Using LLMs to Model the Beliefs and Preferences of Targeted Populations
2403.20252
0
0

Abstract
We consider the problem of aligning a large language model (LLM) to model the preferences of a human population. Modeling the beliefs, preferences, and behaviors of a specific population can be useful for a variety of different applications, such as conducting simulated focus groups for new products, conducting virtual surveys, and testing behavioral interventions, especially for interventions that are expensive, impractical, or unethical. Existing work has had mixed success using LLMs to accurately model human behavior in different contexts. We benchmark and evaluate two well-known fine-tuning approaches and evaluate the resulting populations on their ability to match the preferences of real human respondents on a survey of preferences for battery electric vehicles (BEVs). We evaluate our models against their ability to match population-wide statistics as well as their ability to match individual responses, and we investigate the role of temperature in controlling the trade-offs between these two. Additionally, we propose and evaluate a novel loss term to improve model performance on responses that require a numeric response.
Get summaries of the top AI research delivered straight to your inbox:
Introduction
The paper discusses using large language models (LLMs) as statistical proxies to study human beliefs, preferences, and behaviors. Existing work shows conflicting results on whether LLMs can accurately model human behaviors. The paper aims to align LLM beliefs and preferences with real humans expressed in surveys.
The key contributions are:
-
Using battery-electric vehicle survey data, the authors demonstrate parameter-efficient fine-tuning techniques to improve LLM agreement with human preferences.
-
They investigate the effects of model size, finding larger pre-trained models perform best out-of-the-box, but this advantage diminishes after fine-tuning.
-
They explore quantization and sampling temperature, finding quantized fine-tuning provides computational savings with minimal degradation, and temperature allows trading off population-wide vs. per-individual response matching.
-
They propose a novel penalty term in the loss function to improve performance on numerical survey questions.
-
They benchmark against baseline algorithms trained on survey data, demonstrating fine-tuned LLMs can outperform them in specific settings.
The paper aims to arrive at interactive models for studying target populations, useful for applications like marketing, community simulations, and testing interventions when impractical or unethical in the real world.
Related Work
The provided text discusses the potential of large language models (LLMs) to simulate human behaviors, personalities, and judgments. Recent studies have demonstrated LLMs' ability to reliably simulate personalities, align with human moral judgments, and generate human-like behaviors in interactive environments. Initial attempts have been made to use LLMs as synthetic human participants in behavioral studies, reproducing findings from previous experiments with real participants. However, previous work has primarily focused on measuring concordance between LLMs and participant data, with some studies finding a lack of agreement in certain domains. The text introduces the authors' work, which provides a framework to align LLMs with human preferences and explores techniques to improve the level of agreement between LLMs and humans.
Background
The passage discusses auto-regressive large language models and techniques for fine-tuning them. Auto-regressive language models learn to predict the next token in a sequence of text, trained in an unsupervised manner on large natural language corpora. A common architecture is the transformer decoder with a causal mask.
To adapt these large pre-trained models to specific tasks like sentiment analysis or summarization, a common approach is fine-tuning, which updates all model parameters and can be computationally expensive for large models.
The paper introduces Low-Rank Adaptation (LoRA), a technique that freezes the pre-trained model weights and only trains low-rank matrices added throughout the model, dramatically reducing computational cost. Quantized LoRA (QLoRA) further quantizes model weights to 4-bit representations while preserving information, and employs memory optimization techniques.
Problem setting
This problem involves using a small amount of survey data from a representative sample of a target human population, along with available demographic information relevant to characterizing the population. The answer a_ij of a participant i with demographics x_i^d is generated from a probability distribution p(a|x_i^d, x_j^q), where x_j^q denotes the questionnaire j.
The specific example used is the EV-shift dataset, which examines the impact of interventions on people's preferences for electric vehicles (EVs) compared to internal combustion vehicles. The study aimed to identify how effectively different text-based interventions changed people's preferences for EVs.
In the study, subjects provided an initial preference rating for EVs on a 0-100 scale. They were then shown one of 35 text interventions aimed at increasing their EV preference. After the intervention, subjects provided a post-intervention preference rating, also on a 0-100 scale. Each subject also provided demographic information.
The dataset contains demographic information, initial and post-intervention preference ratings for 4,045 subjects, and the interventions seen by each subject (5 for most subjects).
