PIGEON: Predicting Image Geolocations
2307.05845
1
0

Abstract
Planet-scale image geolocalization remains a challenging problem due to the diversity of images originating from anywhere in the world. Although approaches based on vision transformers have made significant progress in geolocalization accuracy, success in prior literature is constrained to narrow distributions of images of landmarks, and performance has not generalized to unseen places. We present a new geolocalization system that combines semantic geocell creation, multi-task contrastive pretraining, and a novel loss function. Additionally, our work is the first to perform retrieval over location clusters for guess refinements. We train two models for evaluations on street-level data and general-purpose image geolocalization; the first model, PIGEON, is trained on data from the game of Geoguessr and is capable of placing over 40% of its guesses within 25 kilometers of the target location globally. We also develop a bot and deploy PIGEON in a blind experiment against humans, ranking in the top 0.01% of players. We further challenge one of the world's foremost professional Geoguessr players to a series of six matches with millions of viewers, winning all six games. Our second model, PIGEOTTO, differs in that it is trained on a dataset of images from Flickr and Wikipedia, achieving state-of-the-art results on a wide range of image geolocalization benchmarks, outperforming the previous SOTA by up to 7.7 percentage points on the city accuracy level and up to 38.8 percentage points on the country level. Our findings suggest that PIGEOTTO is the first image geolocalization model that effectively generalizes to unseen places and that our approach can pave the way for highly accurate, planet-scale image geolocalization systems. Our code is available on GitHub.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- PIGEON is a research paper that proposes a method for predicting the geographic location of images.
- The paper explores the use of multi-task learning and meta-learning techniques to address the challenge of image geolocalization.
- The proposed approach aims to leverage both visual and contextual cues to improve the accuracy of location prediction.
Plain English Explanation
PIGEON is a new method for predicting where a photo was taken. This is a challenging problem in computer vision, as photos can be taken anywhere in the world and often lack clear geographic clues. The researchers behind PIGEON have developed a system that tries to learn patterns in photos and their locations to make better guesses about where a new photo was taken.
The key ideas behind PIGEON are multi-task learning and meta-learning. Multi-task learning means the system tries to learn multiple related tasks at the same time, like recognizing objects in the photo and estimating the location. Meta-learning means the system can quickly adapt to new data, which is important for predicting locations since there are so many possible places in the world.
By combining these techniques, the researchers hope to create a more accurate and flexible system for geolocating photos. This could have applications in areas like augmented reality, urban planning, and travel planning.
Technical Explanation
The PIGEON paper proposes a novel approach to the task of image geolocalization, which involves predicting the geographic location where an image was captured. The key contributions of the paper are:
-
Multi-task Learning: The authors formulate the geolocalization problem as a multi-task learning task, where the model is trained to jointly predict the image location and classify various visual attributes (e.g., object categories, scene types) present in the image. This allows the model to leverage the relationships between these related tasks to improve overall performance.
-
Meta-Learning: To address the challenge of data sparsity and distribution shifts across different geographic regions, the authors employ a meta-learning framework. This enables the model to quickly adapt to new geographic areas by leveraging knowledge gained from previous tasks and locations.
-
Geolocalization Architecture: The authors propose a deep neural network architecture that incorporates both visual and contextual features to predict the image location. This includes leveraging panoramic localization techniques to capture the broader spatial context around the image.
The authors evaluate their PIGEON model on several benchmark datasets for image geolocalization, demonstrating superior performance compared to existing state-of-the-art methods. The results highlight the benefits of the multi-task learning and meta-learning approaches in improving the robustness and generalization capabilities of the geolocalization system.
Critical Analysis
The PIGEON paper presents a compelling approach to the challenging problem of image geolocalization. The use of multi-task learning and meta-learning techniques is a promising direction, as it allows the model to leverage diverse visual and contextual information to improve location prediction accuracy.
However, the paper does acknowledge some limitations of the proposed approach. For example, the model may struggle with images that lack clear geographic cues, such as those captured in indoor environments or highly urbanized areas. Additionally, the paper notes that the meta-learning framework is still susceptible to potential distribution shifts across geographic regions, which could impact the model's performance in certain scenarios.
Further research could explore ways to address these limitations, such as incorporating additional types of contextual data (e.g., weather, time of day) or developing more robust meta-learning strategies. Additionally, it would be valuable to investigate the model's performance on a wider range of geographic regions and use cases, to better understand its real-world applicability and potential biases.
Conclusion
The PIGEON paper presents a novel approach to the problem of image geolocalization, leveraging multi-task learning and meta-learning techniques to improve the accuracy and robustness of location prediction. The proposed system demonstrates promising results on benchmark datasets, highlighting the potential of this approach for applications in areas such as augmented reality, urban planning, and travel planning.
