AGL-NET: Aerial-Ground Cross-Modal Global Localization with Varying Scales
2404.03187
0
0
Abstract
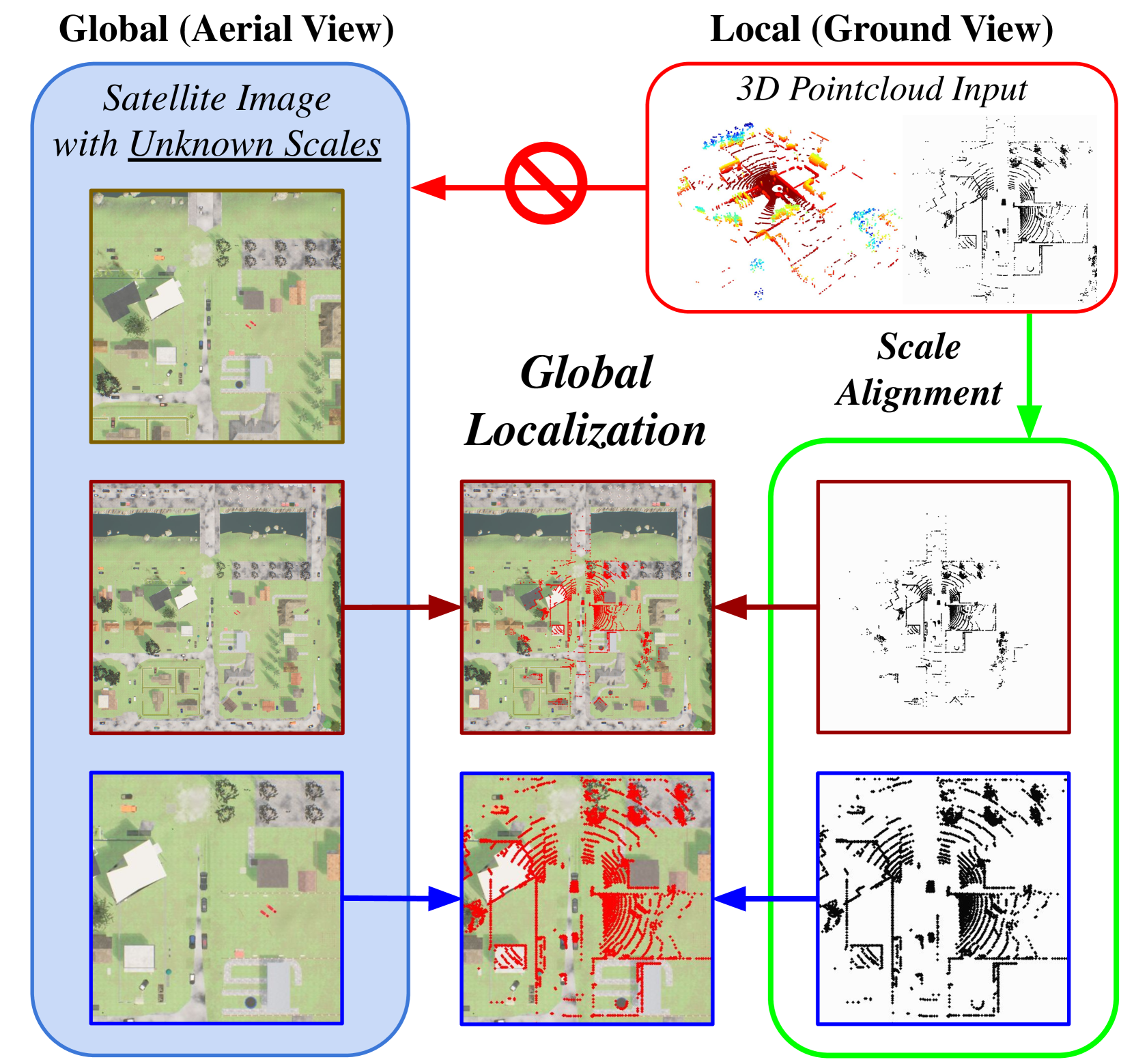
We present AGL-NET, a novel learning-based method for global localization using LiDAR point clouds and satellite maps. AGL-NET tackles two critical challenges: bridging the representation gap between image and points modalities for robust feature matching, and handling inherent scale discrepancies between global view and local view. To address these challenges, AGL-NET leverages a unified network architecture with a novel two-stage matching design. The first stage extracts informative neural features directly from raw sensor data and performs initial feature matching. The second stage refines this matching process by extracting informative skeleton features and incorporating a novel scale alignment step to rectify scale variations between LiDAR and map data. Furthermore, a novel scale and skeleton loss function guides the network toward learning scale-invariant feature representations, eliminating the need for pre-processing satellite maps. This significantly improves real-world applicability in scenarios with unknown map scales. To facilitate rigorous performance evaluation, we introduce a meticulously designed dataset within the CARLA simulator specifically tailored for metric localization training and assessment. The code and dataset will be made publicly available.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper presents AGL-Net, a cross-modal global localization system that can match aerial and ground-level images at varying scales.
