AI-Generated Text Detection and Classification Based on BERT Deep Learning Algorithm
2405.16422
0
0
🔎
Abstract
AI-generated text detection plays an increasingly important role in various fields. In this study, we developed an efficient AI-generated text detection model based on the BERT algorithm, which provides new ideas and methods for solving related problems. In the data preprocessing stage, a series of steps were taken to process the text, including operations such as converting to lowercase, word splitting, removing stop words, stemming extraction, removing digits, and eliminating redundant spaces, to ensure data quality and accuracy. By dividing the dataset into a training set and a test set in the ratio of 60% and 40%, and observing the changes in the accuracy and loss values during the training process, we found that the model performed well during the training process. The accuracy increases steadily from the initial 94.78% to 99.72%, while the loss value decreases from 0.261 to 0.021 and converges gradually, which indicates that the BERT model is able to detect AI-generated text with high accuracy and the prediction results are gradually approaching the real classification results. Further analysis of the results of the training and test sets reveals that in terms of loss value, the average loss of the training set is 0.0565, while the average loss of the test set is 0.0917, showing a slightly higher loss value. As for the accuracy, the average accuracy of the training set reaches 98.1%, while the average accuracy of the test set is 97.71%, which is not much different from each other, indicating that the model has good generalisation ability. In conclusion, the AI-generated text detection model based on the BERT algorithm proposed in this study shows high accuracy and stability in experiments, providing an effective solution for related fields.
Create account to get full access
Overview
- This study developed an efficient AI-generated text detection model using the BERT algorithm.
- The model was trained and tested on a dataset, with the goal of accurately identifying text generated by AI systems.
- The paper outlines the data preprocessing steps, model training process, and analysis of the results.
Plain English Explanation
The study focused on creating a new way to detect text that has been generated by AI systems, rather than written by humans. This is an important task, as the use of AI text generation is becoming more widespread, and it's crucial to be able to identify when text is AI-generated rather than human-written.
The researchers used a popular AI model called BERT as the foundation for their detection system. They first preprocessed the text data, which involved steps like converting to lowercase, removing stop words, and stemming the words. This helps to clean up the data and prepare it for the machine learning model.
The researchers then split the dataset into a training set and a test set, with 60% of the data used for training and 40% for testing. By monitoring the model's performance during the training process, they found that the accuracy steadily increased from around 95% to almost 100%, while the loss value (a measure of how well the model is performing) decreased and converged.
When they analyzed the results in more detail, they found that the model performed slightly better on the training set than the test set, but the differences were not significant. This suggests that the model has good generalization ability and can perform well on new, unseen data.
Overall, the study demonstrates that the BERT-based AI-generated text detection model can be a highly effective solution for identifying AI-generated text in various applications.
Technical Explanation
The researchers used the BERT (Bidirectional Encoder Representations from Transformers) algorithm as the foundation for their AI-generated text detection model. BERT is a powerful natural language processing model that has been widely used in a variety of text-based tasks.
In the data preprocessing stage, the researchers took several steps to clean and prepare the text data for the machine learning model. This included converting the text to lowercase, splitting the text into individual words, removing stop words, performing stemming to extract the root forms of words, removing digits, and eliminating redundant spaces. These preprocessing steps help to ensure the quality and accuracy of the data used to train the model.
The dataset was then divided into a training set (60%) and a test set (40%). The researchers closely monitored the changes in the accuracy and loss values during the training process. They found that the model's accuracy steadily increased from an initial 94.78% to 99.72%, while the loss value decreased from 0.261 to 0.021 and gradually converged. This indicates that the BERT-based model was able to effectively detect AI-generated text with high accuracy, and the prediction results were closely aligning with the true classification.
Further analysis of the training and test set results revealed that the average loss value for the training set was 0.0565, while the average loss for the test set was slightly higher at 0.0917. In terms of accuracy, the average accuracy of the training set was 98.1%, and the average accuracy of the test set was 97.71%, which is not significantly different. These findings suggest that the model has good generalization ability and can perform well on new, unseen data.
