AUG: A New Dataset and An Efficient Model for Aerial Image Urban Scene Graph Generation

0
Sign in to get full access
Overview
- This paper introduces a new dataset, called AUG, for aerial image urban scene graph generation.
- The authors also propose an efficient model based on graph convolutional networks for detecting relationships between objects in aerial urban images.
Plain English Explanation
The paper focuses on a task called "scene graph generation" from aerial images of urban areas. Scene graphs are visual representations that show the objects in an image and the relationships between them. For example, a scene graph might show that there is a "car" near a "building" and the "car" is "parked on" the "road".
The researchers first created a new dataset called AUG, which stands for Aerial Urban Graphs. This dataset contains aerial images of cities along with annotated scene graphs. Having a high-quality dataset like this is important for training machine learning models to perform scene graph generation.
The researchers then developed a new model based on graph convolutional networks to efficiently detect the objects and relationships in the aerial images. Their model is designed to work well with the unique challenges of aerial imagery, such as the large scale and complex perspectives.
Overall, this work advances the field of scene understanding from aerial images, which has important applications in areas like urban planning, autonomous navigation, and disaster response.
Technical Explanation
The key technical contributions of the paper are:
-
The AUG dataset: The authors created a new dataset of aerial urban images with annotated scene graphs. This dataset contains over 5,000 images and is significantly larger and more diverse than previous aerial scene graph datasets.
-
An efficient scene graph generation model: The authors propose a graph convolutional network-based model that can efficiently detect objects and their relationships in aerial urban images. Their model outperforms previous approaches on the AUG dataset.
The model takes an aerial image as input and produces a scene graph as output. It has three main components:
- An object detection module to identify the objects in the image
- A relationship detection module to determine the relationships between the objects
- A graph reasoning module that assembles the detected objects and relationships into a coherent scene graph
The authors show that their model achieves state-of-the-art performance on the AUG dataset, while being more efficient than previous approaches.
Critical Analysis
The paper makes a valuable contribution by introducing the AUG dataset, which provides a useful benchmark for evaluating aerial scene graph generation models. The authors also present a strong technical approach that advances the state-of-the-art in this area.
However, the paper does not extensively discuss the limitations of the AUG dataset or the proposed model. For example, the dataset may not cover all types of urban environments, and the model's performance may degrade on very large or complex scenes. Additionally, the paper does not explore how the scene graphs generated by the model could be used in downstream applications, such as urban planning or autonomous navigation.
Further research could investigate ways to make the scene graph generation model more robust and generalizable, as well as explore novel use cases for the generated scene graphs. Incorporating additional context, such as street-level imagery or GIS data, could also be a promising direction for improving urban scene understanding.
Conclusion
This paper introduces a new dataset and an efficient model for generating scene graphs from aerial images of urban areas. The AUG dataset provides a valuable resource for advancing research in this domain, and the proposed graph convolutional network-based model demonstrates state-of-the-art performance. While the paper has some limitations, it represents an important step forward in the field of aerial image understanding, with potential applications in urban planning, autonomous navigation, and other domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AUG: A New Dataset and An Efficient Model for Aerial Image Urban Scene Graph Generation