- The system uses deep learning to learn a shared feature representation between aerial and ground-level imagery, enabling accurate localization despite differences in viewpoint and scale.
- Experiments show AGL-Net outperforms previous state-of-the-art methods for cross-modal localization, particularly in challenging scenarios with large scale variations.
Plain English Explanation
AGL-Net is a new computer vision system that can figure out where a ground-level photograph was taken by comparing it to aerial (overhead) images. This is a challenging task because the viewpoint and scale of the two types of images are very different.
Imagine you take a photo on the street and want to know exactly where that photo was taken on a map. AGL-Net can analyze features in your ground-level photo and match them to corresponding features in overhead aerial imagery, even if the scale and angle of the two images are quite different.
This is useful for applications like autonomous driving, where a self-driving car needs to localize itself precisely within a larger map. It's also valuable for augmented reality, where digital information needs to be accurately overlaid on the real world.
The key innovation in AGL-Net is that it learns a shared visual feature representation that bridges the gap between aerial and ground-level imagery. Rather than trying to directly match low-level visual elements, it discovers higher-level visual patterns that are common to both viewpoints.
Technical Explanation
AGL-Net uses a deep neural network architecture to learn this shared feature representation. The network takes as input both an aerial image and a ground-level image, and outputs a set of location coordinates corresponding to where the ground-level image was captured.
The core of the network is a series of convolutional and pooling layers that extract visual features from the two input images. These features are then fed into a fusion module that combines the aerial and ground-level representations. Finally, a regressor module predicts the geographic coordinates.
Crucially, AGL-Net is trained end-to-end on a large dataset of paired aerial and ground-level images with known locations. This allows the network to learn the complex visual correspondences between the two modalities.
Experiments show AGL-Net outperforms previous cross-modal localization approaches, especially in challenging scenarios with large scale variations between the aerial and ground-level views. This highlights the effectiveness of the shared feature learning approach.
Critical Analysis
The paper provides a thorough evaluation of AGL-Net's performance, including comparisons to state-of-the-art methods on multiple benchmark datasets. The results demonstrate the system's strong capability for cross-modal localization, even in difficult real-world conditions.
One potential limitation is the reliance on having a large, high-quality training dataset of paired aerial and ground-level imagery with precise location labels. Acquiring such a dataset may be resource-intensive in practice.
Additionally, the paper does not explore the system's robustness to variations in environmental conditions, sensor characteristics, or other factors that could impact real-world performance. Further testing in more diverse scenarios would help validate the generalizability of AGL-Net.
Overall, AGL-Net represents an impressive advance in cross-modal visual localization. The technical innovations and strong empirical results suggest the approach has significant potential for real-world applications. Continued research to address the noted limitations could further enhance the system's capabilities and real-world deployability.
Conclusion
AGL-Net is a novel deep learning system that can accurately localize ground-level images by matching them to aerial imagery, even when there are substantial differences in viewpoint and scale. The system's ability to learn a shared visual feature representation between the two modalities is a key technical breakthrough that enables robust cross-modal localization.
The strong performance demonstrated in the paper's experiments suggests AGL-Net could have transformative applications in areas like autonomous navigation, augmented reality, and urban planning. As the underlying technologies continue to advance, systems like AGL-Net will play an increasingly important role in bridging the gap between ground-level and aerial perception, with far-reaching implications for how we interact with and understand the world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AG-ReID.v2: Bridging Aerial and Ground Views for Person Re-identification
Huy Nguyen, Kien Nguyen, Sridha Sridharan, Clinton Fookes
0
0
Aerial-ground person re-identification (Re-ID) presents unique challenges in computer vision, stemming from the distinct differences in viewpoints, poses, and resolutions between high-altitude aerial and ground-based cameras. Existing research predominantly focuses on ground-to-ground matching, with aerial matching less explored due to a dearth of comprehensive datasets. To address this, we introduce AG-ReID.v2, a dataset specifically designed for person Re-ID in mixed aerial and ground scenarios. This dataset comprises 100,502 images of 1,615 unique individuals, each annotated with matching IDs and 15 soft attribute labels. Data were collected from diverse perspectives using a UAV, stationary CCTV, and smart glasses-integrated camera, providing a rich variety of intra-identity variations. Additionally, we have developed an explainable attention network tailored for this dataset. This network features a three-stream architecture that efficiently processes pairwise image distances, emphasizes key top-down features, and adapts to variations in appearance due to altitude differences. Comparative evaluations demonstrate the superiority of our approach over existing baselines. We plan to release the dataset and algorithm source code publicly, aiming to advance research in this specialized field of computer vision. For access, please visit https://github.com/huynguyen792/AG-ReID.v2.