While the paper acknowledges some limitations, the overall research direction is compelling and could lead to further advancements in the field of computer vision and spatial understanding. As the ability to accurately geolocate images becomes increasingly important in our digital world, the PIGEON method represents a valuable contribution to the ongoing efforts to address this challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Regional biases in image geolocation estimation: a case study with the SenseCity Africa dataset
Ximena Salgado Uribe, Mart'i Bosch, J'er^ome Chenal
0
0
Advances in Artificial Intelligence are challenged by the biases rooted in the datasets used to train the models. In image geolocation estimation, models are mostly trained using data from specific geographic regions, notably the Western world, and as a result, they may struggle to comprehend the complexities of underrepresented regions. To assess this issue, we apply a state-of-the-art image geolocation estimation model (ISNs) to a crowd-sourced dataset of geolocated images from the African continent (SCA100), and then explore the regional and socioeconomic biases underlying the model's predictions. Our findings show that the ISNs model tends to over-predict image locations in high-income countries of the Western world, which is consistent with the geographic distribution of its training data, i.e., the IM2GPS3k dataset. Accordingly, when compared to the IM2GPS3k benchmark, the accuracy of the ISNs model notably decreases at all scales. Additionally, we cluster images of the SCA100 dataset based on how accurately they are predicted by the ISNs model and show the model's difficulties in correctly predicting the locations of images in low income regions, especially in Sub-Saharan Africa. Therefore, our results suggest that using IM2GPS3k as a training set and benchmark for image geolocation estimation and other computer vision models overlooks its potential application in the African context.
4/4/2024
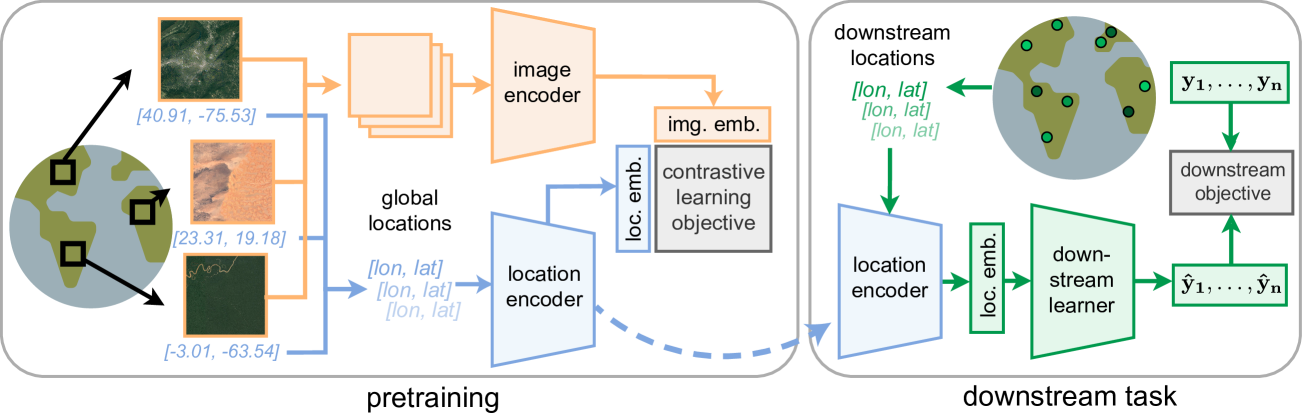
SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
Konstantin Klemmer, Esther Rolf, Caleb Robinson, Lester Mackey, Marc Ru{ss}wurm
0
0
Geographic information is essential for modeling tasks in fields ranging from ecology to epidemiology. However, extracting relevant location characteristics for a given task can be challenging, often requiring expensive data fusion or distillation from massive global imagery datasets. To address this challenge, we introduce Satellite Contrastive Location-Image Pretraining (SatCLIP). This global, general-purpose geographic location encoder learns an implicit representation of locations by matching CNN and ViT inferred visual patterns of openly available satellite imagery with their geographic coordinates. The resulting SatCLIP location encoder efficiently summarizes the characteristics of any given location for convenient use in downstream tasks. In our experiments, we use SatCLIP embeddings to improve prediction performance on nine diverse location-dependent tasks including temperature prediction, animal recognition, and population density estimation. Across tasks, SatCLIP consistently outperforms alternative location encoders and improves geographic generalization by encoding visual similarities of spatially distant environments. These results demonstrate the potential of vision-location models to learn meaningful representations of our planet from the vast, varied, and largely untapped modalities of geospatial data.
