AI-Augmented Surveys: Leveraging Large Language Models and Surveys for Opinion Prediction
2305.09620
0
0
💬
Abstract
Large language models (LLMs) that produce human-like responses have begun to revolutionize research practices in the social sciences. We develop a novel methodological framework that fine-tunes LLMs with repeated cross-sectional surveys to incorporate the meaning of survey questions, individual beliefs, and temporal contexts for opinion prediction. We introduce two new emerging applications of the AI-augmented survey: retrodiction (i.e., predict year-level missing responses) and unasked opinion prediction (i.e., predict entirely missing responses). Among 3,110 binarized opinions from 68,846 Americans in the General Social Survey from 1972 to 2021, our models based on Alpaca-7b excel in retrodiction (AUC = 0.86 for personal opinion prediction, $rho$ = 0.98 for public opinion prediction). These remarkable prediction capabilities allow us to fill in missing trends with high confidence and pinpoint when public attitudes changed, such as the rising support for same-sex marriage. On the other hand, our fine-tuned Alpaca-7b models show modest success in unasked opinion prediction (AUC = 0.73, $rho$ = 0.67). We discuss practical constraints and ethical concerns regarding individual autonomy and privacy when using LLMs for opinion prediction. Our study demonstrates that LLMs and surveys can mutually enhance each other's capabilities: LLMs can broaden survey potential, while surveys can improve the alignment of LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research explores how large language models (LLMs) can be used to enhance survey research in the social sciences.
- The researchers develop a novel method that fine-tunes LLMs on survey data to incorporate the meaning of survey questions, individual beliefs, and temporal contexts for opinion prediction.
- The paper introduces two new applications of this AI-augmented survey approach: retrodiction (predicting missing past responses) and unasked opinion prediction (forecasting entirely missing responses).
- The researchers find that their fine-tuned Alpaca-7b model excels at retrodiction, but shows more modest success at unasked opinion prediction.
- The paper discusses the practical and ethical considerations of using LLMs for opinion prediction, highlighting both the potential benefits and risks.
Plain English Explanation
The paper explores how large language models (LLMs) - AI systems that can generate human-like text - can be used to enhance social science research, specifically survey-based opinion polling. The researchers developed a new approach that fine-tunes or customizes an LLM using survey data. This allows the LLM to "understand" the meaning of survey questions, individual beliefs, and how opinions change over time.
The researchers then use this customized LLM to tackle two new applications. Retrodiction involves using the LLM to predict missing past survey responses, essentially "filling in the gaps" in existing data. Unasked opinion prediction goes even further, using the LLM to forecast entirely new opinions that were never surveyed.
The results show the LLM-based approach is very good at retrodiction, able to accurately predict missing past opinions. However, the unasked opinion predictions are more modest in their accuracy. The paper also discusses the practical challenges and ethical concerns around using LLMs for opinion prediction, such as protecting individual privacy and autonomy.
Overall, the research demonstrates how LLMs and surveys can work together to enhance each other's capabilities. Surveys can improve the alignment of LLMs with real-world beliefs and opinions, while LLMs can help expand the reach and potential of survey research.
Technical Explanation
The researchers developed a novel methodological framework that fine-tunes large language models (LLMs) using repeated cross-sectional survey data. This allows the LLMs to incorporate the meaning of survey questions, individual beliefs, and temporal contexts when predicting opinions.
Specifically, the team fine-tuned the Alpaca-7b LLM on data from the General Social Survey, which surveyed over 68,000 Americans on 3,110 binary opinion questions from 1972 to 2021. Their fine-tuned Alpaca-7b model demonstrated strong performance in retrodiction, achieving an AUC of 0.86 for predicting individuals' personal opinions and a correlation of 0.98 for predicting aggregate public opinions.
These remarkable retrodiction capabilities allow the researchers to fill in missing historical trends and pinpoint when public attitudes changed, such as the rising support for same-sex marriage. However, the model showed more modest success in unasked opinion prediction, with an AUC of 0.73 and correlation of 0.67.
The paper discusses the practical constraints and ethical concerns around using LLMs for opinion prediction, such as issues of individual privacy and autonomy. Overall, the study demonstrates the potential for LLMs and surveys to mutually enhance each other's capabilities.
Critical Analysis
The paper presents a compelling and well-designed study on using LLMs to enhance social science research. The researchers' approach of fine-tuning the Alpaca-7b model on survey data is a novel and promising technique. Their ability to achieve such high accuracy in retrodicting missing historical opinions is particularly impressive.
However, the more modest performance in unasked opinion prediction highlights the challenges in using LLMs to forecast entirely new opinions that were never surveyed. This suggests there are still limitations in the model's ability to fully capture the nuances and context-dependent nature of human beliefs and preferences.