4/9/2024
Adaptive Guidance Learning for Camouflaged Object Detection
Zhennan Chen, Xuying Zhang, Tian-Zhu Xiang, Ying Tai
0
0
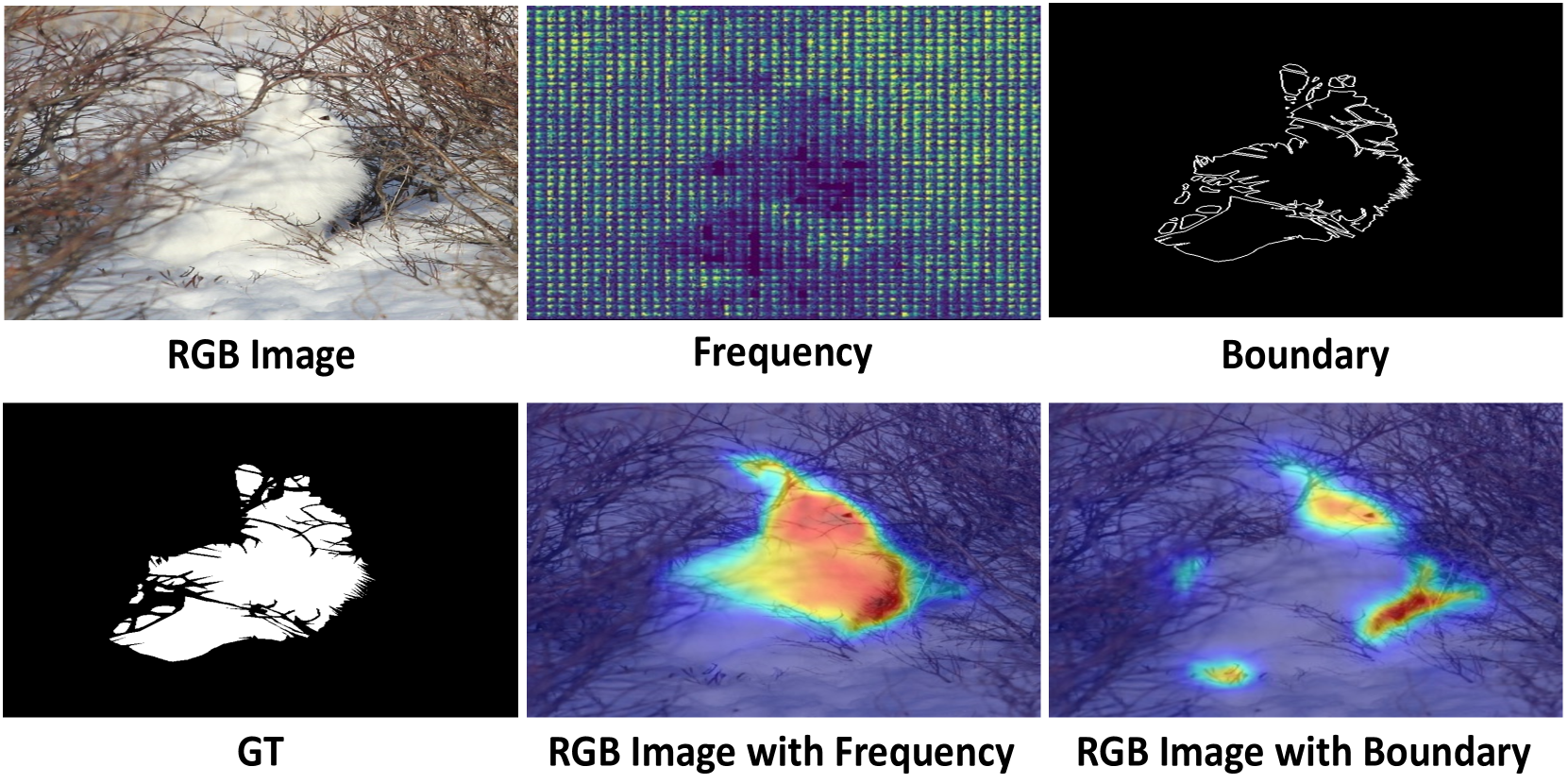
Camouflaged object detection (COD) aims to segment objects visually embedded in their surroundings, which is a very challenging task due to the high similarity between the objects and the background. To address it, most methods often incorporate additional information (e.g., boundary, texture, and frequency clues) to guide feature learning for better detecting camouflaged objects from the background. Although progress has been made, these methods are basically individually tailored to specific auxiliary cues, thus lacking adaptability and not consistently achieving high segmentation performance. To this end, this paper proposes an adaptive guidance learning network, dubbed textit{AGLNet}, which is a unified end-to-end learnable model for exploring and adapting different additional cues in CNN models to guide accurate camouflaged feature learning. Specifically, we first design a straightforward additional information generation (AIG) module to learn additional camouflaged object cues, which can be adapted for the exploration of effective camouflaged features. Then we present a hierarchical feature combination (HFC) module to deeply integrate additional cues and image features to guide camouflaged feature learning in a multi-level fusion manner.Followed by a recalibration decoder (RD), different features are further aggregated and refined for accurate object prediction. Extensive experiments on three widely used COD benchmark datasets demonstrate that the proposed method achieves significant performance improvements under different additional cues, and outperforms the recent 20 state-of-the-art methods by a large margin. Our code will be made publicly available at: textcolor{blue}{{https://github.com/ZNan-Chen/AGLNet}}.