4/16/2024
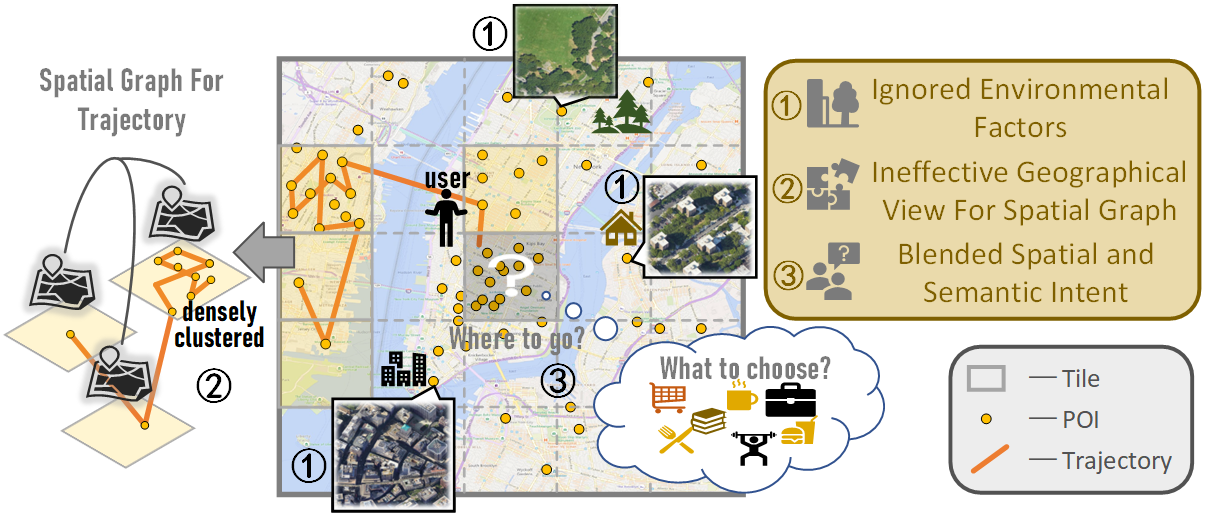
Towards Effective Next POI Prediction: Spatial and Semantic Augmentation with Remote Sensing Data
Nan Jiang, Haitao Yuan, Jianing Si, Minxiao Chen, Shangguang Wang
0
0
The next point-of-interest (POI) prediction is a significant task in location-based services, yet its complexity arises from the consolidation of spatial and semantic intent. This fusion is subject to the influences of historical preferences, prevailing location, and environmental factors, thereby posing significant challenges. In addition, the uneven POI distribution further complicates the next POI prediction procedure. To address these challenges, we enrich input features and propose an effective deep-learning method within a two-step prediction framework. Our method first incorporates remote sensing data, capturing pivotal environmental context to enhance input features regarding both location and semantics. Subsequently, we employ a region quad-tree structure to integrate urban remote sensing, road network, and POI distribution spaces, aiming to devise a more coherent graph representation method for urban spatial. Leveraging this method, we construct the QR-P graph for the user's historical trajectories to encapsulate historical travel knowledge, thereby augmenting input features with comprehensive spatial and semantic insights. We devise distinct embedding modules to encode these features and employ an attention mechanism to fuse diverse encodings. In the two-step prediction procedure, we initially identify potential spatial zones by predicting user-preferred tiles, followed by pinpointing specific POIs of a designated type within the projected tiles. Empirical findings from four real-world location-based social network datasets underscore the remarkable superiority of our proposed approach over competitive baseline methods.
4/9/2024
✨
OpenStreetView-5M: The Many Roads to Global Visual Geolocation
Guillaume Astruc, Nicolas Dufour, Ioannis Siglidis, Constantin Aronssohn, Nacim Bouia, Stephanie Fu, Romain Loiseau, Van Nguyen Nguyen, Charles Raude, Elliot Vincent, Lintao XU, Hongyu Zhou, Loic Landrieu
0
0
Determining the location of an image anywhere on Earth is a complex visual task, which makes it particularly relevant for evaluating computer vision algorithms. Yet, the absence of standard, large-scale, open-access datasets with reliably localizable images has limited its potential. To address this issue, we introduce OpenStreetView-5M, a large-scale, open-access dataset comprising over 5.1 million geo-referenced street view images, covering 225 countries and territories. In contrast to existing benchmarks, we enforce a strict train/test separation, allowing us to evaluate the relevance of learned geographical features beyond mere memorization. To demonstrate the utility of our dataset, we conduct an extensive benchmark of various state-of-the-art image encoders, spatial representations, and training strategies. All associated codes and models can be found at https://github.com/gastruc/osv5m.
4/30/2024