Proposed method
The proposed approach generates virtual survey participants by prompting a fine-tuned language model (LLM) to produce responses that statistically match those of a target population.
Each virtual participant is implemented by prompting the LLM with demographic information to generate a token sequence representing the survey response. Formally, the virtual participants aim to model the conditional distribution p(y|x), where y is the generated token sequence (answer) and x is the token sequence representing the demographics and survey question.
The output sequence y is preprocessed by a function F to extract the intended answer a, which is useful when the expected answer has a specific structure (e.g. numerical rating, multiple choice). In the experiments, F simply extracts the first number appearing in the sequence as a basic implementation.
This section describes generating virtual participants with demographics drawn from any distribution to target specific populations. Prompts are used to set the characteristics of the virtual participant and survey preferences. The pre-trained language model is fine-tuned on survey data to emulate human preferences. A novel numerical penalty term is introduced to the loss function, providing feedback if the generated numerical response is close to the correct answer. Agreement between the language model and humans is measured using KL-divergence (for population statistics) and root mean square error (for individual responses).
Experiments
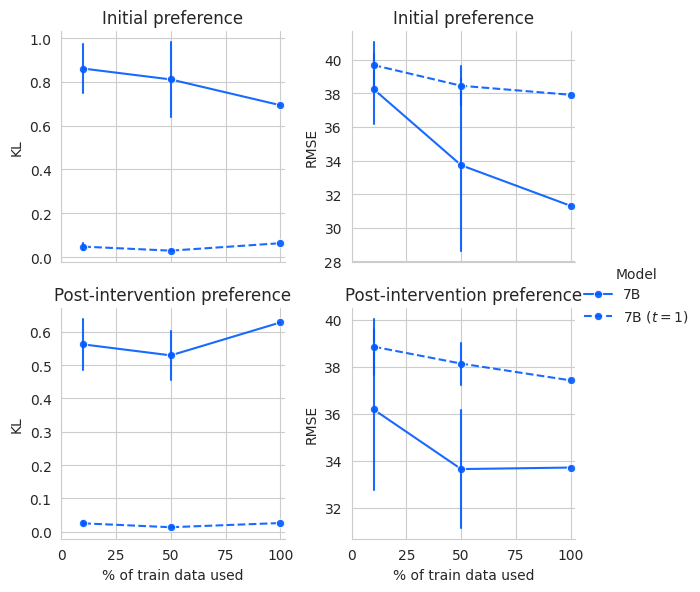
The paper explores the performance of fine-tuned language models on predicting individual preferences from demographic data. Several experiments were conducted using different model sizes (7B, 13B, 70B) and techniques (LoRA, QLoRA) of the Llama 2 model.
Key findings:
- Larger models (70B) generally had better performance in terms of lower KL divergence (population-level metric) but not necessarily lower RMSE (individual-level metric).
- Fine-tuning improved both KL divergence and RMSE compared to pre-trained models.
- QLoRA (quantized LoRA) performed similarly to LoRA, suggesting quantization has little impact on response quality.
- Varying the sampling temperature allowed trading off between KL divergence and RMSE. Higher temperatures improved KL divergence but worsened RMSE.
- Using a numerical penalty term during fine-tuning helped decrease both KL divergence and RMSE.
The paper benchmarked the language models against supervised learning methods (SVR, CatBoost) and found that while the language models did not outperform these baselines, they offer more versatility for natural language interactions.
Conclusions and Future Work
The paper investigates using large language models (LLMs) to model the beliefs and preferences of a human population. This can be useful for simulated focus groups, virtual surveys, or piloting interventions without involving real humans. Out-of-the-box pre-trained models perform poorly at predicting human survey responses, but LLMs can be fine-tuned to better model the target population. Larger models provide better performance, but this advantage shrinks after task-specific fine-tuning. Quantization has minimal impact on fine-tuning, confirming its viability for reducing computation costs. Sampling temperature allows trading off population-wide KL-divergence against per-individual RMSE. A penalty loss term improves performance on numerical output questions by providing additional training information about response correctness. While the approach demonstrates matching survey data, future work will study aligning the model to unseen behavioral scenarios.
Appendix A EV-Shift Survey Details
Table 6 presents the questionnaires used to collect demographic information from participants, along with the possible response options. Table 7 lists the intervention texts employed in the study, which likely aimed to influence participants' perceptions or behaviors related to electric vehicles.