Yansheng Li, Kun Li, Yongjun Zhang, Linlin Wang, Dingwen Zhang
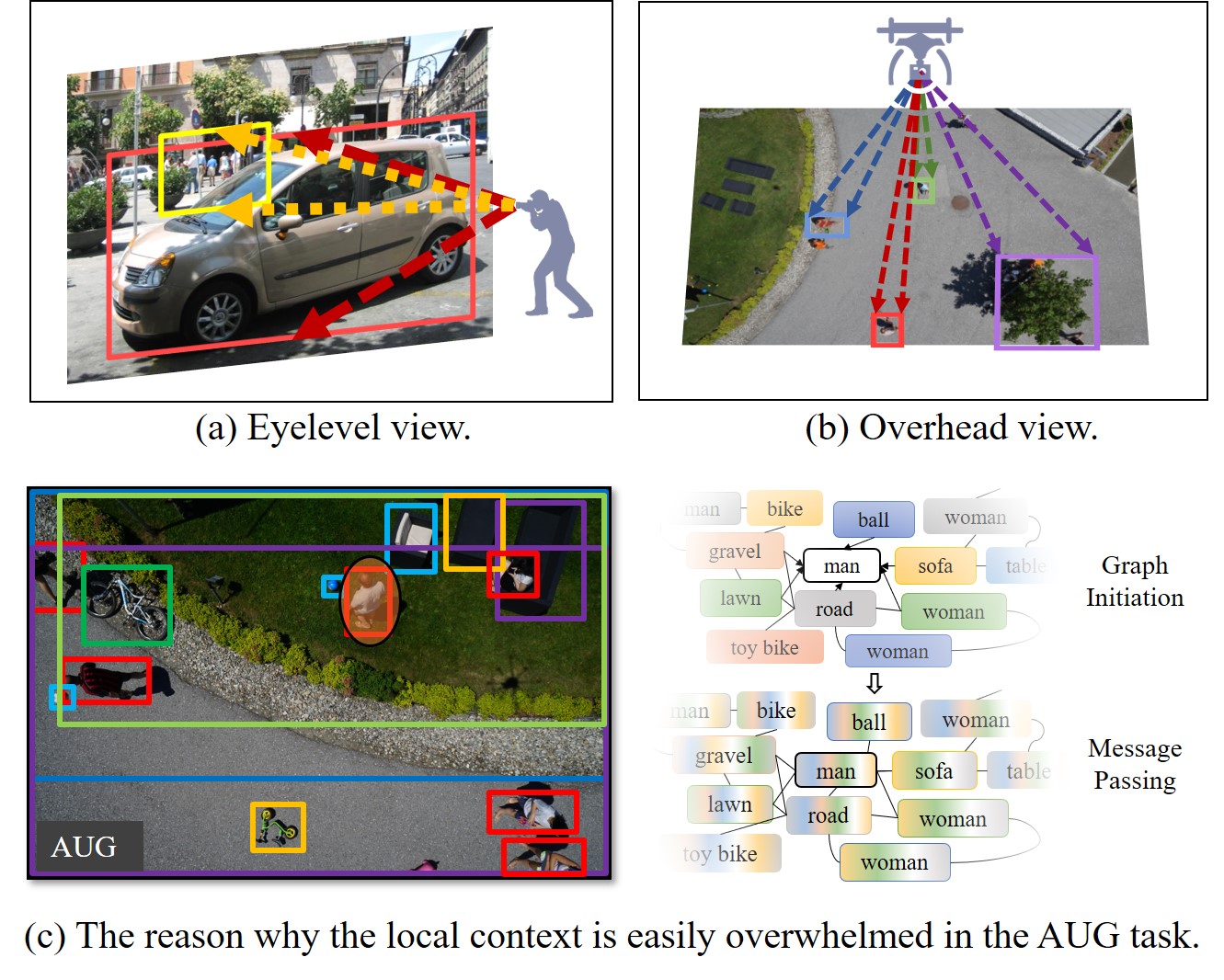
Scene graph generation (SGG) aims to understand the visual objects and their semantic relationships from one given image. Until now, lots of SGG datasets with the eyelevel view are released but the SGG dataset with the overhead view is scarcely studied. By contrast to the object occlusion problem in the eyelevel view, which impedes the SGG, the overhead view provides a new perspective that helps to promote the SGG by providing a clear perception of the spatial relationships of objects in the ground scene. To fill in the gap of the overhead view dataset, this paper constructs and releases an aerial image urban scene graph generation (AUG) dataset. Images from the AUG dataset are captured with the low-attitude overhead view. In the AUG dataset, 25,594 objects, 16,970 relationships, and 27,175 attributes are manually annotated. To avoid the local context being overwhelmed in the complex aerial urban scene, this paper proposes one new locality-preserving graph convolutional network (LPG). Different from the traditional graph convolutional network, which has the natural advantage of capturing the global context for SGG, the convolutional layer in the LPG integrates the non-destructive initial features of the objects with dynamically updated neighborhood information to preserve the local context under the premise of mining the global context. To address the problem that there exists an extra-large number of potential object relationship pairs but only a small part of them is meaningful in AUG, we propose the adaptive bounding box scaling factor for potential relationship detection (ABS-PRD) to intelligently prune the meaningless relationship pairs. Extensive experiments on the AUG dataset show that our LPG can significantly outperform the state-of-the-art methods and the effectiveness of the proposed locality-preserving strategy.
Read more4/12/2024

0
Scene Graph Generation in Large-Size VHR Satellite Imagery: A Large-Scale Dataset and A Context-Aware Approach
Yansheng Li, Linlin Wang, Tingzhu Wang, Xue Yang, Junwei Luo, Qi Wang, Youming Deng, Wenbin Wang, Xian Sun, Haifeng Li, Bo Dang, Yongjun Zhang, Yi Yu, Junchi Yan
Scene graph generation (SGG) in satellite imagery (SAI) benefits promoting understanding of geospatial scenarios from perception to cognition. In SAI, objects exhibit great variations in scales and aspect ratios, and there exist rich relationships between objects (even between spatially disjoint objects), which makes it attractive to holistically conduct SGG in large-size very-high-resolution (VHR) SAI. However, there lack such SGG datasets. Due to the complexity of large-size SAI, mining triplets heavily relies on long-range contextual reasoning. Consequently, SGG models designed for small-size natural imagery are not directly applicable to large-size SAI. This paper constructs a large-scale dataset for SGG in large-size VHR SAI with image sizes ranging from 512 x 768 to 27,860 x 31,096 pixels, named STAR (Scene graph generaTion in lArge-size satellite imageRy), encompassing over 210K objects and over 400K triplets. To realize SGG in large-size SAI, we propose a context-aware cascade cognition (CAC) framework to understand SAI regarding object detection (OBD), pair pruning and relationship prediction for SGG. We also release a SAI-oriented SGG toolkit with about 30 OBD and 10 SGG methods which need further adaptation by our devised modules on our challenging STAR dataset. The dataset and toolkit are available at: https://linlin-dev.github.io/project/STAR.
