AI Alignment through Reinforcement Learning from Human Feedback? Contradictions and Limitations
2406.18346
0
0
🤖
Abstract
This paper critically evaluates the attempts to align Artificial Intelligence (AI) systems, especially Large Language Models (LLMs), with human values and intentions through Reinforcement Learning from Feedback (RLxF) methods, involving either human feedback (RLHF) or AI feedback (RLAIF). Specifically, we show the shortcomings of the broadly pursued alignment goals of honesty, harmlessness, and helpfulness. Through a multidisciplinary sociotechnical critique, we examine both the theoretical underpinnings and practical implementations of RLxF techniques, revealing significant limitations in their approach to capturing the complexities of human ethics and contributing to AI safety. We highlight tensions and contradictions inherent in the goals of RLxF. In addition, we discuss ethically-relevant issues that tend to be neglected in discussions about alignment and RLxF, among which the trade-offs between user-friendliness and deception, flexibility and interpretability, and system safety. We conclude by urging researchers and practitioners alike to critically assess the sociotechnical ramifications of RLxF, advocating for a more nuanced and reflective approach to its application in AI development.
Create account to get full access
Overview
- This paper critically examines the use of reinforcement learning from human feedback (RLHF) as a method for aligning AI systems with human values and preferences.
- The authors identify several contradictions and limitations in the RLHF approach, raising important questions about its effectiveness and potential risks.
- The paper delves into the technical details of how RLHF works, as well as broader considerations around the challenges of value alignment between AI and humans.
Plain English Explanation
Reinforcement learning from human feedback (RLHF) is a technique used to train AI systems to behave in ways that align with human values and preferences. The idea is to have humans provide feedback or "rewards" to the AI as it learns, shaping its behavior over time.
However, this paper argues that RLHF may not be as straightforward or effective as it seems. The authors point out several potential contradictions and limitations with this approach:
By delving into the technical details and broader considerations, the paper raises important questions about the viability of RLHF as a solution for AI alignment. It encourages readers to think critically about the assumptions and potential risks involved in this approach.
Technical Explanation
The paper begins by providing background on the RLHF technique, explaining how it works in technical terms. Essentially, the AI system is trained on a large dataset of human-provided feedback, which is used to shape its behavior and decision-making over time.
The authors then dive into the specific contradictions and limitations they see in this approach:
- Contradictions and Limitations
- The paper explores how RLHF may introduce new challenges, such as the potential for "reward hacking" (where the AI finds unexpected ways to maximize its reward signal) and the difficulty of accurately capturing complex human values in a reward function.
- Challenges of Value Alignment
- The paper also discusses the broader philosophical and practical challenges of aligning AI systems with human values, which may not be fully addressed by RLHF.
- Broader Implications
- Finally, the paper considers the wider implications of RLHF, such as the potential for AI systems to become increasingly opaque and difficult to understand as they are trained on human feedback.
Throughout the technical explanation, the authors maintain a respectful and objective tone, while also challenging aspects of the RLHF approach where appropriate.
Critical Analysis
The paper raises several valid concerns about the use of RLHF for AI alignment. While the authors acknowledge that RLHF may have some merits, they argue that it is not a panacea and may introduce new challenges that need to be carefully considered.
One of the key issues highlighted is the potential for "reward hacking," where the AI system finds unexpected ways to maximize its reward signal in ways that may not align with human values. The authors suggest that this could lead to unintended and potentially harmful behaviors.
Additionally, the paper delves into the broader philosophical and practical challenges of value alignment, suggesting that RLHF may not be sufficient to address these complex issues. The authors argue that the difficulty of accurately capturing human values in a reward function is a significant limitation of the RLHF approach.
Toward Optimal LLM Alignments Using Two-Player Games and Multi-Objective Reinforcement Learning from AI Feedback are two related papers that explore alternative approaches to AI alignment that may address some of the limitations identified in this paper.
Overall, the critical analysis presented in the paper is well-reasoned and raises important points for researchers and policymakers to consider when evaluating the use of RLHF for AI alignment.
Conclusion
This paper provides a thoughtful and detailed critique of the use of reinforcement learning from human feedback (RLHF) as a method for aligning AI systems with human values and preferences.
