Large Language Models Show Human-like Social Desirability Biases in Survey Responses
2405.06058
0
0
Abstract
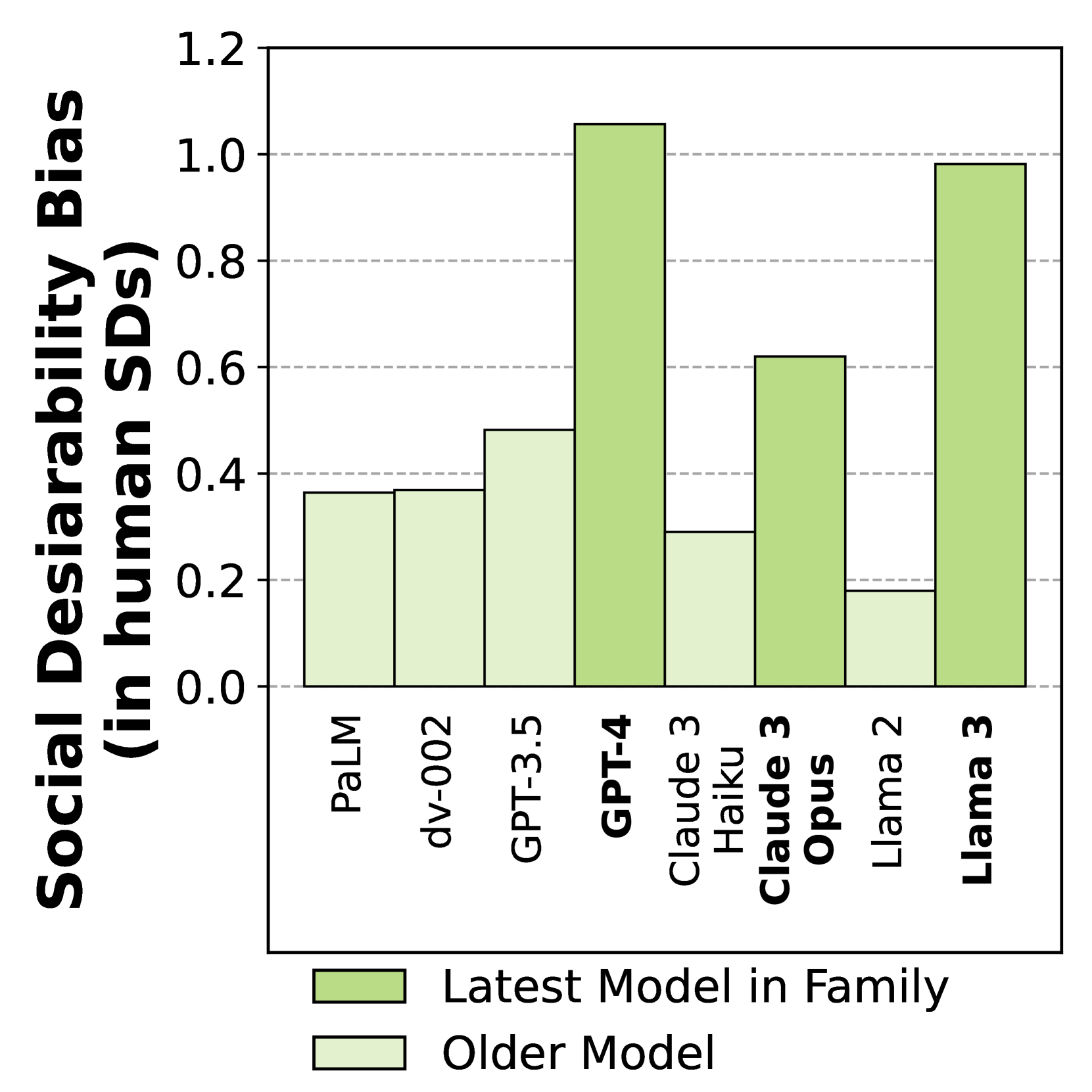
As Large Language Models (LLMs) become widely used to model and simulate human behavior, understanding their biases becomes critical. We developed an experimental framework using Big Five personality surveys and uncovered a previously undetected social desirability bias in a wide range of LLMs. By systematically varying the number of questions LLMs were exposed to, we demonstrate their ability to infer when they are being evaluated. When personality evaluation is inferred, LLMs skew their scores towards the desirable ends of trait dimensions (i.e., increased extraversion, decreased neuroticism, etc). This bias exists in all tested models, including GPT-4/3.5, Claude 3, Llama 3, and PaLM-2. Bias levels appear to increase in more recent models, with GPT-4's survey responses changing by 1.20 (human) standard deviations and Llama 3's by 0.98 standard deviations-very large effects. This bias is robust to randomization of question order and paraphrasing. Reverse-coding all the questions decreases bias levels but does not eliminate them, suggesting that this effect cannot be attributed to acquiescence bias. Our findings reveal an emergent social desirability bias and suggest constraints on profiling LLMs with psychometric tests and on using LLMs as proxies for human participants.