Critical Analysis
The study provides a promising approach for detecting AI-generated text using the BERT algorithm. The high accuracy and stability of the model's performance, as demonstrated in the experiments, suggest that this method could be a valuable tool in various applications where the identification of AI-generated content is crucial.
However, the paper does not discuss any potential limitations or caveats of the research. For example, the dataset used for training and testing the model is not described in detail, and it's unclear how representative it is of the real-world scenarios where the detection model would be applied. Additionally, the paper does not mention any potential biases or edge cases that the model may struggle with, such as the detection of more sophisticated or context-specific AI-generated text.
Furthermore, the paper does not provide any information about the computational resources required to train and deploy the model, which could be an important consideration for practical applications. It also lacks a discussion of the potential ethical implications of such AI-generated text detection systems, such as privacy concerns or the potential for misuse.
Overall, while the study presents a promising approach, a more comprehensive analysis of the model's limitations, robustness, and practical considerations would be helpful to fully evaluate the significance and potential impact of this research.
Conclusion
This study developed an efficient AI-generated text detection model based on the BERT algorithm, which demonstrated high accuracy and stability in the experiments. The model was able to consistently identify AI-generated text with an accuracy of over 97% on both the training and test sets, indicating strong generalization ability.
The findings of this research provide a valuable contribution to the field of AI text generation detection, offering a practical solution for identifying AI-generated content in various applications. As the use of large language models for text generation continues to grow, the ability to reliably detect such AI-generated text will become increasingly important for maintaining the integrity of written communication and preventing the spread of misinformation.
While the study presents a promising approach, further research is needed to address the potential limitations and explore the broader implications of this technology. Ongoing efforts to develop more robust and versatile AI-generated text detection systems will be crucial in ensuring the responsible and ethical use of these powerful AI capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Detecting AI Generated Text Based on NLP and Machine Learning Approaches
Nuzhat Prova
0
0
Recent advances in natural language processing (NLP) may enable artificial intelligence (AI) models to generate writing that is identical to human written form in the future. This might have profound ethical, legal, and social repercussions. This study aims to address this problem by offering an accurate AI detector model that can differentiate between electronically produced text and human-written text. Our approach includes machine learning methods such as XGB Classifier, SVM, BERT architecture deep learning models. Furthermore, our results show that the BERT performs better than previous models in identifying information generated by AI from information provided by humans. Provide a comprehensive analysis of the current state of AI-generated text identification in our assessment of pertinent studies. Our testing yielded positive findings, showing that our strategy is successful, with the BERT emerging as the most probable answer. We analyze the research's societal implications, highlighting the possible advantages for various industries while addressing sustainability issues pertaining to morality and the environment. The XGB classifier and SVM give 0.84 and 0.81 accuracy in this article, respectively. The greatest accuracy in this research is provided by the BERT model, which provides 0.93% accuracy.
4/17/2024
💬
Large Language Model (LLM) AI text generation detection based on transformer deep learning algorithm
Yuhong Mo, Hao Qin, Yushan Dong, Ziyi Zhu, Zhenglin Li
0
0
In this paper, a tool for detecting LLM AI text generation is developed based on the Transformer model, aiming to improve the accuracy of AI text generation detection and provide reference for subsequent research. Firstly the text is Unicode normalised, converted to lowercase form, characters other than non-alphabetic characters and punctuation marks are removed by regular expressions, spaces are added around punctuation marks, first and last spaces are removed, consecutive ellipses are replaced with single spaces and the text is connected using the specified delimiter. Next remove non-alphabetic characters and extra whitespace characters, replace multiple consecutive whitespace characters with a single space and again convert to lowercase form. The deep learning model combines layers such as LSTM, Transformer and CNN for text classification or sequence labelling tasks. The training and validation sets show that the model loss decreases from 0.127 to 0.005 and accuracy increases from 94.96 to 99.8, indicating that the model has good detection and classification ability for AI generated text. The test set confusion matrix and accuracy show that the model has 99% prediction accuracy for AI-generated text, with a precision of 0.99, a recall of 1, and an f1 score of 0.99, achieving a very high classification accuracy. Looking forward, it has the prospect of wide application in the field of AI text detection.
