Large Language Model (LLM) AI text generation detection based on transformer deep learning algorithm
2405.06652
0
0
💬
Abstract
In this paper, a tool for detecting LLM AI text generation is developed based on the Transformer model, aiming to improve the accuracy of AI text generation detection and provide reference for subsequent research. Firstly the text is Unicode normalised, converted to lowercase form, characters other than non-alphabetic characters and punctuation marks are removed by regular expressions, spaces are added around punctuation marks, first and last spaces are removed, consecutive ellipses are replaced with single spaces and the text is connected using the specified delimiter. Next remove non-alphabetic characters and extra whitespace characters, replace multiple consecutive whitespace characters with a single space and again convert to lowercase form. The deep learning model combines layers such as LSTM, Transformer and CNN for text classification or sequence labelling tasks. The training and validation sets show that the model loss decreases from 0.127 to 0.005 and accuracy increases from 94.96 to 99.8, indicating that the model has good detection and classification ability for AI generated text. The test set confusion matrix and accuracy show that the model has 99% prediction accuracy for AI-generated text, with a precision of 0.99, a recall of 1, and an f1 score of 0.99, achieving a very high classification accuracy. Looking forward, it has the prospect of wide application in the field of AI text detection.
Create account to get full access
Overview
- This paper presents a tool for detecting AI-generated text using a deep learning model based on the Transformer architecture.
- The goal is to improve the accuracy of AI text generation detection and provide a reference for future research in this area.
- The paper outlines the data preprocessing steps and the model architecture, and reports the performance of the model on training, validation, and test datasets.
Plain English Explanation
The researchers have developed a new tool to help identify text that was generated by an AI model, like a large language model. This is important because as AI-generated text becomes more common, it can be challenging to distinguish it from text written by humans.
The tool uses a deep learning model based on the Transformer architecture, which is a type of neural network that has been very successful in various natural language processing tasks. The model is trained to analyze the text and determine whether it was generated by an AI or written by a human.
The researchers first prepare the text data by performing a series of preprocessing steps, such as converting the text to lowercase, removing non-alphabetic characters, and replacing certain punctuation. This helps the model focus on the relevant features of the text.
The researchers then train and validate the model, and report that it achieves very high accuracy in detecting AI-generated text. The model's performance on the test dataset is particularly impressive, with a 99% accuracy rate, high precision and recall, and an F1 score of 0.99.
Overall, this tool has great potential to be widely used in detecting AI-generated text, which could be useful in a variety of applications, such as content moderation, academic integrity, and fact-checking.
Technical Explanation
The researchers first preprocess the text data by performing several steps:
- Unicode normalization
- Conversion to lowercase
- Removal of non-alphabetic characters and punctuation marks, except for those that are kept
- Addition of spaces around punctuation marks
- Removal of leading and trailing spaces
- Replacement of consecutive ellipses with single spaces
- Concatenation of the text using a specified delimiter
Next, the researchers remove any remaining non-alphabetic characters and extra whitespace, and replace multiple consecutive whitespace characters with a single space, before converting the text to lowercase again.
The deep learning model used in this study combines several layers, including LSTM, Transformer, and CNN, to perform text classification or sequence labeling tasks. The researchers train and validate the model, reporting that the loss decreases from 0.127 to 0.005 and the accuracy increases from 94.96% to 99.8%, indicating the model's strong detection and classification abilities.
The researchers also evaluate the model's performance on a test dataset, providing a confusion matrix and reporting a 99% prediction accuracy for AI-generated text, with a precision of 0.99, a recall of 1, and an F1 score of 0.99. These results demonstrate the model's exceptional classification accuracy.
Critical Analysis
The researchers have provided a thorough explanation of their approach and have demonstrated the effectiveness of their model in detecting AI-generated text. However, some areas for further consideration or research are:
- The paper does not discuss the diversity of the training data, such as the types of AI-generated text included or the sources of the human-written text. Ensuring a representative and balanced dataset is crucial for the model's generalization.
- The researchers have not explored the model's performance on more challenging or adversarial examples, where the AI-generated text may be designed to mimic human writing more closely.
- It would be interesting to see how this model compares to other approaches, such as linguistic analysis or multimodal detection, in terms of accuracy, robustness, and computational efficiency.
- The paper does not discuss potential limitations or ethical considerations, such as the implications of widespread use of this technology for content moderation or academic integrity.
Overall, this research represents a valuable contribution to the field of AI-generated text detection, but further investigation and discussion of the broader implications would be beneficial.
Conclusion
This paper presents a highly accurate deep learning model for detecting AI-generated text, which could have significant applications in content moderation, academic integrity, and other areas where distinguishing human-written and AI-generated text is crucial. The researchers have demonstrated the model's strong performance on training, validation, and test datasets, and have provided a detailed technical explanation of their approach.