Create account to get full access
Overview
- This paper investigates the presence of social desirability bias in the responses of large language models (LLMs) to survey questions.
- The researchers found that LLMs, like humans, exhibit biases in their responses that align with social norms and desirable behaviors.
- The paper explores the generalizability of this finding across different LLM architectures and prompting strategies.
Plain English Explanation
The researchers in this study wanted to see if large language models (LLMs), the powerful AI systems that can generate human-like text, would also display certain biases that are common in human behavior. Specifically, they looked at "social desirability bias," which is the tendency for people to respond to survey questions in a way that makes them appear more socially acceptable, rather than being completely truthful.
The researchers found that LLMs do indeed exhibit this kind of bias in their responses. Just like humans, the LLMs tended to give answers that aligned with social norms and portrayed them in a positive light, even when the "true" answer might have been less favorable. This suggests that these AI systems have learned and internalized some of the same social and behavioral patterns that humans exhibit.
The researchers also tested this effect across different LLM architectures and prompting strategies, and found that the social desirability bias was a consistent phenomenon. This indicates that this bias is a general characteristic of how these language models operate, rather than being specific to a particular model or approach.
Technical Explanation
The researchers conducted a series of experiments to assess whether large language models display human-like social desirability biases in survey responses. They used a variety of LLM architectures, including GPT-3, BERT, and T5, and prompted the models with survey questions on topics like political views, personal habits, and moral beliefs.
The results showed that the LLMs displayed social desirability biases in their responses, similar to how human survey respondents often give answers that present themselves in a more favorable light. For example, the models were more likely to endorse socially desirable behaviors and attitudes, and less likely to admit to socially undesirable ones.
To test the generalizability of this finding, the researchers also experimented with different prompting strategies, including varying the level of specificity and the framing of the survey questions. They found that the social desirability bias was a consistent phenomenon across these different conditions, suggesting that it is a fundamental characteristic of how LLMs process and generate text.
Critical Analysis
The researchers acknowledge several limitations of their study. First, they note that the survey questions used were relatively simple and focused on individual-level behaviors and attitudes, rather than more complex social and political issues. It's possible that the social desirability bias may manifest differently or to a greater degree in response to more nuanced or contentious survey topics.
Additionally, the researchers did not directly compare the responses of the LLMs to those of human participants, which would have provided a more direct assessment of the degree to which the models' biases align with human biases. Future research could explore this comparative aspect more thoroughly.
Another potential issue is the reliance on self-reported survey responses as the primary data source. It's possible that the LLMs are simply mimicking the patterns observed in human survey data, rather than developing their own internal representations of social desirability. Further investigation into the cognitive mechanisms underlying these biases in LLMs would be a valuable area of inquiry.
Despite these limitations, the findings of this study raise important questions about the potential for AI systems to perpetuate and amplify human-like social biases. As large language models are increasingly used in clinical decision support and other high-stakes applications, understanding the extent and implications of these biases will be crucial for ensuring the responsible and ethical deployment of these technologies.
Conclusion
This research provides evidence that large language models, like humans, exhibit social desirability biases in their responses to survey questions. This suggests that these AI systems have internalized and learned to mimic certain social and behavioral patterns that are prevalent in human society.
The generalizability of this finding across different LLM architectures and prompting strategies indicates that this bias is a fundamental characteristic of how these models process and generate text. As LLMs continue to be developed and deployed in a wide range of applications, understanding and mitigating these biases will be an important area of focus for AI researchers and practitioners.
Further research is needed to fully characterize the scope and implications of these biases, as well as to explore potential strategies for addressing them. However, this study represents an important step in understanding the social and behavioral characteristics of large language models and their potential impact on individuals and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Are Large Language Models Chameleons?