5/8/2024

PIGEON: Predicting Image Geolocations
Lukas Haas, Michal Skreta, Silas Alberti, Chelsea Finn
0
0
Planet-scale image geolocalization remains a challenging problem due to the diversity of images originating from anywhere in the world. Although approaches based on vision transformers have made significant progress in geolocalization accuracy, success in prior literature is constrained to narrow distributions of images of landmarks, and performance has not generalized to unseen places. We present a new geolocalization system that combines semantic geocell creation, multi-task contrastive pretraining, and a novel loss function. Additionally, our work is the first to perform retrieval over location clusters for guess refinements. We train two models for evaluations on street-level data and general-purpose image geolocalization; the first model, PIGEON, is trained on data from the game of Geoguessr and is capable of placing over 40% of its guesses within 25 kilometers of the target location globally. We also develop a bot and deploy PIGEON in a blind experiment against humans, ranking in the top 0.01% of players. We further challenge one of the world's foremost professional Geoguessr players to a series of six matches with millions of viewers, winning all six games. Our second model, PIGEOTTO, differs in that it is trained on a dataset of images from Flickr and Wikipedia, achieving state-of-the-art results on a wide range of image geolocalization benchmarks, outperforming the previous SOTA by up to 7.7 percentage points on the city accuracy level and up to 38.8 percentage points on the country level. Our findings suggest that PIGEOTTO is the first image geolocalization model that effectively generalizes to unseen places and that our approach can pave the way for highly accurate, planet-scale image geolocalization systems. Our code is available on GitHub.
