AIC MLLM: Autonomous Interactive Correction MLLM for Robust Robotic Manipulation

0
Sign in to get full access
Overview
- This paper presents a new approach called Autonomous Interactive Correction (AIC) that uses a Multi-modal Large Language Model (MLLM) to enable robust robotic manipulation.
- The AIC system allows robots to autonomously correct their actions based on real-time feedback, improving their performance and robustness.
- The research explores techniques like self-corrected multimodal large language models, prompting multi-modal tokens, and hierarchical closed-loop control to enable this interactive correction capability.
Plain English Explanation
The paper describes a new way for robots to learn and improve their physical manipulation skills through real-time feedback and self-correction. Traditionally, robots are programmed with specific instructions on how to perform tasks, and they simply follow those instructions without much flexibility or adaptation.
The AIC system uses a powerful AI model called a Multi-modal Large Language Model (MLLM) that can understand and integrate information from different sensor inputs, like cameras and touch sensors. This allows the robot to perceive its environment and actions more holistically. The MLLM can then use this understanding to autonomously adjust and correct its movements during a task, rather than just blindly following pre-programmed instructions.
For example, if a robot is trying to grasp an object but is not quite getting the right grip, the AIC system can detect this mismatch between the intended action and the observed result, and then make small corrections to the robot's movements to improve the grasp. This interactive feedback loop enables the robot to become more skilled and robust at manipulation tasks over time, adapting to different situations and objects.
The researchers explore ways to make this self-correction process more effective, such as prompting the MLLM with multi-modal tokens to enhance its understanding, and using hierarchical control strategies to break down complex tasks into more manageable steps.
Technical Explanation
The key innovation of this paper is the Autonomous Interactive Correction (AIC) system, which uses a Multi-modal Large Language Model (MLLM) to enable robots to autonomously correct their actions based on real-time feedback.
The MLLM is trained on a large and diverse dataset that includes not only text, but also visual, tactile, and other sensor data. This allows the model to develop a rich, multimodal understanding of the world, which is crucial for robust physical manipulation.
During task execution, the robot continuously observes its environment and actions using various sensors. The MLLM takes in this multimodal input and generates a refined action plan that corrects any deviations from the desired outcome. This closed-loop feedback and correction process happens autonomously, without the need for human intervention.
The researchers explored techniques like self-corrected multimodal large language models and prompting with multi-modal tokens to enhance the MLLM's ability to understand and reason about the robot's physical interactions. They also incorporated hierarchical control strategies to break down complex manipulation tasks into more manageable subtasks, further improving the system's robustness and performance.
The results demonstrate that the AIC system significantly outperforms traditional robotic control approaches in terms of task success rate, precision, and adaptability to novel situations.
Critical Analysis
The paper presents a novel and promising approach to enabling more robust and adaptive robotic manipulation. The use of a powerful MLLM to integrate multimodal feedback and autonomously correct actions is a significant advance in the field of robotics.
However, the paper does not fully address the computational and energy requirements of running a large-scale MLLM on-board a robot. This could be a practical limitation, especially for mobile or resource-constrained platforms. The researchers may need to explore more efficient model architectures or edge-computing strategies to make the AIC system more viable for real-world deployment.
Additionally, the paper does not discuss the potential safety and ethical implications of having robots make autonomous decisions and corrections during physical interactions. As these systems become more capable, it will be crucial to ensure they operate within safe and responsible boundaries, especially when interacting with humans.
Further research could also explore the theoretical understanding of self-correction through context alignment and how it can be applied to enhance the AIC system's robustness and generalization capabilities.
Conclusion
This paper presents a novel Autonomous Interactive Correction (AIC) system that uses a Multi-modal Large Language Model (MLLM) to enable robust and adaptive robotic manipulation. By continuously observing the environment and actions, the MLLM can autonomously generate corrected plans to improve task performance and adaptability.
The research explores techniques like self-corrected multimodal language models, multi-modal prompting, and hierarchical control to make the AIC system more effective. The results demonstrate significant improvements over traditional robotic control approaches.
