AgileIR: Memory-Efficient Group Shifted Windows Attention for Agile Image Restoration

0

Sign in to get full access
Overview
- The paper introduces a novel memory-efficient attention mechanism called "AgileIR" for image restoration tasks.
- It employs a group shifted windows attention strategy to reduce memory consumption while preserving performance.
- The proposed method demonstrates competitive results on various image restoration benchmarks.
Plain English Explanation
The paper presents a new technique called "AgileIR" that can help improve the efficiency of image restoration models. Image restoration is the process of enhancing or fixing damaged or low-quality images.
The key idea behind AgileIR is a type of attention mechanism called "group shifted windows attention." Attention is a way for models to focus on the most important parts of an image when making predictions.
AgileIR divides the image into groups and shifts the attention windows between these groups. This makes the model more memory-efficient, meaning it can run on hardware with limited memory, like mobile devices. At the same time, it maintains the model's ability to accurately restore images.
The paper shows that AgileIR performs well on various image restoration benchmarks, matching or even exceeding the performance of other state-of-the-art methods. This suggests the technique could be useful for deploying high-quality image restoration models on a wider range of hardware.
Technical Explanation
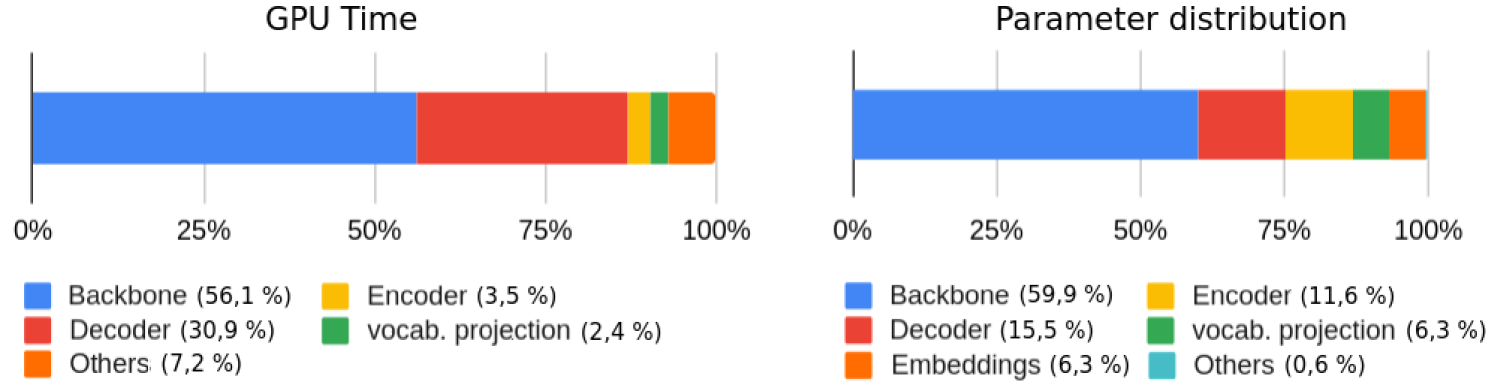
The paper introduces a novel attention mechanism called "AgileIR" that is designed to be memory-efficient while preserving performance on image restoration tasks. Memory-efficient attention is crucial for deploying models on hardware with limited memory, like mobile devices.
AgileIR employs a "group shifted windows attention" strategy, which divides the image into groups and shifts the attention windows between these groups. This reduces the overall memory footprint of the attention computation compared to standard approaches.
The authors evaluate AgileIR on several image restoration benchmarks, including tasks like super-resolution, denoising, and deraining. They show that AgileIR can match or even exceed the performance of other state-of-the-art methods, while being more memory-efficient.
Furthermore, the paper provides detailed ablation studies to understand the impact of different design choices in AgileIR, such as the group size and shift distance. These insights can inform the development of future memory-efficient attention mechanisms.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed AgileIR technique. The authors explore its performance across multiple image restoration tasks and compare it to relevant baselines, demonstrating its competitive results.
One potential limitation is that the paper does not provide a detailed analysis of the computational complexity or inference speed of AgileIR compared to other methods. While the focus is on memory efficiency, understanding the trade-offs in terms of computational cost would also be valuable for practitioners.
Additionally, the paper could have delved deeper into the underlying reasons for the performance improvements observed with AgileIR. A more extensive analysis of the attention patterns learned by the model and how they contribute to image restoration could provide further insights.
Overall, the paper makes a compelling case for the effectiveness of the AgileIR approach and its potential to enable efficient image restoration models on resource-constrained devices. Further research exploring the broader applicability of the group shifted windows attention mechanism would be an interesting direction for the future.
Conclusion
The paper introduces a novel memory-efficient attention mechanism called "AgileIR" for image restoration tasks. By employing a group shifted windows attention strategy, AgileIR is able to reduce the memory footprint of attention computation while maintaining competitive performance on various image restoration benchmarks.
The findings suggest that AgileIR could be a valuable technique for deploying high-quality image restoration models on hardware with limited memory, such as mobile devices. The memory efficiency of AgileIR opens up new possibilities for bringing advanced image enhancement capabilities to a wider range of applications and end-user devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AgileIR: Memory-Efficient Group Shifted Windows Attention for Agile Image Restoration
Hongyi Cai, Mohammad Mahdinur Rahman, Mohammad Shahid Akhtar, Jie Li, Jingyu Wu, Zhili Fang
Image Transformers show a magnificent success in Image Restoration tasks. Nevertheless, most of transformer-based models are strictly bounded by exorbitant memory occupancy. Our goal is to reduce the memory consumption of Swin Transformer and at the same time speed up the model during training process. Thus, we introduce AgileIR, group shifted attention mechanism along with window attention, which sparsely simplifies the model in architecture. We propose Group Shifted Window Attention (GSWA) to decompose Shift Window Multi-head Self Attention (SW-MSA) and Window Multi-head Self Attention (W-MSA) into groups across their attention heads, contributing to shrinking memory usage in back propagation. In addition to that, we keep shifted window masking and its shifted learnable biases during training, in order to induce the model interacting across windows within the channel. We also re-allocate projection parameters to accelerate attention matrix calculation, which we found a negligible decrease in performance. As a result of experiment, compared with our baseline SwinIR and other efficient quantization models, AgileIR keeps the performance still at 32.20 dB on Set5 evaluation dataset, exceeding other methods with tailor-made efficient methods and saves over 50% memory while a large batch size is employed.
Read more9/11/2024
0
Shifted Window Fourier Transform And Retention For Image Captioning
Jia Cheng Hu, Roberto Cavicchioli, Alessandro Capotondi
Image Captioning is an important Language and Vision task that finds application in a variety of contexts, ranging from healthcare to autonomous vehicles. As many real-world applications rely on devices with limited resources, much effort in the field was put into the development of lighter and faster models. However, much of the current optimizations focus on the Transformer architecture in contrast to the existence of more efficient methods. In this work, we introduce SwiFTeR, an architecture almost entirely based on Fourier Transform and Retention, to tackle the main efficiency bottlenecks of current light image captioning models, being the visual backbone's onerosity, and the decoder's quadratic cost. SwiFTeR is made of only 20M parameters, and requires 3.1 GFLOPs for a single forward pass. Additionally, it showcases superior scalability to the caption length and its small memory requirements enable more images to be processed in parallel, compared to the traditional transformer-based architectures. For instance, it can generate 400 captions in one second. Although, for the time being, the caption quality is lower (110.2 CIDEr-D), most of the decrease is not attributed to the architecture but rather an incomplete training practice which currently leaves much room for improvements. Overall, SwiFTeR points toward a promising direction to new efficient architectural design. The implementation code will be released in the future.
Read more8/27/2024