4/9/2024
AUG: A New Dataset and An Efficient Model for Aerial Image Urban Scene Graph Generation
Yansheng Li, Kun Li, Yongjun Zhang, Linlin Wang, Dingwen Zhang
0
0
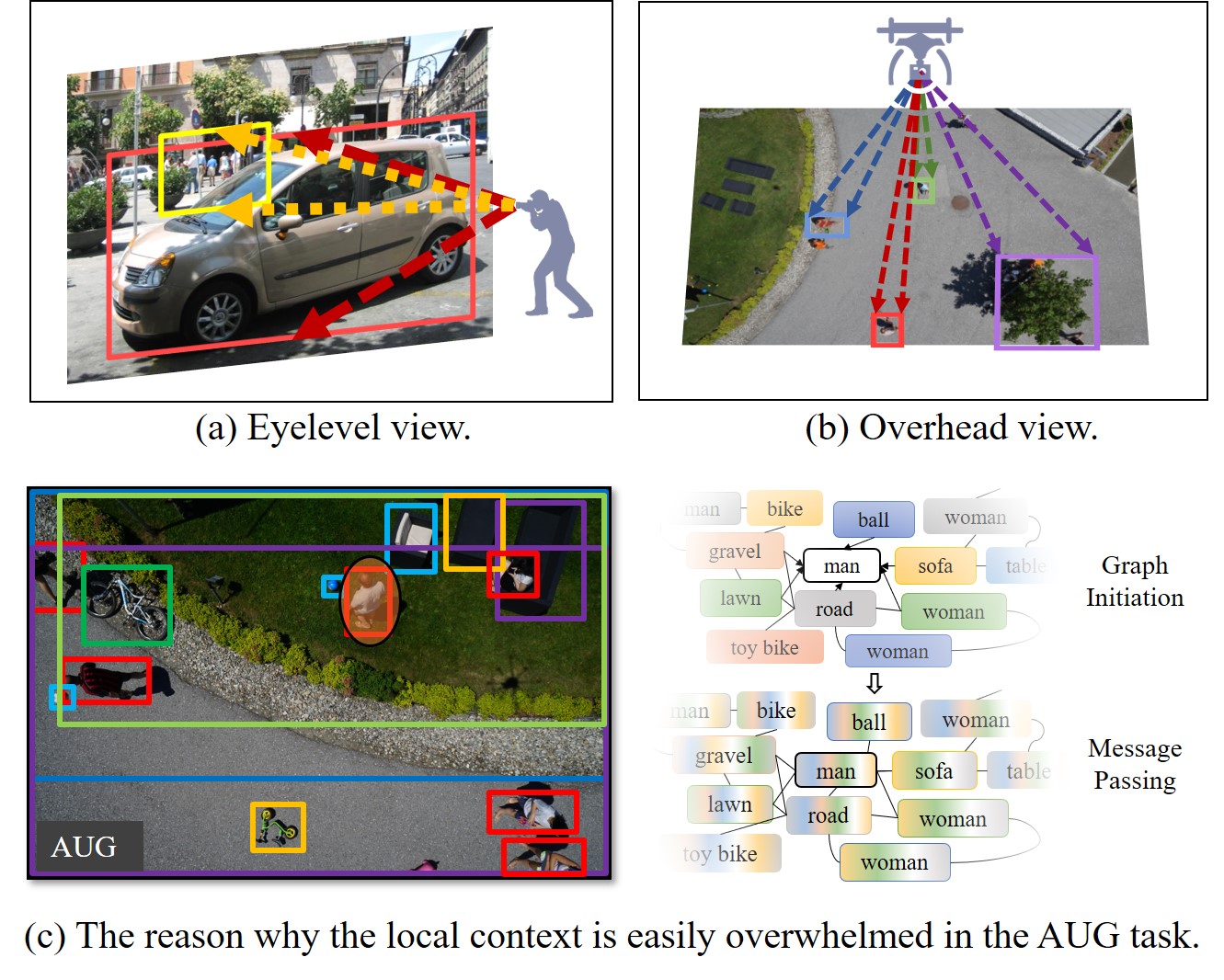
Scene graph generation (SGG) aims to understand the visual objects and their semantic relationships from one given image. Until now, lots of SGG datasets with the eyelevel view are released but the SGG dataset with the overhead view is scarcely studied. By contrast to the object occlusion problem in the eyelevel view, which impedes the SGG, the overhead view provides a new perspective that helps to promote the SGG by providing a clear perception of the spatial relationships of objects in the ground scene. To fill in the gap of the overhead view dataset, this paper constructs and releases an aerial image urban scene graph generation (AUG) dataset. Images from the AUG dataset are captured with the low-attitude overhead view. In the AUG dataset, 25,594 objects, 16,970 relationships, and 27,175 attributes are manually annotated. To avoid the local context being overwhelmed in the complex aerial urban scene, this paper proposes one new locality-preserving graph convolutional network (LPG). Different from the traditional graph convolutional network, which has the natural advantage of capturing the global context for SGG, the convolutional layer in the LPG integrates the non-destructive initial features of the objects with dynamically updated neighborhood information to preserve the local context under the premise of mining the global context. To address the problem that there exists an extra-large number of potential object relationship pairs but only a small part of them is meaningful in AUG, we propose the adaptive bounding box scaling factor for potential relationship detection (ABS-PRD) to intelligently prune the meaningless relationship pairs. Extensive experiments on the AUG dataset show that our LPG can significantly outperform the state-of-the-art methods and the effectiveness of the proposed locality-preserving strategy.
4/12/2024