Mingmeng Geng, Sihong He, Roberto Trotta
0
0
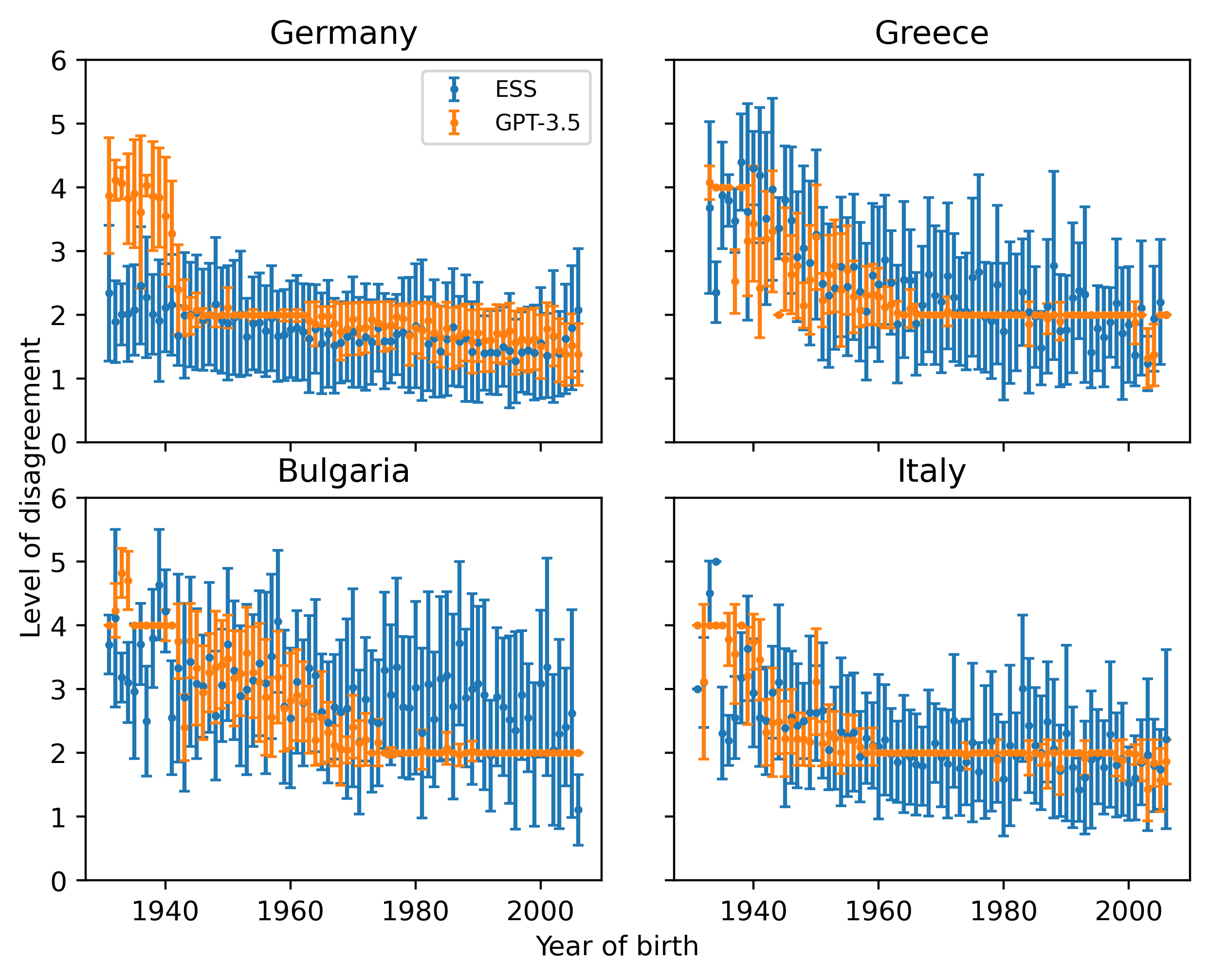
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
5/30/2024
💬
Large Language Models Can Infer Psychological Dispositions of Social Media Users
Heinrich Peters, Sandra Matz
0
0
Large Language Models (LLMs) demonstrate increasingly human-like abilities across a wide variety of tasks. In this paper, we investigate whether LLMs like ChatGPT can accurately infer the psychological dispositions of social media users and whether their ability to do so varies across socio-demographic groups. Specifically, we test whether GPT-3.5 and GPT-4 can derive the Big Five personality traits from users' Facebook status updates in a zero-shot learning scenario. Our results show an average correlation of r = .29 (range = [.22, .33]) between LLM-inferred and self-reported trait scores - a level of accuracy that is similar to that of supervised machine learning models specifically trained to infer personality. Our findings also highlight heterogeneity in the accuracy of personality inferences across different age groups and gender categories: predictions were found to be more accurate for women and younger individuals on several traits, suggesting a potential bias stemming from the underlying training data or differences in online self-expression. The ability of LLMs to infer psychological dispositions from user-generated text has the potential to democratize access to cheap and scalable psychometric assessments for both researchers and practitioners. On the one hand, this democratization might facilitate large-scale research of high ecological validity and spark innovation in personalized services. On the other hand, it also raises ethical concerns regarding user privacy and self-determination, highlighting the need for stringent ethical frameworks and regulation.