While the paper presents a promising step forward, there are still practical and ethical considerations that need to be addressed, such as the computational requirements and the safe operation of autonomous robots. Nonetheless, the AIC system represents an important advancement in the field of robotic manipulation and could have far-reaching implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AIC MLLM: Autonomous Interactive Correction MLLM for Robust Robotic Manipulation
Chuyan Xiong, Chengyu Shen, Xiaoqi Li, Kaichen Zhou, Jiaming Liu, Ruiping Wang, Hao Dong
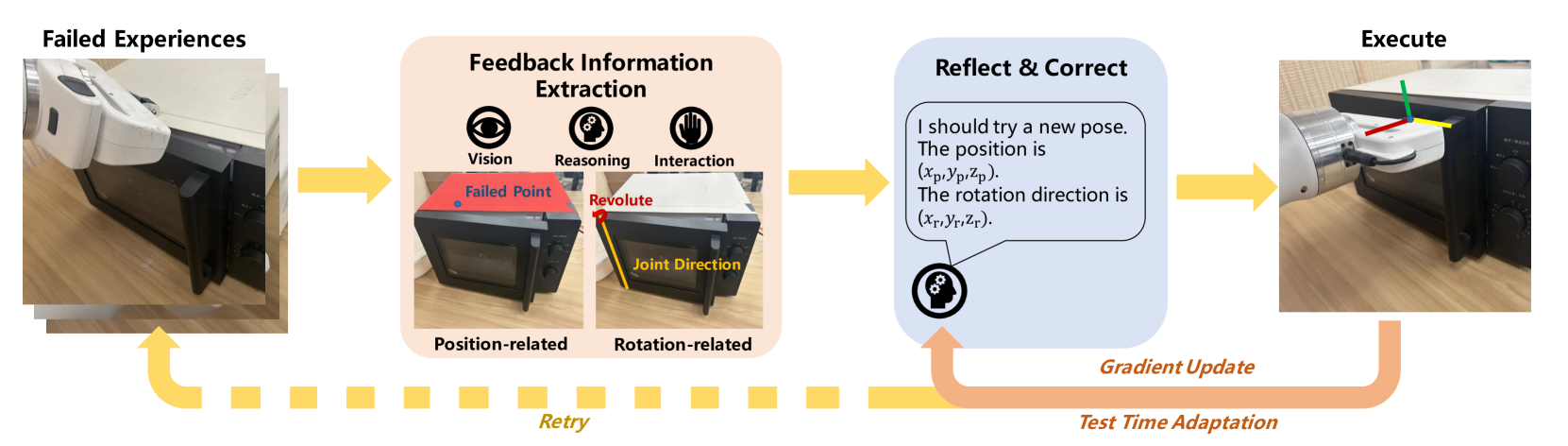
The ability to reflect on and correct failures is crucial for robotic systems to interact stably with real-life objects.Observing the generalization and reasoning capabilities of Multimodal Large Language Models (MLLMs), previous approaches have aimed to utilize these models to enhance robotic systems accordingly.However, these methods typically focus on high-level planning corrections using an additional MLLM, with limited utilization of failed samples to correct low-level contact poses. To address this gap, we propose an Autonomous Interactive Correction (AIC) MLLM, which makes use of previous low-level interaction experiences to correct SE(3) pose predictions. Specifically, AIC MLLM is initially fine-tuned to acquire both pose prediction and feedback prompt comprehension abilities.We carefully design two types of prompt instructions through interactions with objects: 1) visual masks to highlight unmovable parts for position correction, and 2)textual descriptions to indicate potential directions for rotation correction.During inference, a Feedback Information Extraction module is introduced to recognize the failure cause, allowing AIC MLLM to adaptively correct the pose prediction using the corresponding prompts. To further enhance manipulation stability, we devise a Test Time Adaptation strategy that enables AIC MLLM to better adapt to the current scene configuration.Finally, extensive experiments are conducted in both simulated and real-world environments to evaluate the proposed method. The results demonstrate that our AIC MLLM can efficiently correct failure samples by leveraging interaction experience prompts.Real-world demonstration can be found at https://sites.google.com/view/aic-mllm
Read more9/14/2024

0
Self-Corrected Multimodal Large Language Model for End-to-End Robot Manipulation
Jiaming Liu, Chenxuan Li, Guanqun Wang, Lily Lee, Kaichen Zhou, Sixiang Chen, Chuyan Xiong, Jiaxin Ge, Renrui Zhang, Shanghang Zhang
