Algorithmic Language Models with Neurally Compiled Libraries

0

Sign in to get full access
Overview
- This paper introduces a novel approach to developing algorithmic language models using neurally compiled libraries.
- The authors propose a framework that combines the strengths of traditional algorithmic models with the flexibility and expressiveness of neural networks.
- The key contributions include a new algorithm for compiling algorithms into neural network architectures and techniques for training and deploying these hybrid models.
Plain English Explanation
The researchers in this paper have developed a new way to create language models that combine the best of both traditional algorithms and modern neural networks. Traditionally, language models have either used strict, rule-based algorithms or flexible but often opaque neural networks. The researchers have found a way to take the core of an algorithm and compile it into a neural network architecture, giving the model the benefits of both approaches.
This allows the model to maintain the logical rigor and interpretability of an algorithm, while also gaining the expressiveness and adaptability of a neural network. The researchers describe new techniques for automatically translating algorithms into neural network designs and for training these hybrid models effectively.
The goal is to create language models that are more powerful and versatile than existing options, while still maintaining the transparency and reliability that is often lacking in neural language models. This could lead to improved performance on a range of language tasks, as well as better understanding and control of the model's inner workings.
Technical Explanation
The core innovation in this paper is a new algorithm for compiling traditional algorithmic models into neural network architectures. The authors call this approach "neurally compiled libraries" (NCLs). The key steps are:
- Algorithm Representation: The researchers develop a domain-specific language for representing algorithms in a format that can be efficiently translated into neural network components.
- Compilation: They then describe an automated compilation process that takes these algorithmic representations and generates the corresponding neural network layers, connections, and parameters.
- Hybrid Training: The paper introduces techniques for training these hybrid NCL models, which combine the algorithmic components with additional neural network layers for increased flexibility.
The authors evaluate their NCL framework on a range of language tasks, including text generation, question answering, and code simulation. They demonstrate that the hybrid NCL models can outperform both traditional algorithmic approaches and pure neural language models, while also providing better interpretability and reliability.
Critical Analysis
One key limitation of the NCL approach is the reliance on a domain-specific language for representing algorithms. This may make it challenging to apply the framework to a wide range of existing algorithms, which are often expressed in general-purpose programming languages. The authors acknowledge this and suggest that future work could explore ways to make the compilation process more flexible.
Additionally, the training of these hybrid NCL models may be more complex and computationally intensive than training purely neural models. The authors do not provide a detailed analysis of the training time and resource requirements, which would be important for understanding the practical implications of their approach.
Another area for further investigation is the interpretability and explainability of the NCL models. While the authors claim that the hybrid structure provides better transparency, it's not clear how this translates to end-user understanding of the model's decision-making process. More research is needed to understand the extent to which the algorithmic components can be effectively explained to users.
Conclusion
This paper presents a novel approach to developing language models that combines the strengths of traditional algorithms and modern neural networks. By compiling algorithmic models into neurally compiled libraries, the researchers have created a framework for building more powerful, versatile, and interpretable language models.
The key contributions of this work include the algorithm compilation process, hybrid training techniques, and initial experimental results demonstrating the potential of this approach. While there are some limitations and areas for further research, this paper represents an important step towards more advanced and transparent language models that can better serve a range of applications and users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Algorithmic Language Models with Neurally Compiled Libraries
Lucas Saldyt, Subbarao Kambhampati
Important tasks such as reasoning and planning are fundamentally algorithmic, meaning that solving them robustly requires acquiring true reasoning or planning algorithms, rather than shortcuts. Large Language Models lack true algorithmic ability primarily because of the limitations of neural network optimization algorithms, their optimization data and optimization objective, but also due to architectural inexpressivity. To solve this, our paper proposes augmenting LLMs with a library of fundamental operations and sophisticated differentiable programs, so that common algorithms do not need to be learned from scratch. We add memory, registers, basic operations, and adaptive recurrence to a transformer architecture built on LLaMA3. Then, we define a method for directly compiling algorithms into a differentiable starting library, which is used natively and propagates gradients for optimization. In this preliminary study, we explore the feasability of augmenting LLaMA3 with a differentiable computer, for instance by fine-tuning small transformers on simple algorithmic tasks with variable computational depth.
Read more7/9/2024
0
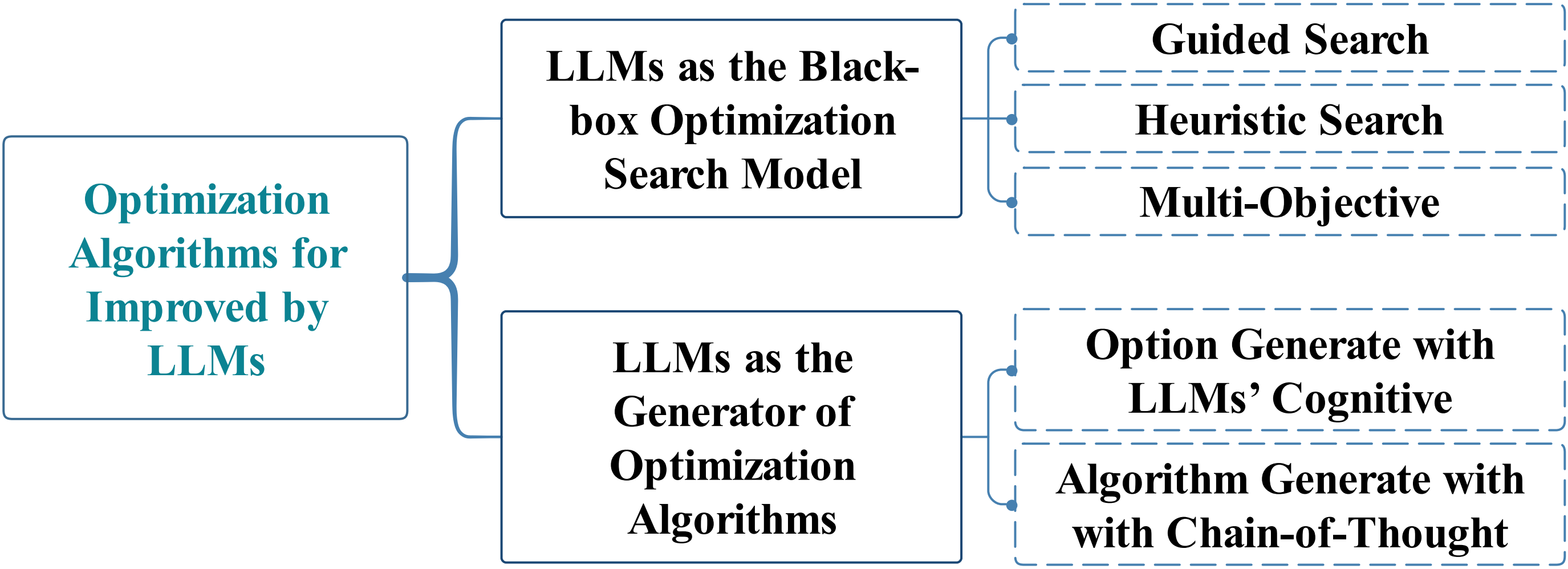
When Large Language Model Meets Optimization
Sen Huang, Kaixiang Yang, Sheng Qi, Rui Wang
Optimization algorithms and large language models (LLMs) enhance decision-making in dynamic environments by integrating artificial intelligence with traditional techniques. LLMs, with extensive domain knowledge, facilitate intelligent modeling and strategic decision-making in optimization, while optimization algorithms refine LLM architectures and output quality. This synergy offers novel approaches for advancing general AI, addressing both the computational challenges of complex problems and the application of LLMs in practical scenarios. This review outlines the progress and potential of combining LLMs with optimization algorithms, providing insights for future research directions.
Read more5/17/2024