While the results are promising, the researchers should continue to explore the model's limitations, robustness, and potential ethical considerations. As AI-generated text becomes more prevalent, tools like this will be increasingly important for maintaining trust and integrity in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Deepfake Text Detection in the Wild
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Zhilin Wang, Longyue Wang, Linyi Yang, Shuming Shi, Yue Zhang
0
0
Large language models (LLMs) have achieved human-level text generation, emphasizing the need for effective AI-generated text detection to mitigate risks like the spread of fake news and plagiarism. Existing research has been constrained by evaluating detection methods on specific domains or particular language models. In practical scenarios, however, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a comprehensive testbed by gathering texts from diverse human writings and texts generated by different LLMs. Empirical results show challenges in distinguishing machine-generated texts from human-authored ones across various scenarios, especially out-of-distribution. These challenges are due to the decreasing linguistic distinctions between the two sources. Despite challenges, the top-performing detector can identify 86.54% out-of-domain texts generated by a new LLM, indicating the feasibility for application scenarios. We release our resources at https://github.com/yafuly/MAGE.
5/22/2024
Large Language Models for Mathematicians
Simon Frieder, Julius Berner, Philipp Petersen, Thomas Lukasiewicz
0
0
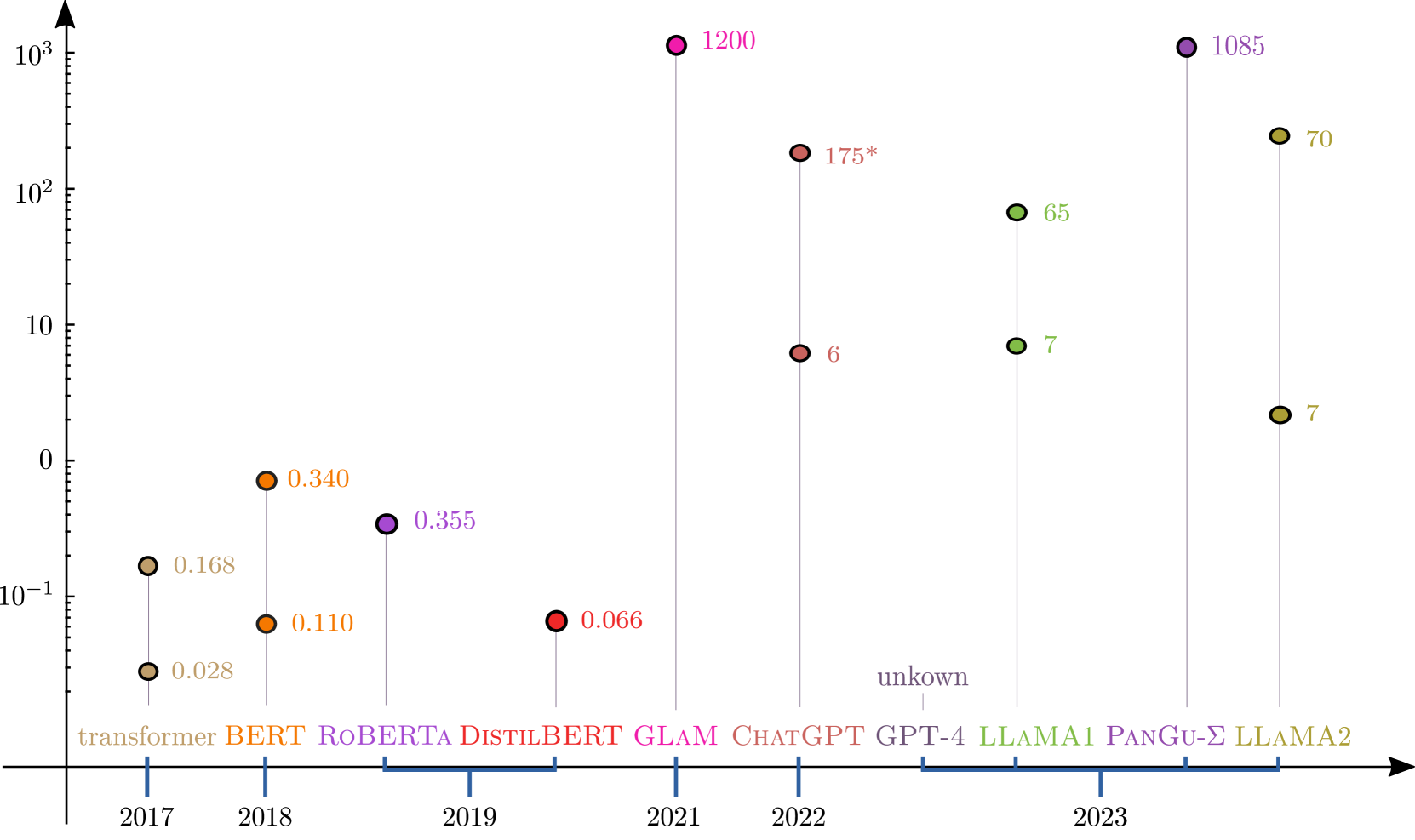
Large language models (LLMs) such as ChatGPT have received immense interest for their general-purpose language understanding and, in particular, their ability to generate high-quality text or computer code. For many professions, LLMs represent an invaluable tool that can speed up and improve the quality of work. In this note, we discuss to what extent they can aid professional mathematicians. We first provide a mathematical description of the transformer model used in all modern language models. Based on recent studies, we then outline best practices and potential issues and report on the mathematical abilities of language models. Finally, we shed light on the potential of LLMs to change how mathematicians work.
