make large language models (LLMs) - which are powerful AI systems that can understand and generate human-like text - better at reasoning and problem-solving. The researchers found that by using smaller, more specialized language models to "guide" the larger LLMs through the reasoning process, the LLMs were able to perform much better on challenging cognitive tasks.
Imagine you're trying to solve a complex math problem. You might start by breaking it down into simpler steps, using your knowledge of math concepts to guide you towards the solution. Similarly, the LM-Guided Chain-of-Thought approach uses smaller, more focused language models to break down the problem and provide step-by-step guidance to the larger LLM, helping it reason more effectively.
The researchers tested this approach on a variety of tasks, such as answering questions, making logical inferences, and demonstrating common sense understanding. In each case, the LLMs performed significantly better when guided by the smaller language models, compared to when they tried to solve the problems on their own.
This research could have important implications for enhancing the capabilities of large language models, making them more effective at tackling complex, reasoning-intensive tasks. By leveraging the strengths of both smaller and larger models, the LM-Guided Chain-of-Thought approach represents a promising direction for improving the reasoning abilities of state-of-the-art AI systems.
Technical Explanation
The paper introduces a novel technique called "LM-Guided Chain-of-Thought" to enhance the reasoning capabilities of large language models (LLMs). The key idea is to leverage smaller, specialized language models to guide the step-by-step reasoning process of LLMs, leading to improved performance on challenging cognitive tasks.
The researchers first train a "guiding" language model on a diverse set of reasoning-centric datasets, such as question answering, logical inference, and common sense reasoning. This guiding model is then used to provide step-by-step prompts to the larger LLM, helping it break down the problem and generate a coherent chain of reasoning.
The researchers evaluate the effectiveness of this approach on a wide range of tasks, including Natural Language Inference, Closed-Book Question Answering, and Logical Reasoning. The results show that the LLMs guided by the smaller language models significantly outperform their standalone counterparts, demonstrating the potential of this approach for enhancing the reasoning capabilities of large language models.
The paper also includes a detailed ablation study, examining the impact of different architectural choices and training strategies for the guiding model. The researchers found that fine-tuning the guiding model on reasoning-centric datasets was crucial for achieving the best results, highlighting the importance of task-specific knowledge for effective reasoning.
Critical Analysis
The LM-Guided Chain-of-Thought approach presented in this paper is a promising direction for improving the reasoning capabilities of large language models. By leveraging the strengths of smaller, more specialized language models, the researchers have shown that LLMs can achieve significant performance gains on a variety of challenging cognitive tasks.
However, the paper also acknowledges several limitations and areas for future research. For example, the authors note that the guiding model may struggle to provide effective prompts for particularly complex or open-ended problems, and more sophisticated prompt engineering or model architectures may be needed to address these challenges.
Additionally, the paper does not delve into the potential computational and memory overhead introduced by the chain-of-thought process, which could be an important practical consideration for deploying this approach in real-world settings. Further research may be needed to optimize the efficiency of the LM-Guided Chain-of-Thought approach.
Overall, this paper represents an important step forward in enhancing the reasoning capabilities of large language models, and the insights and techniques presented could have significant implications for the development of more capable and versatile AI systems. As the field of natural language processing continues to evolve, it will be important for researchers to build on these ideas and explore new ways to leverage the strengths of both small and large language models to tackle increasingly complex cognitive tasks.
Conclusion
The LM-Guided Chain-of-Thought approach proposed in this paper offers a promising new way to improve the reasoning capabilities of large language models. By using smaller, specialized language models to guide the step-by-step reasoning process of LLMs, the researchers have demonstrated significant performance gains on a variety of challenging cognitive tasks, including question answering, logical reasoning, and common sense understanding.
This research could have important implications for the development of more capable and versatile AI systems, as the ability to reason effectively is a critical component of many real-world applications. By leveraging the complementary strengths of small and large language models, the LM-Guided Chain-of-Thought approach represents an exciting direction for enhancing the general intelligence of state-of-the-art AI models.