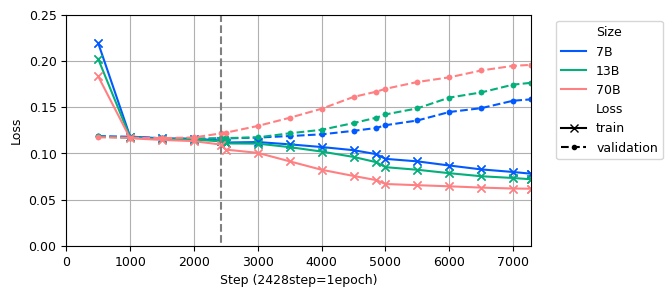
Appendix B Effects of model size
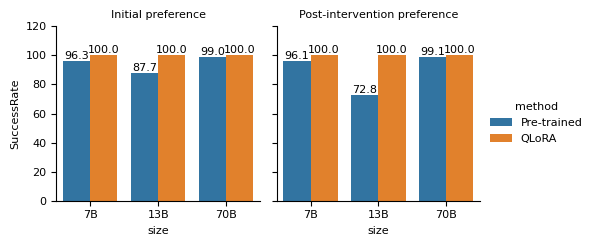
The QLoRA experiments showed that after 1 epoch, the validation loss increased, indicating overfitting. Larger model sizes led to faster decreases in train loss. The success rate for QLoRA on the test data was higher than the pre-trained model. An example sentence showed the pre-trained model tended to generate non-numerical tokens at the start of answers, lacking the ability to follow instructions to reply with only a number rating. While prompt engineering and in-context learning could improve the success rate, they were not the focus of this work.

Appendix C Quantization effects
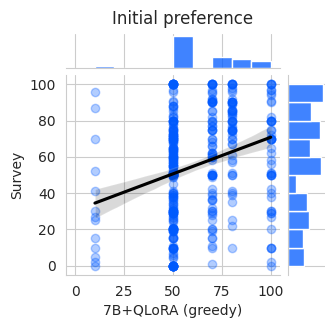
The paper discusses the answer distribution for QLoRA and LoRA models, as shown in Figure 7. While there is a high correlation between the two models, individual responses may differ. Figure 7 illustrates this correlation and variation in responses.
Appendix D Temperature effects
The paper compares the preference distributions resulting from different decoding strategies employed by the model. For greedy sampling, the model exhibited a tendency to respond with a specific value from the range of 0 to 100, indicating a concentrated preference distribution. In contrast, calibrated sampling led to increased variation in the responses, suggesting a more diverse preference distribution.
Appendix E Penalty term effects
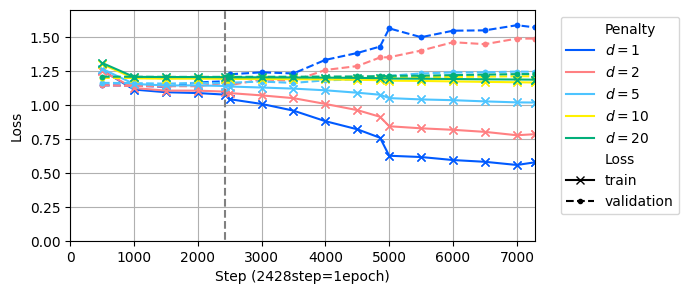
The paper discusses the learning curve and model performance with a penalty term. For the case with a penalty term, the validation loss begins increasing after 1 epoch, similar to the case with only the cross-entropy term. As the value of d is increased, the change in loss becomes smaller. This indicates that increasing d leads to higher weights for non-answer preference tokens, making it harder to decrease the loss compared to cross-entropy which evaluates the entire prompt.
Appendix F Amount of data effects
The paper examines the impact of varying the amount of training data on the model's performance on the test data. Figure 10 illustrates this effect. To maintain consistency with the 100% data volume case, the training epochs were set to 30 for 10% of the data and 6 for 50% of the data. The model checkpoints before the validation loss increased were used for evaluation. The results indicate that for some questionnaires, the KL divergence and RMSE improved as the volume of training data increased.
