Vietnamese AI Generated Text Detection
2405.03206
0
0
🤖
Abstract
In recent years, Large Language Models (LLMs) have become integrated into our daily lives, serving as invaluable assistants in completing tasks. Widely embraced by users, the abuse of LLMs is inevitable, particularly in using them to generate text content for various purposes, leading to difficulties in distinguishing between text generated by LLMs and that written by humans. In this study, we present a dataset named ViDetect, comprising 6.800 samples of Vietnamese essay, with 3.400 samples authored by humans and the remainder generated by LLMs, serving the purpose of detecting text generated by AI. We conducted evaluations using state-of-the-art methods, including ViT5, BartPho, PhoBERT, mDeberta V3, and mBERT. These results contribute not only to the growing body of research on detecting text generated by AI but also demonstrate the adaptability and effectiveness of different methods in the Vietnamese language context. This research lays the foundation for future advancements in AI-generated text detection and provides valuable insights for researchers in the field of natural language processing.
Create account to get full access
Overview
- This study presents a dataset called ViDetect, which contains over 6,800 samples of Vietnamese essays, with half written by humans and the other half generated by large language models (LLMs).
- The researchers evaluated several state-of-the-art methods, including ViT5, BartPho, PhoBERT, mDeberta V3, and mBERT, to detect text generated by AI in the Vietnamese language context.
- The study contributes to the growing body of research on detecting AI-generated text and provides valuable insights for researchers in the field of natural language processing.
Plain English Explanation
Large language models (LLMs) have become increasingly integrated into our daily lives, serving as helpful assistants in completing various tasks. However, the widespread use of LLMs has also led to concerns about their potential misuse, particularly in generating text content that could be difficult to distinguish from human-written text.
To address this issue, the researchers in this study created a dataset called ViDetect, which includes 6,800 samples of Vietnamese essays. Half of these samples were written by humans, and the other half were generated by LLMs. The researchers then evaluated several state-of-the-art methods, such as ViT5, BartPho, PhoBERT, mDeberta V3, and mBERT, to see how well they could detect the AI-generated text.
The results of this study contribute to the ongoing efforts to develop effective methods for detecting AI-generated text and provide valuable insights for researchers working in the field of natural language processing. By understanding the capabilities and limitations of different techniques, researchers can continue to improve our ability to distinguish human-written text from that generated by AI.
Technical Explanation
The researchers in this study created a dataset called ViDetect, which consists of 6,800 samples of Vietnamese essays. Half of these samples were written by humans, and the other half were generated by large language models (LLMs). The purpose of this dataset is to serve as a resource for detecting AI-generated text.
To evaluate the performance of various methods in detecting AI-generated text in the Vietnamese language context, the researchers tested several state-of-the-art approaches, including ViT5, BartPho, PhoBERT, mDeberta V3, and mBERT. These models are well-known for their success in natural language processing tasks and are now being explored for their ability to distinguish human-written text from that generated by LLMs.
The results of this study provide valuable insights into the adaptability and effectiveness of different methods in the Vietnamese language context, contributing to the growing body of research on detecting AI-generated text. This research lays the foundation for future advancements in this field and offers important lessons for researchers working on large language models and multimodal models.
Critical Analysis
The researchers in this study have taken an important step in addressing the challenge of detecting AI-generated text by creating a dataset and evaluating state-of-the-art methods in the context of the Vietnamese language. However, it's important to note that the dataset, while substantial, may not be fully representative of the diversity of AI-generated text that exists in the real world.
Additionally, the researchers acknowledge that their study focused on a limited set of methods, and there may be other approaches that could be more effective in detecting AI-generated text. Further research is needed to explore a wider range of techniques and to understand the limitations and potential biases of the current methods.
It would also be valuable for the researchers to investigate the factors that contribute to the success or failure of different detection methods, such as the complexity of the generated text, the writing style, and the specific features used by the AI models. This could help inform the development of more robust and adaptable detection algorithms.
Overall, this study represents an important contribution to the field of AI-generated text detection, and the researchers should be commended for their efforts. However, there is still much work to be done to fully address the challenges posed by the increasing prevalence of AI-generated content.
Conclusion
This study presents the ViDetect dataset, which contains over 6,800 samples of Vietnamese essays, half of which were written by humans and the other half generated by large language models (LLMs). The researchers evaluated several state-of-the-art methods, including ViT5, BartPho, PhoBERT, mDeberta V3, and mBERT, to detect AI-generated text in this context.
The results of this study contribute to the growing body of research on detecting AI-generated text and provide valuable insights for researchers working in the field of natural language processing. By understanding the capabilities and limitations of different detection methods, researchers can continue to improve our ability to distinguish human-written text from that generated by AI, which has important implications for the development of large language models and multimodal models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Deepfake Text Detection in the Wild
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Zhilin Wang, Longyue Wang, Linyi Yang, Shuming Shi, Yue Zhang
0
0
Large language models (LLMs) have achieved human-level text generation, emphasizing the need for effective AI-generated text detection to mitigate risks like the spread of fake news and plagiarism. Existing research has been constrained by evaluating detection methods on specific domains or particular language models. In practical scenarios, however, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a comprehensive testbed by gathering texts from diverse human writings and texts generated by different LLMs. Empirical results show challenges in distinguishing machine-generated texts from human-authored ones across various scenarios, especially out-of-distribution. These challenges are due to the decreasing linguistic distinctions between the two sources. Despite challenges, the top-performing detector can identify 86.54% out-of-domain texts generated by a new LLM, indicating the feasibility for application scenarios. We release our resources at https://github.com/yafuly/MAGE.