Robot manipulation policies have shown unsatisfactory action performance when confronted with novel task or object instances. Hence, the capability to automatically detect and self-correct failure action is essential for a practical robotic system. Recently, Multimodal Large Language Models (MLLMs) have shown promise in visual instruction following and demonstrated strong reasoning abilities in various tasks. To unleash general MLLMs as an end-to-end robotic agent, we introduce a Self-Corrected (SC)-MLLM, equipping our model not only to predict end-effector poses but also to autonomously recognize and correct failure actions. Specifically, we first conduct parameter-efficient fine-tuning to empower MLLM with pose prediction ability, which is reframed as a language modeling problem. When facing execution failures, our model learns to identify low-level action error causes (i.e., position and rotation errors) and adaptively seeks prompt feedback from experts. Based on the feedback, SC-MLLM rethinks the current failure scene and generates the corrected actions. Furthermore, we design a continuous policy learning method for successfully corrected samples, enhancing the model's adaptability to the current scene configuration and reducing the frequency of expert intervention. To evaluate our SC-MLLM, we conduct extensive experiments in both simulation and real-world settings. SC-MLLM agent significantly improve manipulation accuracy compared to previous state-of-the-art robotic MLLM (ManipLLM), increasing from 57% to 79% on seen object categories and from 47% to 69% on unseen novel categories.
Read more5/28/2024
📈
0
Enhancing the LLM-Based Robot Manipulation Through Human-Robot Collaboration
Haokun Liu, Yaonan Zhu, Kenji Kato, Atsushi Tsukahara, Izumi Kondo, Tadayoshi Aoyama, Yasuhisa Hasegawa
Large Language Models (LLMs) are gaining popularity in the field of robotics. However, LLM-based robots are limited to simple, repetitive motions due to the poor integration between language models, robots, and the environment. This paper proposes a novel approach to enhance the performance of LLM-based autonomous manipulation through Human-Robot Collaboration (HRC). The approach involves using a prompted GPT-4 language model to decompose high-level language commands into sequences of motions that can be executed by the robot. The system also employs a YOLO-based perception algorithm, providing visual cues to the LLM, which aids in planning feasible motions within the specific environment. Additionally, an HRC method is proposed by combining teleoperation and Dynamic Movement Primitives (DMP), allowing the LLM-based robot to learn from human guidance. Real-world experiments have been conducted using the Toyota Human Support Robot for manipulation tasks. The outcomes indicate that tasks requiring complex trajectory planning and reasoning over environments can be efficiently accomplished through the incorporation of human demonstrations.