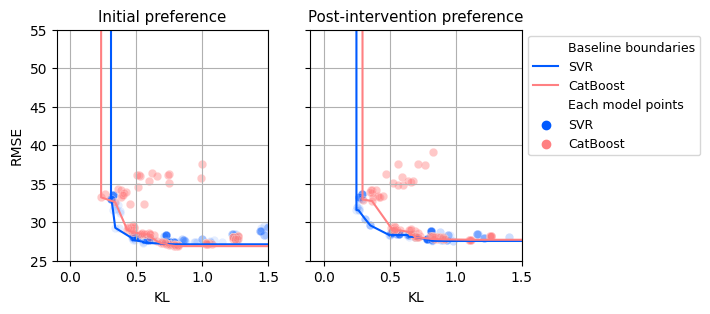
Appendix G Baselines
The text discusses the hyperparameter combinations utilized for the Support Vector Regression (SVR) and CatBoost models, presented in Table 10. Additionally, Figure 11 illustrates the KL-RMSE plots for each model. Despite the existence of numerous non-dominated models, the Pareto fronts for the two models exhibit general consistency. The provided information focuses on the hyperparameter settings and performance visualization through KL-RMSE plots, without delving into further details or analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Aligning language models with human preferences
Tomasz Korbak
0
0
Language models (LMs) trained on vast quantities of text data can acquire sophisticated skills such as generating summaries, answering questions or generating code. However, they also manifest behaviors that violate human preferences, e.g., they can generate offensive content, falsehoods or perpetuate social biases. In this thesis, I explore several approaches to aligning LMs with human preferences. First, I argue that aligning LMs can be seen as Bayesian inference: conditioning a prior (base, pretrained LM) on evidence about human preferences (Chapter 2). Conditioning on human preferences can be implemented in numerous ways. In Chapter 3, I investigate the relation between two approaches to finetuning pretrained LMs using feedback given by a scoring function: reinforcement learning from human feedback (RLHF) and distribution matching. I show that RLHF can be seen as a special case of distribution matching but distributional matching is strictly more general. In chapter 4, I show how to extend the distribution matching to conditional language models. Finally, in chapter 5 I explore a different root: conditioning an LM on human preferences already during pretraining. I show that involving human feedback from the very start tends to be more effective than using it only during supervised finetuning. Overall, these results highlight the room for alignment techniques different from and complementary to RLHF.
4/19/2024
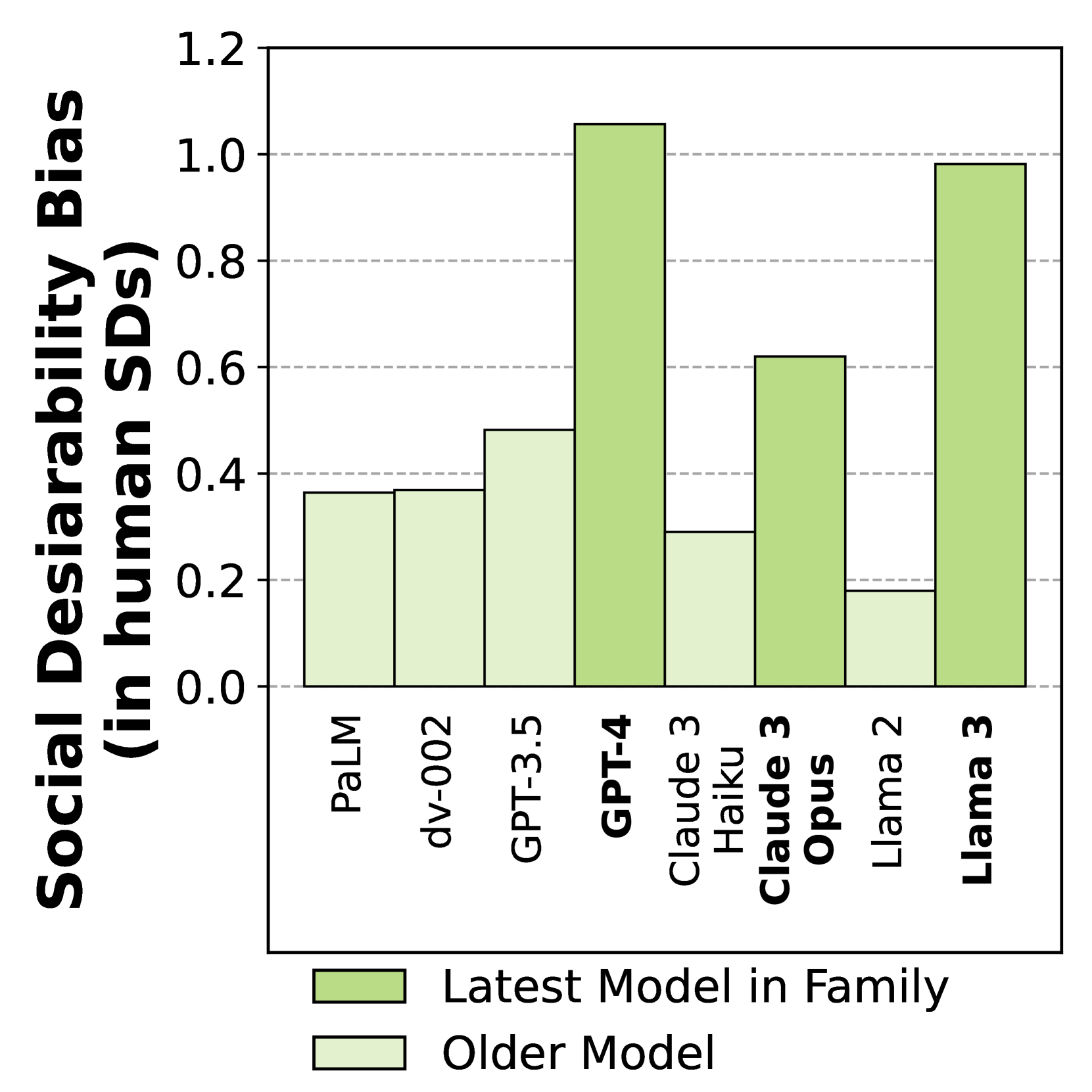
Large Language Models Show Human-like Social Desirability Biases in Survey Responses
Aadesh Salecha, Molly E. Ireland, Shashanka Subrahmanya, Jo~ao Sedoc, Lyle H. Ungar, Johannes C. Eichstaedt
0
0