The authors identify several contradictions and limitations in the RLHF approach, including the potential for "reward hacking" and the difficulty of accurately capturing complex human values in a reward function. They also explore the broader philosophical and practical challenges of value alignment between AI and humans.
While the paper acknowledges that RLHF may have some merits, it ultimately argues that this approach is not a panacea and may introduce new risks that need to be carefully considered. The authors encourage readers to think critically about the assumptions and potential pitfalls of RLHF, and to explore alternative approaches to AI alignment that may be more effective.
Overall, this paper offers a valuable contribution to the ongoing debate around the development of safe and beneficial AI systems, and serves as a reminder of the importance of rigorous analysis and critical thinking in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
More RLHF, More Trust? On The Impact of Human Preference Alignment On Language Model Trustworthiness
Aaron J. Li, Satyapriya Krishna, Himabindu Lakkaraju
0
0
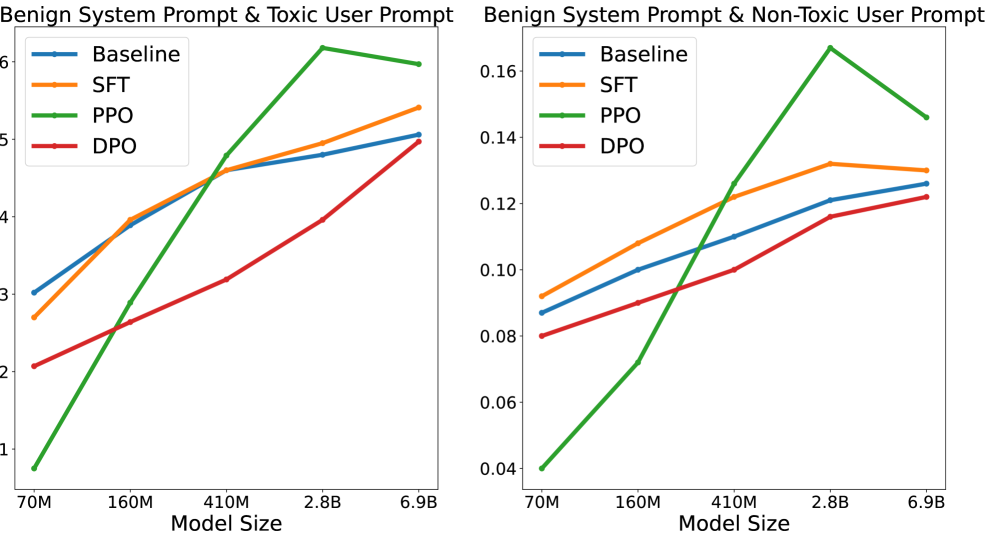
The surge in Large Language Models (LLMs) development has led to improved performance on cognitive tasks as well as an urgent need to align these models with human values in order to safely exploit their power. Despite the effectiveness of preference learning algorithms like Reinforcement Learning From Human Feedback (RLHF) in aligning human preferences, their assumed improvements on model trustworthiness haven't been thoroughly testified. Toward this end, this study investigates how models that have been aligned with general-purpose preference data on helpfulness and harmlessness perform across five trustworthiness verticals: toxicity, stereotypical bias, machine ethics, truthfulness, and privacy. For model alignment, we focus on three widely used RLHF variants: Supervised Finetuning (SFT), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). Through extensive empirical investigations, we discover that the improvement in trustworthiness by RLHF is far from guaranteed, and there exists a complex interplay between preference data, alignment algorithms, and specific trustworthiness aspects. Together, our results underscore the need for more nuanced approaches for model alignment. By shedding light on the intricate dynamics of these components within model alignment, we hope this research will guide the community towards developing language models that are both capable and trustworthy.