Read more7/2/2024
0
Prompting Multi-Modal Tokens to Enhance End-to-End Autonomous Driving Imitation Learning with LLMs
Yiqun Duan, Qiang Zhang, Renjing Xu
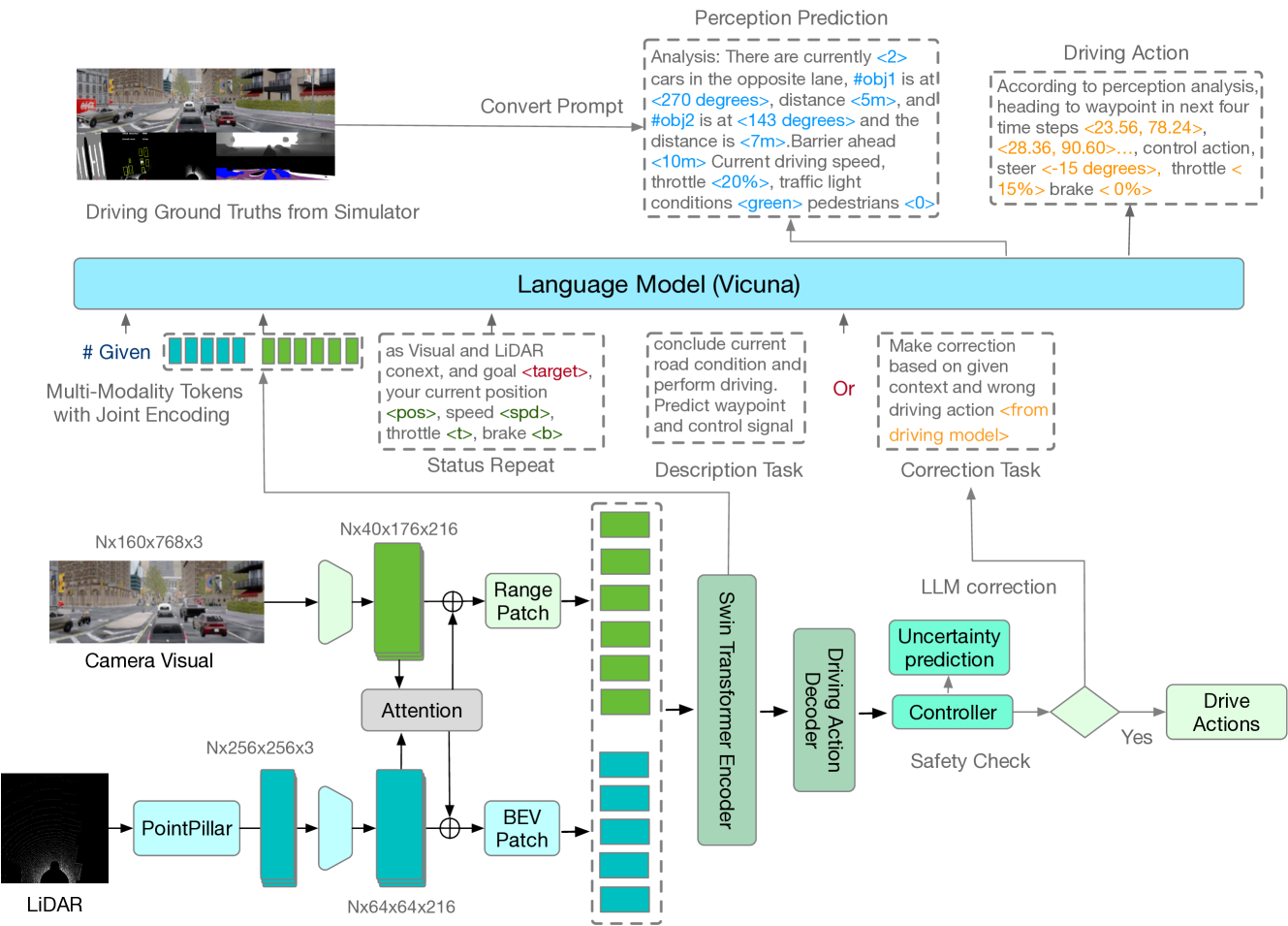
The utilization of Large Language Models (LLMs) within the realm of reinforcement learning, particularly as planners, has garnered a significant degree of attention in recent scholarly literature. However, a substantial proportion of existing research predominantly focuses on planning models for robotics that transmute the outputs derived from perception models into linguistic forms, thus adopting a `pure-language' strategy. In this research, we propose a hybrid End-to-End learning framework for autonomous driving by combining basic driving imitation learning with LLMs based on multi-modality prompt tokens. Instead of simply converting perception results from the separated train model into pure language input, our novelty lies in two aspects. 1) The end-to-end integration of visual and LiDAR sensory input into learnable multi-modality tokens, thereby intrinsically alleviating description bias by separated pre-trained perception models. 2) Instead of directly letting LLMs drive, this paper explores a hybrid setting of letting LLMs help the driving model correct mistakes and complicated scenarios. The results of our experiments suggest that the proposed methodology can attain driving scores of 49.21%, coupled with an impressive route completion rate of 91.34% in the offline evaluation conducted via CARLA. These performance metrics are comparable to the most advanced driving models.
Read more7/30/2024