0
SWAT: Scalable and Efficient Window Attention-based Transformers Acceleration on FPGAs
Zhenyu Bai, Pranav Dangi, Huize Li, Tulika Mitra
Efficiently supporting long context length is crucial for Transformer models. The quadratic complexity of the self-attention computation plagues traditional Transformers. Sliding window-based static sparse attention mitigates the problem by limiting the attention scope of the input tokens, reducing the theoretical complexity from quadratic to linear. Although the sparsity induced by window attention is highly structured, it does not align perfectly with the microarchitecture of the conventional accelerators, leading to suboptimal implementation. In response, we propose a dataflow-aware FPGA-based accelerator design, SWAT, that efficiently leverages the sparsity to achieve scalable performance for long input. The proposed microarchitecture is based on a design that maximizes data reuse by using a combination of row-wise dataflow, kernel fusion optimization, and an input-stationary design considering the distributed memory and computation resources of FPGA. Consequently, it achieves up to 22$times$ and 5.7$times$ improvement in latency and energy efficiency compared to the baseline FPGA-based accelerator and 15$times$ energy efficiency compared to GPU-based solution.
Read more5/28/2024

0
Memory-Efficient Sparse Pyramid Attention Networks for Whole Slide Image Analysis
Weiyi Wu, Chongyang Gao, Xinwen Xu, Siting Li, Jiang Gui
Whole Slide Images (WSIs) are crucial for modern pathological diagnosis, yet their gigapixel-scale resolutions and sparse informative regions pose significant computational challenges. Traditional dense attention mechanisms, widely used in computer vision and natural language processing, are impractical for WSI analysis due to the substantial data scale and the redundant processing of uninformative areas. To address these challenges, we propose Memory-Efficient Sparse Pyramid Attention Networks with Shifted Windows (SPAN), drawing inspiration from state-of-the-art sparse attention techniques in other domains. SPAN introduces a sparse pyramid attention architecture that hierarchically focuses on informative regions within the WSI, aiming to reduce memory overhead while preserving critical features. Additionally, the incorporation of shifted windows enables the model to capture long-range contextual dependencies essential for accurate classification. We evaluated SPAN on multiple public WSI datasets, observing its competitive performance. Unlike existing methods that often struggle to model spatial and contextual information due to memory constraints, our approach enables the accurate modeling of these crucial features. Our study also highlights the importance of key design elements in attention mechanisms, such as the shifted-window scheme and the hierarchical structure, which contribute substantially to the effectiveness of SPAN in WSI analysis. The potential of SPAN for memory-efficient and effective analysis of WSI data is thus demonstrated, and the code will be made publicly available following the publication of this work.
Read more6/14/2024