Read more7/4/2024
0
Adaptive Visual Scene Understanding: Incremental Scene Graph Generation
Naitik Khandelwal, Xiao Liu, Mengmi Zhang
Scene graph generation (SGG) involves analyzing images to extract meaningful information about objects and their relationships. Given the dynamic nature of the visual world, it becomes crucial for AI systems to detect new objects and establish their new relationships with existing objects. To address the lack of continual learning methodologies in SGG, we introduce the comprehensive Continual ScenE Graph Generation (CSEGG) dataset along with 3 learning scenarios and 8 evaluation metrics. Our research investigates the continual learning performances of existing SGG methods on the retention of previous object entities and relationships as they learn new ones. Moreover, we also explore how continual object detection enhances generalization in classifying known relationships on unknown objects. We conduct extensive experiments benchmarking and analyzing the classical two-stage SGG methods and the most recent transformer-based SGG methods in continual learning settings, and gain valuable insights into the CSEGG problem. We invite the research community to explore this emerging field of study.
Read more4/15/2024
0
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Rongjie Li, Songyang Zhang, Dahua Lin, Kai Chen, Xuming He
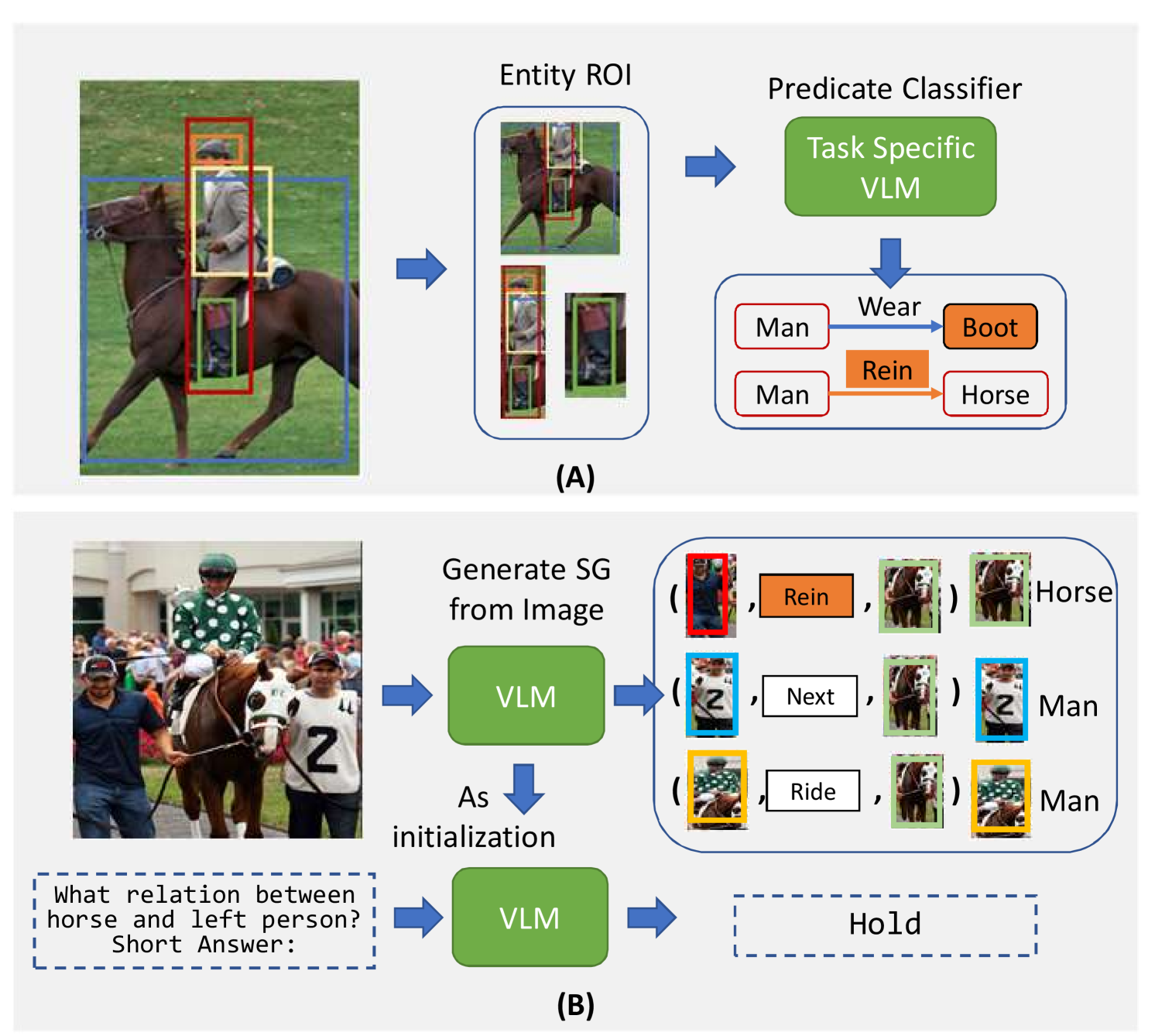
Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Read more4/9/2024