As Large Language Models (LLMs) become widely used to model and simulate human behavior, understanding their biases becomes critical. We developed an experimental framework using Big Five personality surveys and uncovered a previously undetected social desirability bias in a wide range of LLMs. By systematically varying the number of questions LLMs were exposed to, we demonstrate their ability to infer when they are being evaluated. When personality evaluation is inferred, LLMs skew their scores towards the desirable ends of trait dimensions (i.e., increased extraversion, decreased neuroticism, etc). This bias exists in all tested models, including GPT-4/3.5, Claude 3, Llama 3, and PaLM-2. Bias levels appear to increase in more recent models, with GPT-4's survey responses changing by 1.20 (human) standard deviations and Llama 3's by 0.98 standard deviations-very large effects. This bias is robust to randomization of question order and paraphrasing. Reverse-coding all the questions decreases bias levels but does not eliminate them, suggesting that this effect cannot be attributed to acquiescence bias. Our findings reveal an emergent social desirability bias and suggest constraints on profiling LLMs with psychometric tests and on using LLMs as proxies for human participants.
5/13/2024
💬
Large Language Models (LLMs) as Agents for Augmented Democracy
Jairo Gudi~no-Rosero, Umberto Grandi, C'esar A. Hidalgo
0
0
We explore the capabilities of an augmented democracy system built on off-the-shelf LLMs fine-tuned on data summarizing individual preferences across 67 policy proposals collected during the 2022 Brazilian presidential elections. We use a train-test cross-validation setup to estimate the accuracy with which the LLMs predict both: a subject's individual political choices and the aggregate preferences of the full sample of participants. At the individual level, the accuracy of the out of sample predictions lie in the range 69%-76% and are significantly better at predicting the preferences of liberal and college educated participants. At the population level, we aggregate preferences using an adaptation of the Borda score and compare the ranking of policy proposals obtained from a probabilistic sample of participants and from data augmented using LLMs. We find that the augmented data predicts the preferences of the full population of participants better than probabilistic samples alone when these represent less than 30% to 40% of the total population. These results indicate that LLMs are potentially useful for the construction of systems of augmented democracy.