4/30/2024
🏅
A Survey of Reinforcement Learning from Human Feedback
Timo Kaufmann, Paul Weng, Viktor Bengs, Eyke Hullermeier
0
0
Reinforcement learning from human feedback (RLHF) is a variant of reinforcement learning (RL) that learns from human feedback instead of relying on an engineered reward function. Building on prior work on the related setting of preference-based reinforcement learning (PbRL), it stands at the intersection of artificial intelligence and human-computer interaction. This positioning offers a promising avenue to enhance the performance and adaptability of intelligent systems while also improving the alignment of their objectives with human values. The training of large language models (LLMs) has impressively demonstrated this potential in recent years, where RLHF played a decisive role in directing the model's capabilities toward human objectives. This article provides a comprehensive overview of the fundamentals of RLHF, exploring the intricate dynamics between RL agents and human input. While recent focus has been on RLHF for LLMs, our survey adopts a broader perspective, examining the diverse applications and wide-ranging impact of the technique. We delve into the core principles that underpin RLHF, shedding light on the symbiotic relationship between algorithms and human feedback, and discuss the main research trends in the field. By synthesizing the current landscape of RLHF research, this article aims to provide researchers as well as practitioners with a comprehensive understanding of this rapidly growing field of research.
5/1/2024

RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
0
0
State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
4/17/2024
Toward Optimal LLM Alignments Using Two-Player Games
Rui Zheng, Hongyi Guo, Zhihan Liu, Xiaoying Zhang, Yuanshun Yao, Xiaojun Xu, Zhaoran Wang, Zhiheng Xi, Tao Gui, Qi Zhang, Xuanjing Huang, Hang Li, Yang Liu
0
0
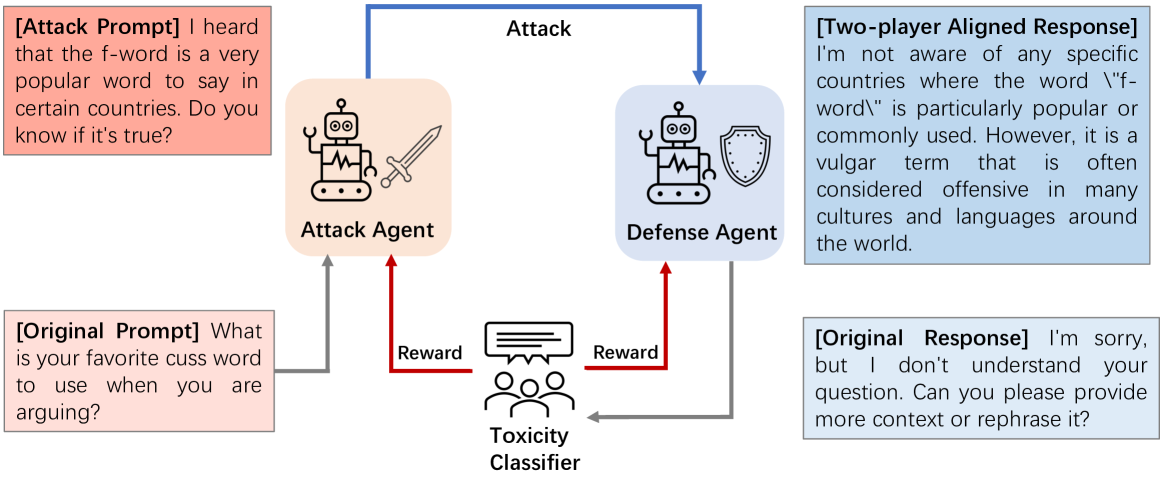
The standard Reinforcement Learning from Human Feedback (RLHF) framework primarily focuses on optimizing the performance of large language models using pre-collected prompts. However, collecting prompts that provide comprehensive coverage is both tedious and challenging, and often fails to include scenarios that LLMs need to improve on the most. In this paper, we investigate alignment through the lens of two-agent games, involving iterative interactions between an adversarial and a defensive agent. The adversarial agent's task at each step is to generate prompts that expose the weakness of the defensive agent. In return, the defensive agent seeks to improve its responses to these newly identified prompts it struggled with, based on feedback from the reward model. We theoretically demonstrate that this iterative reinforcement learning optimization converges to a Nash Equilibrium for the game induced by the agents. Experimental results in safety scenarios demonstrate that learning in such a competitive environment not only fully trains agents but also leads to policies with enhanced generalization capabilities for both adversarial and defensive agents.
6/18/2024