The paper also raises important ethical considerations around the use of LLMs for opinion prediction. While the technology has significant potential benefits, there are valid concerns about protecting individual privacy and autonomy. Careful thought and safeguards will be needed to ensure these systems are deployed responsibly and with the full consent of research participants.
Overall, this research represents an important step forward in exploring how LLMs can enable better survey research and autonomous agents. The findings are promising, but also highlight the need for further research and dialogue around the practical and ethical implications of this technology.
Conclusion
This study demonstrates the potential for large language models (LLMs) to revolutionize social science research, particularly in the realm of survey-based opinion polling. By fine-tuning an LLM on survey data, the researchers were able to develop a powerful tool for predicting missing historical opinions and even forecasting entirely new, unasked opinions.
The implications of this work are significant, as it opens up new possibilities for enhancing survey research with LLMs and exploring the potential of autonomous agents. However, the research also highlights the need to carefully consider the practical constraints and ethical concerns around using such powerful AI systems for opinion prediction.
Overall, this study represents an important step forward in the integration of LLMs and survey research, demonstrating the mutually beneficial relationship between these two domains. As the technology continues to evolve, it will be crucial to ensure it is deployed responsibly and with the full participation and consent of research subjects.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models (LLMs) as Agents for Augmented Democracy
Jairo Gudi~no-Rosero, Umberto Grandi, C'esar A. Hidalgo
0
0
We explore the capabilities of an augmented democracy system built on off-the-shelf LLMs fine-tuned on data summarizing individual preferences across 67 policy proposals collected during the 2022 Brazilian presidential elections. We use a train-test cross-validation setup to estimate the accuracy with which the LLMs predict both: a subject's individual political choices and the aggregate preferences of the full sample of participants. At the individual level, the accuracy of the out of sample predictions lie in the range 69%-76% and are significantly better at predicting the preferences of liberal and college educated participants. At the population level, we aggregate preferences using an adaptation of the Borda score and compare the ranking of policy proposals obtained from a probabilistic sample of participants and from data augmented using LLMs. We find that the augmented data predicts the preferences of the full population of participants better than probabilistic samples alone when these represent less than 30% to 40% of the total population. These results indicate that LLMs are potentially useful for the construction of systems of augmented democracy.
5/8/2024
💬
A Survey on Large Language Model based Autonomous Agents
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen
0
0
Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and thus makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of web knowledge, large language models (LLMs) have demonstrated remarkable potential in achieving human-level intelligence. This has sparked an upsurge in studies investigating LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of the field of LLM-based autonomous agents from a holistic perspective. More specifically, we first discuss the construction of LLM-based autonomous agents, for which we propose a unified framework that encompasses a majority of the previous work. Then, we present a comprehensive overview of the diverse applications of LLM-based autonomous agents in the fields of social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field. To keep track of this field and continuously update our survey, we maintain a repository of relevant references at https://github.com/Paitesanshi/LLM-Agent-Survey.
4/5/2024

Towards Measuring the Representation of Subjective Global Opinions in Language Models
Esin Durmus, Karina Nguyen, Thomas I. Liao, Nicholas Schiefer, Amanda Askell, Anton Bakhtin, Carol Chen, Zac Hatfield-Dodds, Danny Hernandez, Nicholas Joseph, Liane Lovitt, Sam McCandlish, Orowa Sikder, Alex Tamkin, Janel Thamkul, Jared Kaplan, Jack Clark, Deep Ganguli
0
0
Large language models (LLMs) may not equitably represent diverse global perspectives on societal issues. In this paper, we develop a quantitative framework to evaluate whose opinions model-generated responses are more similar to. We first build a dataset, GlobalOpinionQA, comprised of questions and answers from cross-national surveys designed to capture diverse opinions on global issues across different countries. Next, we define a metric that quantifies the similarity between LLM-generated survey responses and human responses, conditioned on country. With our framework, we run three experiments on an LLM trained to be helpful, honest, and harmless with Constitutional AI. By default, LLM responses tend to be more similar to the opinions of certain populations, such as those from the USA, and some European and South American countries, highlighting the potential for biases. When we prompt the model to consider a particular country's perspective, responses shift to be more similar to the opinions of the prompted populations, but can reflect harmful cultural stereotypes. When we translate GlobalOpinionQA questions to a target language, the model's responses do not necessarily become the most similar to the opinions of speakers of those languages. We release our dataset for others to use and build on. Our data is at https://huggingface.co/datasets/Anthropic/llm_global_opinions. We also provide an interactive visualization at https://llmglobalvalues.anthropic.com.
