AI data transparency: an exploration through the lens of AI incidents

0

Sign in to get full access
Overview
- This paper explores the concept of AI data transparency through the lens of AI incidents.
- It examines how data transparency can help understand and mitigate the risks associated with AI systems.
- The paper discusses the importance of data transparency in building trust and accountability in AI.
Plain English Explanation
The paper looks at the issue of transparency in the data used to train AI systems. It argues that being open about the data used to develop AI can help us better understand and address the problems that can arise when these systems are deployed.
Transparent AI data means being clear about where the information comes from, how it was collected, and what biases or limitations it may have. This transparency can build trust in AI systems and make it easier to hold developers accountable when things go wrong.
By examining real-world AI incidents, the paper shows how a lack of data transparency contributed to these problems. It suggests that being upfront about the data used to train AI could help identify and mitigate similar issues in the future.
Technical Explanation
The paper first provides background on the importance of data transparency in AI systems. It explains how transparency around the data sources, collection processes, and potential biases can improve accountability and build public trust.
The core of the paper involves analyzing several high-profile AI incidents, such as algorithmic bias in facial recognition and content moderation failures. The authors closely examine the role that opaque or incomplete data played in these failures. They find that a lack of transparency around the training data often masked important limitations or flaws that led to the problems.
Based on these case studies, the paper advocates for increased data transparency as a key part of responsible AI development. It proposes specific transparency measures, such as detailed data provenance documentation and independent data audits. The authors argue these steps can help identify and mitigate data-related risks before AI systems are deployed in the real world.
Critical Analysis
The paper makes a compelling case for the importance of data transparency in AI systems. The in-depth examination of real-world incidents illustrates how a lack of transparency can have serious consequences. The proposed transparency measures seem reasonable and pragmatic.
However, the paper does not deeply explore some of the practical challenges of implementing comprehensive data transparency. Issues around data privacy, commercial sensitivities, and the scalability of auditing large datasets are briefly mentioned but not fully addressed.
Additionally, the paper focuses primarily on the role of data, but AI systems also rely on the algorithms and models used to process that data. There may be a need for transparency around these technical components as well to fully understand and mitigate AI risks.
Overall, this paper provides a strong foundation for understanding the importance of data transparency in AI. Further research could explore the specific implementation details and tradeoffs involved in adopting these transparency practices at scale.
Conclusion
This paper makes a compelling argument that data transparency is crucial for building trust and accountability in AI systems. By examining real-world AI incidents, it demonstrates how a lack of transparency around training data can contribute to significant problems.
The authors propose specific transparency measures, such as detailed data provenance documentation and independent audits, as a way to identify and mitigate data-related risks before AI systems are deployed. While the paper does not fully explore the practical challenges of implementing these practices, it lays important groundwork for future research and policy discussions on responsible AI development.
Ultimately, this work highlights the need for AI developers, researchers, and policymakers to prioritize transparency as a key component of ethical and trustworthy AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AI data transparency: an exploration through the lens of AI incidents
Sophia Worth, Ben Snaith, Arunav Das, Gefion Thuermer, Elena Simperl
Knowing more about the data used to build AI systems is critical for allowing different stakeholders to play their part in ensuring responsible and appropriate deployment and use. Meanwhile, a 2023 report shows that data transparency lags significantly behind other areas of AI transparency in popular foundation models. In this research, we sought to build on these findings, exploring the status of public documentation about data practices within AI systems generating public concern. Our findings demonstrate that low data transparency persists across a wide range of systems, and further that issues of transparency and explainability at model- and system- level create barriers for investigating data transparency information to address public concerns about AI systems. We highlight a need to develop systematic ways of monitoring AI data transparency that account for the diversity of AI system types, and for such efforts to build on further understanding of the needs of those both supplying and using data transparency information.
Read more9/6/2024
🤖
0
AI Transparency in Academic Search Systems: An Initial Exploration
Yifan Liu, Peter Sullivan, Luanne Sinnamon
As AI-enhanced academic search systems become increasingly popular among researchers, investigating their AI transparency is crucial to ensure trust in the search outcomes, as well as the reliability and integrity of scholarly work. This study employs a qualitative content analysis approach to examine the websites of a sample of 10 AI-enhanced academic search systems identified through university library guides. The assessed level of transparency varies across these systems: five provide detailed information about their mechanisms, three offer partial information, and two provide little to no information. These findings indicate that the academic community is recommending and using tools with opaque functionalities, raising concerns about research integrity, including issues of reproducibility and researcher responsibility.