5/22/2024
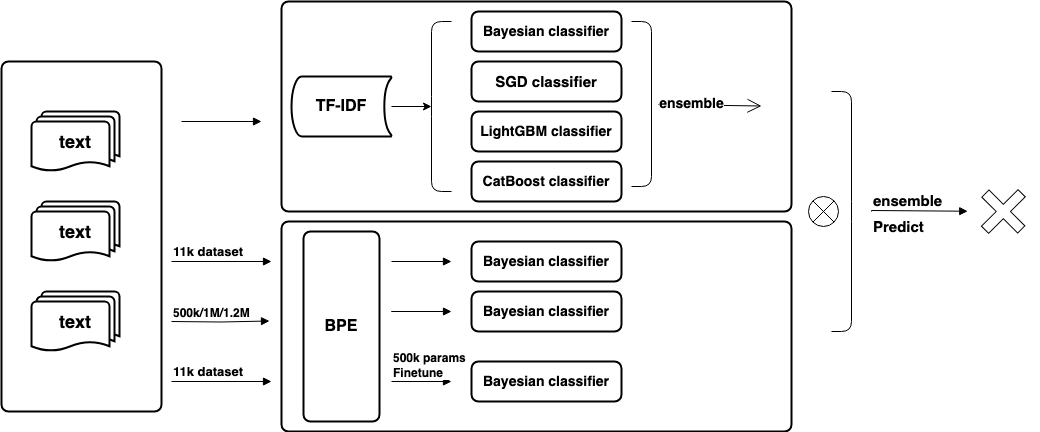
Enhancing Text Authenticity: A Novel Hybrid Approach for AI-Generated Text Detection
Ye Zhang, Qian Leng, Mengran Zhu, Rui Ding, Yue Wu, Jintong Song, Yulu Gong
0
0
The rapid advancement of Large Language Models (LLMs) has ushered in an era where AI-generated text is increasingly indistinguishable from human-generated content. Detecting AI-generated text has become imperative to combat misinformation, ensure content authenticity, and safeguard against malicious uses of AI. In this paper, we propose a novel hybrid approach that combines traditional TF-IDF techniques with advanced machine learning models, including Bayesian classifiers, Stochastic Gradient Descent (SGD), Categorical Gradient Boosting (CatBoost), and 12 instances of Deberta-v3-large models. Our approach aims to address the challenges associated with detecting AI-generated text by leveraging the strengths of both traditional feature extraction methods and state-of-the-art deep learning models. Through extensive experiments on a comprehensive dataset, we demonstrate the effectiveness of our proposed method in accurately distinguishing between human and AI-generated text. Our approach achieves superior performance compared to existing methods. This research contributes to the advancement of AI-generated text detection techniques and lays the foundation for developing robust solutions to mitigate the challenges posed by AI-generated content.
6/12/2024

CUDRT: Benchmarking the Detection of Human vs. Large Language Models Generated Texts
Zhen Tao, Zhiyu Li, Dinghao Xi, Wei Xu
0
0
The proliferation of large language models (LLMs) has significantly enhanced text generation capabilities across various industries. However, these models' ability to generate human-like text poses substantial challenges in discerning between human and AI authorship. Despite the effectiveness of existing AI-generated text detectors, their development is hindered by the lack of comprehensive, publicly available benchmarks. Current benchmarks are limited to specific scenarios, such as question answering and text polishing, and predominantly focus on English texts, failing to capture the diverse applications and linguistic nuances of LLMs. To address these limitations, this paper constructs a comprehensive bilingual benchmark in both Chinese and English to evaluate mainstream AI-generated text detectors. We categorize LLM text generation into five distinct operations: Create, Update, Delete, Rewrite, and Translate (CUDRT), encompassing all current LLMs activities. We also establish a robust benchmark evaluation framework to support scalable and reproducible experiments. For each CUDRT category, we have developed extensive datasets to thoroughly assess detector performance. By employing the latest mainstream LLMs specific to each language, our datasets provide a thorough evaluation environment. Extensive experimental results offer critical insights for optimizing AI-generated text detectors and suggest future research directions to improve detection accuracy and generalizability across various scenarios.
6/14/2024
💬
Crossing Linguistic Horizons: Finetuning and Comprehensive Evaluation of Vietnamese Large Language Models
Sang T. Truong, Duc Q. Nguyen, Toan Nguyen, Dong D. Le, Nhi N. Truong, Tho Quan, Sanmi Koyejo
0
0
Recent advancements in large language models (LLMs) have underscored their importance in the evolution of artificial intelligence. However, despite extensive pretraining on multilingual datasets, available open-sourced LLMs exhibit limited effectiveness in processing Vietnamese. The challenge is exacerbated by the absence of systematic benchmark datasets and metrics tailored for Vietnamese LLM evaluation. To mitigate these issues, we have finetuned LLMs specifically for Vietnamese and developed a comprehensive evaluation framework encompassing 10 common tasks and 31 metrics. Our evaluation results reveal that the fine-tuned LLMs exhibit enhanced comprehension and generative capabilities in Vietnamese. Moreover, our analysis indicates that models with more parameters can introduce more biases and uncalibrated outputs and the key factor influencing LLM performance is the quality of the training or fine-tuning datasets. These insights underscore the significance of meticulous fine-tuning with high-quality datasets in enhancing LLM performance.
5/28/2024