5/14/2024
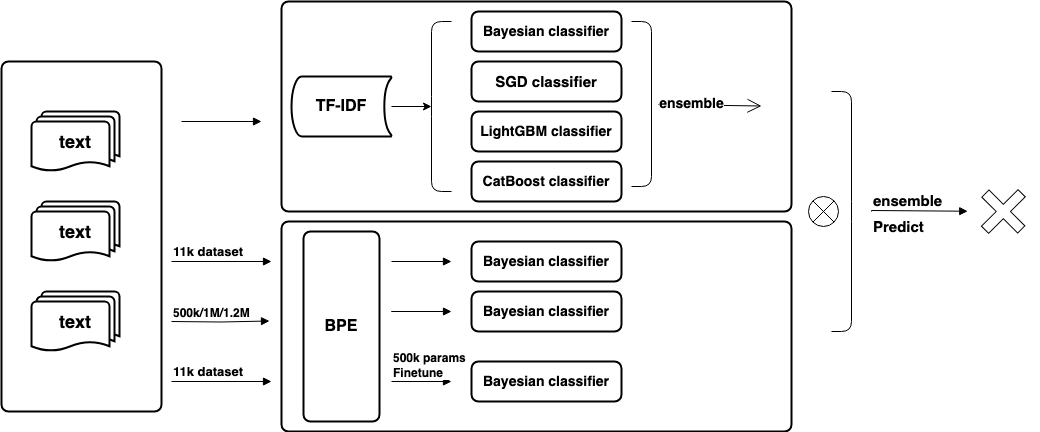
Enhancing Text Authenticity: A Novel Hybrid Approach for AI-Generated Text Detection
Ye Zhang, Qian Leng, Mengran Zhu, Rui Ding, Yue Wu, Jintong Song, Yulu Gong
0
0
The rapid advancement of Large Language Models (LLMs) has ushered in an era where AI-generated text is increasingly indistinguishable from human-generated content. Detecting AI-generated text has become imperative to combat misinformation, ensure content authenticity, and safeguard against malicious uses of AI. In this paper, we propose a novel hybrid approach that combines traditional TF-IDF techniques with advanced machine learning models, including Bayesian classifiers, Stochastic Gradient Descent (SGD), Categorical Gradient Boosting (CatBoost), and 12 instances of Deberta-v3-large models. Our approach aims to address the challenges associated with detecting AI-generated text by leveraging the strengths of both traditional feature extraction methods and state-of-the-art deep learning models. Through extensive experiments on a comprehensive dataset, we demonstrate the effectiveness of our proposed method in accurately distinguishing between human and AI-generated text. Our approach achieves superior performance compared to existing methods. This research contributes to the advancement of AI-generated text detection techniques and lays the foundation for developing robust solutions to mitigate the challenges posed by AI-generated content.
6/12/2024
🤖
Vietnamese AI Generated Text Detection
Quang-Dan Tran, Van-Quan Nguyen, Quang-Huy Pham, K. B. Thang Nguyen, Trong-Hop Do
0
0
In recent years, Large Language Models (LLMs) have become integrated into our daily lives, serving as invaluable assistants in completing tasks. Widely embraced by users, the abuse of LLMs is inevitable, particularly in using them to generate text content for various purposes, leading to difficulties in distinguishing between text generated by LLMs and that written by humans. In this study, we present a dataset named ViDetect, comprising 6.800 samples of Vietnamese essay, with 3.400 samples authored by humans and the remainder generated by LLMs, serving the purpose of detecting text generated by AI. We conducted evaluations using state-of-the-art methods, including ViT5, BartPho, PhoBERT, mDeberta V3, and mBERT. These results contribute not only to the growing body of research on detecting text generated by AI but also demonstrate the adaptability and effectiveness of different methods in the Vietnamese language context. This research lays the foundation for future advancements in AI-generated text detection and provides valuable insights for researchers in the field of natural language processing.
5/7/2024