4/15/2024
Large Language Models Show Human-like Social Desirability Biases in Survey Responses
Aadesh Salecha, Molly E. Ireland, Shashanka Subrahmanya, Jo~ao Sedoc, Lyle H. Ungar, Johannes C. Eichstaedt
0
0
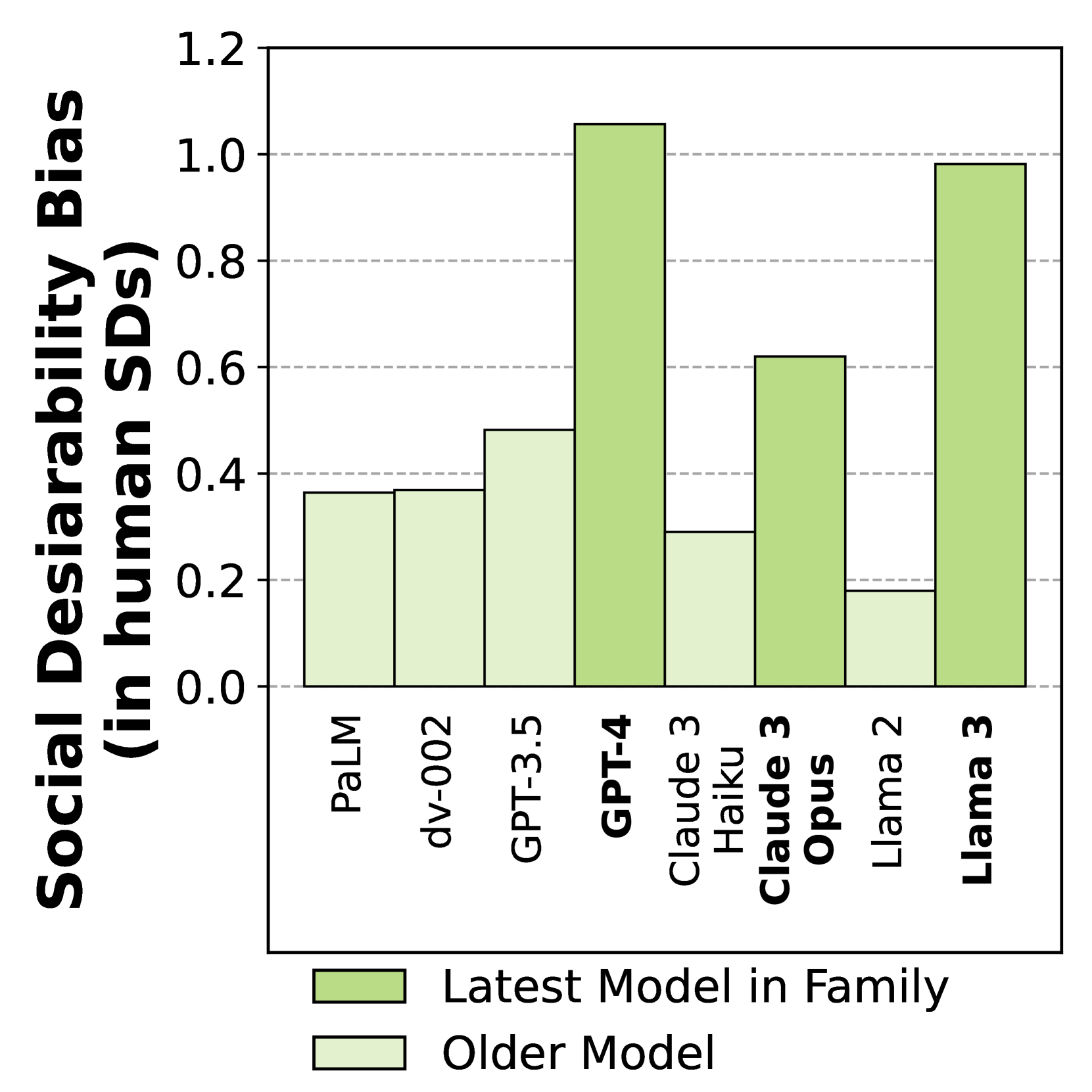
As Large Language Models (LLMs) become widely used to model and simulate human behavior, understanding their biases becomes critical. We developed an experimental framework using Big Five personality surveys and uncovered a previously undetected social desirability bias in a wide range of LLMs. By systematically varying the number of questions LLMs were exposed to, we demonstrate their ability to infer when they are being evaluated. When personality evaluation is inferred, LLMs skew their scores towards the desirable ends of trait dimensions (i.e., increased extraversion, decreased neuroticism, etc). This bias exists in all tested models, including GPT-4/3.5, Claude 3, Llama 3, and PaLM-2. Bias levels appear to increase in more recent models, with GPT-4's survey responses changing by 1.20 (human) standard deviations and Llama 3's by 0.98 standard deviations-very large effects. This bias is robust to randomization of question order and paraphrasing. Reverse-coding all the questions decreases bias levels but does not eliminate them, suggesting that this effect cannot be attributed to acquiescence bias. Our findings reveal an emergent social desirability bias and suggest constraints on profiling LLMs with psychometric tests and on using LLMs as proxies for human participants.
5/13/2024