5/8/2024
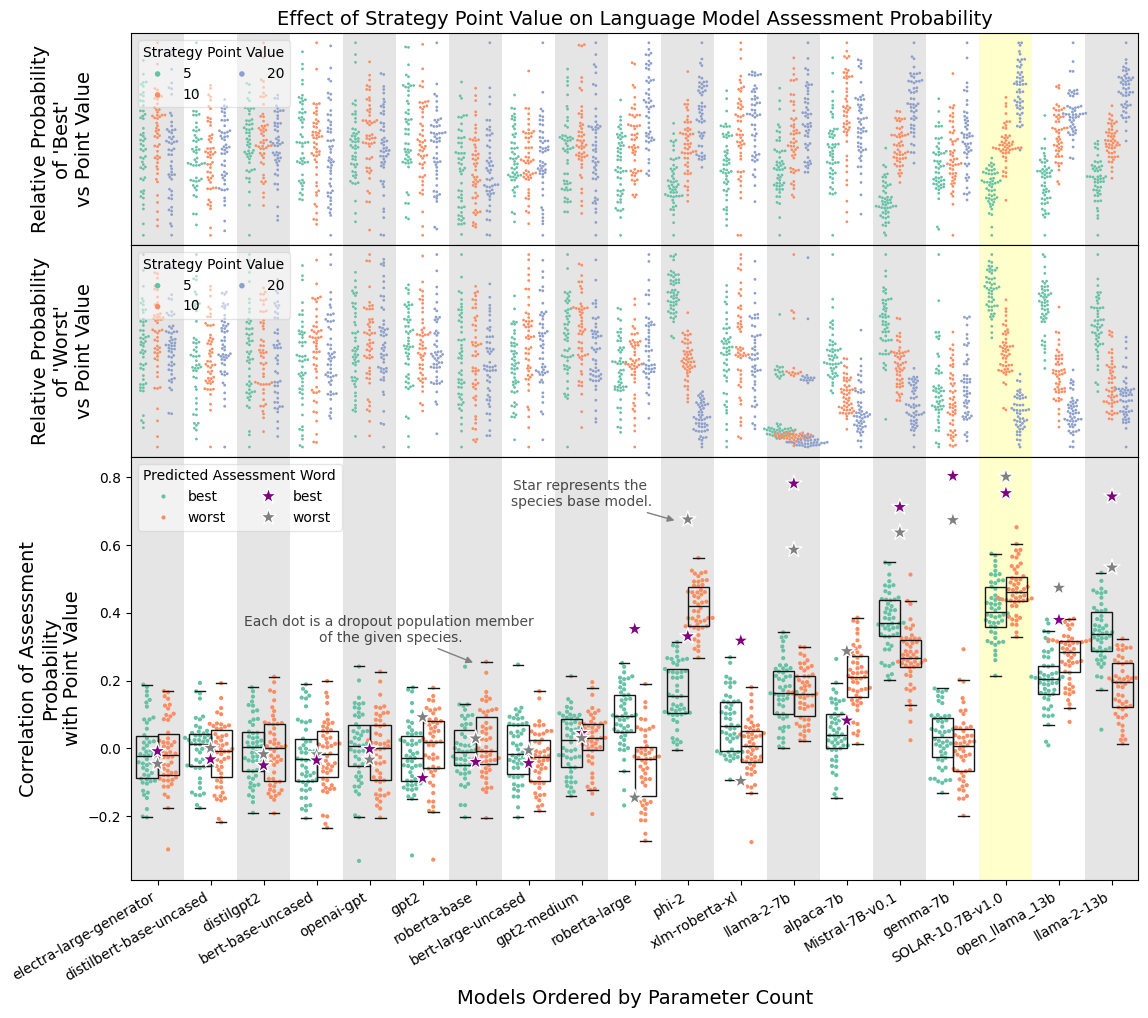
Do Large Language Models Learn Human-Like Strategic Preferences?
Jesse Roberts, Kyle Moore, Doug Fisher
0
0
We evaluate whether LLMs learn to make human-like preference judgements in strategic scenarios as compared with known empirical results. We show that Solar and Mistral exhibit stable value-based preference consistent with human in the prisoner's dilemma, including stake-size effect, and traveler's dilemma, including penalty-size effect. We establish a relationship between model size, value based preference, and superficiality. Finally, we find that models that tend to be less brittle were trained with sliding window attention. Additionally, we contribute a novel method for constructing preference relations from arbitrary LLMs and support for a hypothesis regarding human behavior in the traveler's dilemma.
4/16/2024