Read more8/21/2024
📊
0
Data Authenticity, Consent, & Provenance for AI are all broken: what will it take to fix them?
Shayne Longpre, Robert Mahari, Naana Obeng-Marnu, William Brannon, Tobin South, Katy Gero, Sandy Pentland, Jad Kabbara
New capabilities in foundation models are owed in large part to massive, widely-sourced, and under-documented training data collections. Existing practices in data collection have led to challenges in tracing authenticity, verifying consent, preserving privacy, addressing representation and bias, respecting copyright, and overall developing ethical and trustworthy foundation models. In response, regulation is emphasizing the need for training data transparency to understand foundation models' limitations. Based on a large-scale analysis of the foundation model training data landscape and existing solutions, we identify the missing infrastructure to facilitate responsible foundation model development practices. We examine the current shortcomings of common tools for tracing data authenticity, consent, and documentation, and outline how policymakers, developers, and data creators can facilitate responsible foundation model development by adopting universal data provenance standards.
Read more9/4/2024
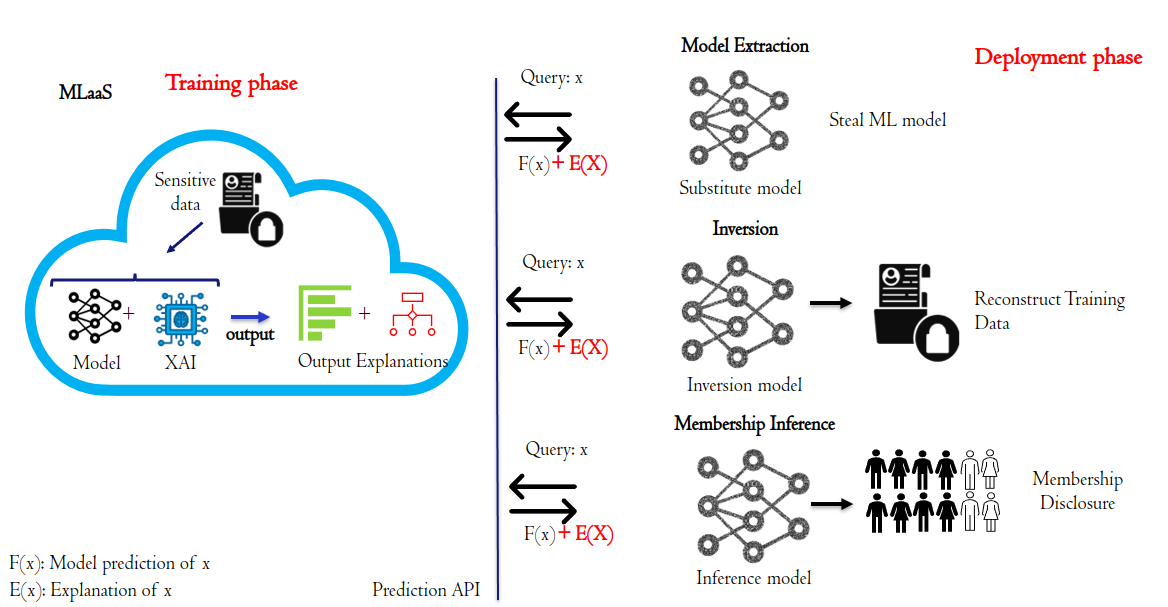
0
Privacy Implications of Explainable AI in Data-Driven Systems
Fatima Ezzeddine
Machine learning (ML) models, demonstrably powerful, suffer from a lack of interpretability. The absence of transparency, often referred to as the black box nature of ML models, undermines trust and urges the need for efforts to enhance their explainability. Explainable AI (XAI) techniques address this challenge by providing frameworks and methods to explain the internal decision-making processes of these complex models. Techniques like Counterfactual Explanations (CF) and Feature Importance play a crucial role in achieving this goal. Furthermore, high-quality and diverse data remains the foundational element for robust and trustworthy ML applications. In many applications, the data used to train ML and XAI explainers contain sensitive information. In this context, numerous privacy-preserving techniques can be employed to safeguard sensitive information in the data, such as differential privacy. Subsequently, a conflict between XAI and privacy solutions emerges due to their opposing goals. Since XAI techniques provide reasoning for the model behavior, they reveal information relative to ML models, such as their decision boundaries, the values of features, or the gradients of deep learning models when explanations are exposed to a third entity. Attackers can initiate privacy breaching attacks using these explanations, to perform model extraction, inference, and membership attacks. This dilemma underscores the challenge of finding the right equilibrium between understanding ML decision-making and safeguarding privacy.
Read more6/26/2024