Related Papers
Can only LLMs do Reasoning?: Potential of Small Language Models in Task Planning
Gawon Choi, Hyemin Ahn
0
0
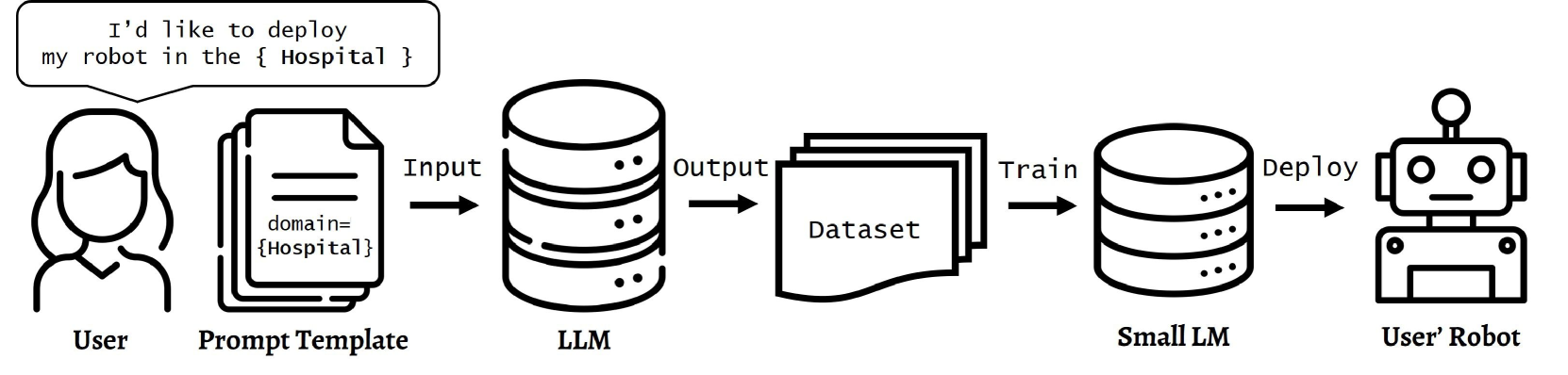
In robotics, the use of Large Language Models (LLMs) is becoming prevalent, especially for understanding human commands. In particular, LLMs are utilized as domain-agnostic task planners for high-level human commands. LLMs are capable of Chain-of-Thought (CoT) reasoning, and this allows LLMs to be task planners. However, we need to consider that modern robots still struggle to perform complex actions, and the domains where robots can be deployed are limited in practice. This leads us to pose a question: If small LMs can be trained to reason in chains within a single domain, would even small LMs be good task planners for the robots? To train smaller LMs to reason in chains, we build `COmmand-STeps datasets' (COST) consisting of high-level commands along with corresponding actionable low-level steps, via LLMs. We release not only our datasets but also the prompt templates used to generate them, to allow anyone to build datasets for their domain. We compare GPT3.5 and GPT4 with the finetuned GPT2 for task domains, in tabletop and kitchen environments, and the result shows that GPT2-medium is comparable to GPT3.5 for task planning in a specific domain. Our dataset, code, and more output samples can be found in https://github.com/Gawon-Choi/small-LMs-Task-Planning
4/8/2024
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
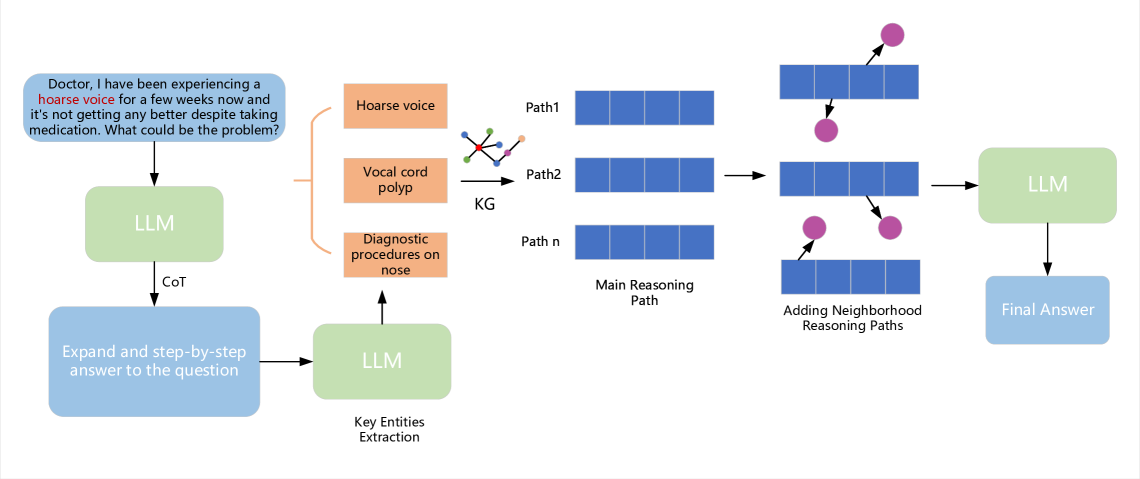
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
💬
Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs
Bowen Jin, Chulin Xie, Jiawei Zhang, Kashob Kumar Roy, Yu Zhang, Suhang Wang, Yu Meng, Jiawei Han
0
0
Large language models (LLMs), while exhibiting exceptional performance, suffer from hallucinations, especially on knowledge-intensive tasks. Existing works propose to augment LLMs with individual text units retrieved from external knowledge corpora to alleviate the issue. However, in many domains, texts are interconnected (e.g., academic papers in a bibliographic graph are linked by citations and co-authorships) which form a (text-attributed) graph. The knowledge in such graphs is encoded not only in single texts/nodes but also in their associated connections. To facilitate the research of augmenting LLMs with graphs, we manually construct a Graph Reasoning Benchmark dataset called GRBench, containing 1,740 questions that can be answered with the knowledge from 10 domain graphs. Then, we propose a simple and effective framework called Graph Chain-of-thought (Graph-CoT) to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. Each Graph-CoT iteration consists of three sub-steps: LLM reasoning, LLM-graph interaction, and graph execution. We conduct systematic experiments with three LLM backbones on GRBench, where Graph-CoT outperforms the baselines consistently. The code is available at https://github.com/PeterGriffinJin/Graph-CoT.
4/11/2024
Large Language Models Can Learn Temporal Reasoning
Siheng Xiong, Ali Payani, Ramana Kompella, Faramarz Fekri
0
0
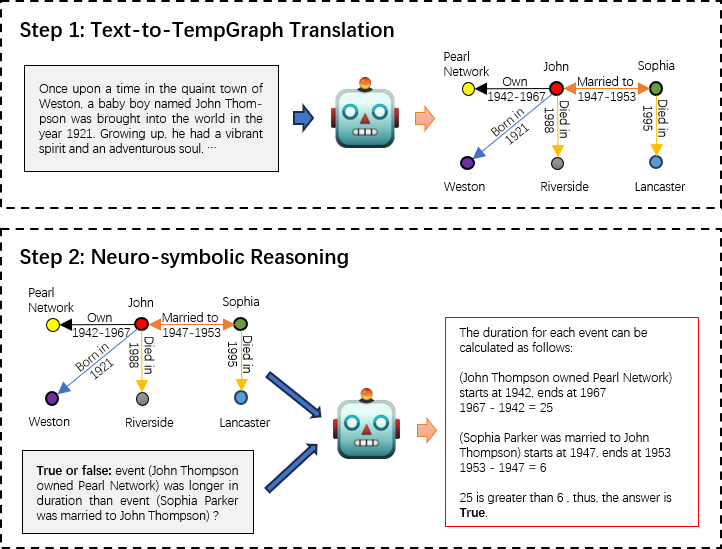
While large language models (LLMs) have demonstrated remarkable reasoning capabilities, they are not without their flaws and inaccuracies. Recent studies have introduced various methods to mitigate these limitations. Temporal reasoning (TR), in particular, presents a significant challenge for LLMs due to its reliance on diverse temporal expressions and intricate temporal logic. In this paper, we propose TG-LLM, a novel framework towards language-based TR. Instead of reasoning over the original context, we adopt a latent representation, temporal graph (TG) that facilitates the TR learning. A synthetic dataset (TGQA), which is fully controllable and requires minimal supervision, is constructed for fine-tuning LLMs on this text-to-TG translation task. We confirmed in experiments that the capability of TG translation learned on our dataset can be transferred to other TR tasks and benchmarks. On top of that, we teach LLM to perform deliberate reasoning over the TGs via Chain of Thought (CoT) bootstrapping and graph data augmentation. We observed that those strategies, which maintain a balance between usefulness and diversity, bring more reliable CoTs and final results than the vanilla CoT distillation.
4/23/2024