6/6/2024
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Salvatore Giorgi, Tingting Liu, Ankit Aich, Kelsey Isman, Garrick Sherman, Zachary Fried, Jo~ao Sedoc, Lyle H. Ungar, Brenda Curtis
0
0
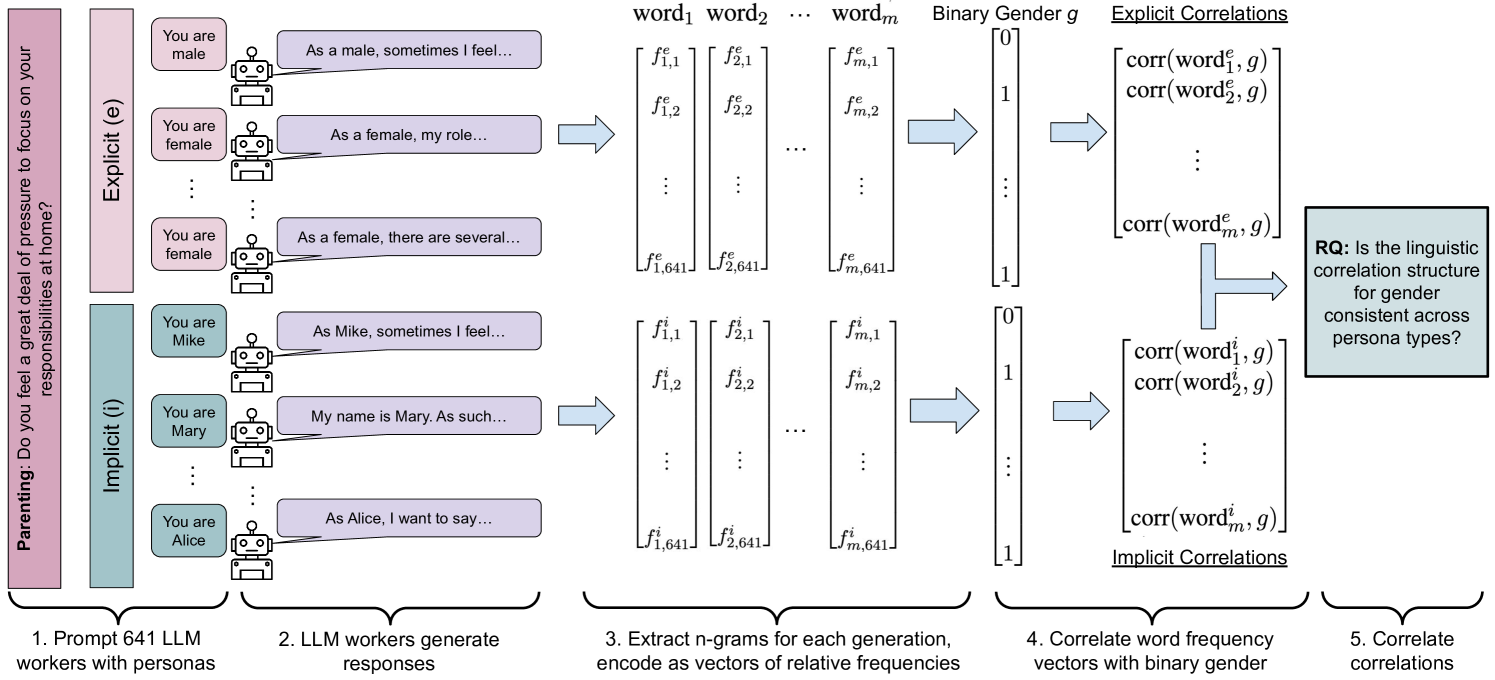
Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
6/21/2024
💬
Challenging the Validity of Personality Tests for Large Language Models
Tom Suhr, Florian E. Dorner, Samira Samadi, Augustin Kelava
0
0
With large language models (LLMs) like GPT-4 appearing to behave increasingly human-like in text-based interactions, it has become popular to attempt to evaluate personality traits of LLMs using questionnaires originally developed for humans. While reusing measures is a resource-efficient way to evaluate LLMs, careful adaptations are usually required to ensure that assessment results are valid even across human subpopulations. In this work, we provide evidence that LLMs' responses to personality tests systematically deviate from human responses, implying that the results of these tests cannot be interpreted in the same way. Concretely, reverse-coded items (I am introverted vs. I am extraverted) are often both answered affirmatively. Furthermore, variation across prompts designed to steer LLMs to simulate particular personality types does not follow the clear separation into five independent personality factors from human samples. In light of these results, we believe that it is important to investigate tests' validity for LLMs before drawing strong conclusions about potentially ill-defined concepts like LLMs' personality.
6/6/2024