0
Code Simulation Challenges for Large Language Models
Emanuele La Malfa, Christoph Weinhuber, Orazio Torre, Fangru Lin, Samuele Marro, Anthony Cohn, Nigel Shadbolt, Michael Wooldridge
Many reasoning, planning, and problem-solving tasks share an intrinsic algorithmic nature: correctly simulating each step is a sufficient condition to solve them correctly. This work studies to what extent Large Language Models (LLMs) can simulate coding and algorithmic tasks to provide insights into general capabilities in such algorithmic reasoning tasks. We introduce benchmarks for straight-line programs, code that contains critical paths, and approximate and redundant instructions. We further assess the simulation capabilities of LLMs with sorting algorithms and nested loops and show that a routine's computational complexity directly affects an LLM's ability to simulate its execution. While the most powerful LLMs exhibit relatively strong simulation capabilities, the process is fragile, seems to rely heavily on pattern recognition, and is affected by memorisation. We propose a novel off-the-shelf prompting method, Chain of Simulation (CoSm), which instructs LLMs to simulate code execution line by line/follow the computation pattern of compilers. CoSm efficiently helps LLMs reduce memorisation and shallow pattern recognition while improving simulation performance. We consider the success of CoSm in code simulation to be inspirational for other general routine simulation reasoning tasks.
Read more6/13/2024

1
On the Design and Analysis of LLM-Based Algorithms
Yanxi Chen, Yaliang Li, Bolin Ding, Jingren Zhou
We initiate a formal investigation into the design and analysis of LLM-based algorithms, i.e. algorithms that contain one or multiple calls of large language models (LLMs) as sub-routines and critically rely on the capabilities of LLMs. While LLM-based algorithms, ranging from basic LLM calls with prompt engineering to complicated LLM-powered agent systems and compound AI systems, have achieved remarkable empirical success, the design and optimization of them have mostly relied on heuristics and trial-and-errors, which is largely due to a lack of formal and analytical study for these algorithms. To fill this gap, we start by identifying the computational-graph representation of LLM-based algorithms, the design principle of task decomposition, and some key abstractions, which then facilitate our formal analysis for the accuracy and efficiency of LLM-based algorithms, despite the black-box nature of LLMs. Through extensive analytical and empirical investigation in a series of case studies, we demonstrate that the proposed framework is broadly applicable to a wide range of scenarios and diverse patterns of LLM-based algorithms, such as parallel, hierarchical and recursive task decomposition. Our proposed framework holds promise for advancing LLM-based algorithms, by revealing the reasons behind curious empirical phenomena, guiding the choices of hyperparameters, predicting the empirical performance of algorithms, and inspiring new algorithm design. To promote further study of LLM-based algorithms, we release our source code at https://github.com/modelscope/agentscope/tree/main/examples/paper_llm_based_algorithm.
Read more9/27/2024