4/3/2024
A Survey on Large Language Models from Concept to Implementation
Chen Wang, Jin Zhao, Jiaqi Gong
0
0
Recent advancements in Large Language Models (LLMs), particularly those built on Transformer architectures, have significantly broadened the scope of natural language processing (NLP) applications, transcending their initial use in chatbot technology. This paper investigates the multifaceted applications of these models, with an emphasis on the GPT series. This exploration focuses on the transformative impact of artificial intelligence (AI) driven tools in revolutionizing traditional tasks like coding and problem-solving, while also paving new paths in research and development across diverse industries. From code interpretation and image captioning to facilitating the construction of interactive systems and advancing computational domains, Transformer models exemplify a synergy of deep learning, data analysis, and neural network design. This survey provides an in-depth look at the latest research in Transformer models, highlighting their versatility and the potential they hold for transforming diverse application sectors, thereby offering readers a comprehensive understanding of the current and future landscape of Transformer-based LLMs in practical applications.
5/29/2024
A review on the use of large language models as virtual tutors
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Mar'ia del Carmen Somoza-L'opez
0
0
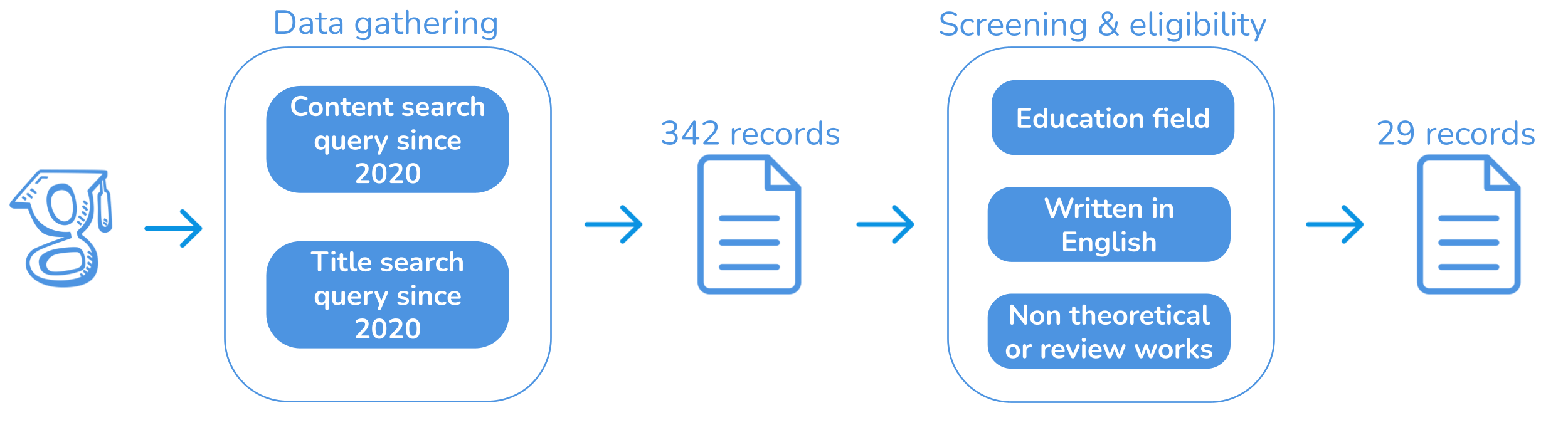
Transformer architectures contribute to managing long-term dependencies for Natural Language Processing, representing one of the most recent changes in the field. These architectures are the basis of the innovative, cutting-edge Large Language Models (LLMs) that have produced a huge buzz in several fields and industrial sectors, among the ones education stands out. Accordingly, these generative Artificial Intelligence-based solutions have directed the change in techniques and the evolution in educational methods and contents, along with network infrastructure, towards high-quality learning. Given the popularity of LLMs, this review seeks to provide a comprehensive overview of those solutions designed specifically to generate and evaluate educational materials and which involve students and teachers in their design or experimental plan. To the best of our knowledge, this is the first review of educational applications (e.g., student assessment) of LLMs. As expected, the most common role of these systems is as virtual tutors for automatic question generation. Moreover, the most popular models are GTP-3 and BERT. However, due to the continuous launch of new generative models, new works are expected to be published shortly.
5/21/2024