Large Language Model-Enhanced Algorithm Selection: Towards Comprehensive Algorithm Representation
2311.13184
0
0
💬
Abstract
Algorithm selection, a critical process of automated machine learning, aims to identify the most suitable algorithm for solving a specific problem prior to execution. Mainstream algorithm selection techniques heavily rely on problem features, while the role of algorithm features remains largely unexplored. Due to the intrinsic complexity of algorithms, effective methods for universally extracting algorithm information are lacking. This paper takes a significant step towards bridging this gap by introducing Large Language Models (LLMs) into algorithm selection for the first time. By comprehending the code text, LLM not only captures the structural and semantic aspects of the algorithm, but also demonstrates contextual awareness and library function understanding. The high-dimensional algorithm representation extracted by LLM, after undergoing a feature selection module, is combined with the problem representation and passed to the similarity calculation module. The selected algorithm is determined by the matching degree between a given problem and different algorithms. Extensive experiments validate the performance superiority of the proposed model and the efficacy of each key module. Furthermore, we present a theoretical upper bound on model complexity, showcasing the influence of algorithm representation and feature selection modules. This provides valuable theoretical guidance for the practical implementation of our method.
Create account to get full access
Overview
- Introduces a novel approach to algorithm selection in automated machine learning (AutoML) using large language models (LLMs)
- Demonstrates how LLMs can effectively capture the structural, semantic, and contextual aspects of algorithms
- Presents a comprehensive framework for combining algorithm and problem representations to determine the most suitable algorithm
Plain English Explanation
This paper tackles the critical problem of algorithm selection in automated machine learning (AutoML). Traditionally, algorithm selection has relied heavily on problem features, while the characteristics of the algorithms themselves have been largely overlooked. This is because effectively extracting information from the intricate code that defines algorithms has been a significant challenge.
The researchers have made a groundbreaking move by introducing large language models (LLMs) into the algorithm selection process. LLMs are powerful AI systems that can comprehend and generate human-like text. By analyzing the code text of algorithms, LLMs can capture not only the structural and semantic aspects of the algorithms, but also their contextual awareness and understanding of library functions.
This high-dimensional algorithm representation is then combined with the problem representation and passed through a feature selection module. The similarity between the problem and different algorithms is calculated, and the most suitable algorithm is selected based on the best match.
The researchers have thoroughly tested their approach and found it to be superior in performance compared to existing methods. Additionally, they have provided a theoretical upper bound on the model complexity, which offers valuable guidance for the practical implementation of this technique.
Technical Explanation
The proposed framework consists of several key components:
-
Algorithm Representation: The researchers leverage LLMs to extract a high-dimensional representation of the algorithms, capturing both their structural and semantic aspects, as well as their contextual awareness and understanding of library functions.
-
Feature Selection: The high-dimensional algorithm representation is passed through a feature selection module to identify the most relevant features for the algorithm selection task.
-
Similarity Calculation: The selected algorithm features are combined with the problem representation and fed into a similarity calculation module, which determines the matching degree between the given problem and the different algorithms.
-
Algorithm Selection: The algorithm with the highest matching degree is selected as the most suitable solution for the problem at hand.
The researchers conducted extensive experiments to validate the performance of their approach, and the results demonstrate its superiority over existing algorithm selection techniques. Furthermore, they provided a theoretical upper bound on the model complexity, which offers valuable insights for the practical implementation of their method.
Critical Analysis
The researchers have made a significant contribution by introducing LLMs into the algorithm selection process, which is a novel and promising approach. However, the paper does not address some potential limitations and areas for further research:
-
Generalizability: The experiments were conducted on a limited set of algorithms and problems. Additional testing on a more diverse range of applications would be necessary to assess the generalizability of the proposed framework.
-
Interpretability: While the LLM-based algorithm representation is effective, it may lack interpretability, making it challenging to understand the underlying reasons for the algorithm selection decisions. Incorporating more interpretable components could enhance the transparency of the system.
-
Computational Efficiency: The use of LLMs may introduce computational overhead, which could be a concern for real-time or resource-constrained applications. Exploring ways to optimize the computational efficiency of the proposed framework would be beneficial.
-
Robustness: The paper does not discuss the robustness of the algorithm selection process to potential adversarial attacks or noisy input data. Investigating the resilience of the system in such scenarios would be valuable.
Conclusion
This paper presents a novel approach to algorithm selection in automated machine learning by leveraging the power of large language models. The researchers have demonstrated how LLMs can effectively capture the structural, semantic, and contextual aspects of algorithms, and how this information can be combined with problem representations to determine the most suitable algorithm for a given task.
The proposed framework has shown superior performance in extensive experiments, and the theoretical upper bound on model complexity provides valuable guidance for practical implementation. While the research is promising, further investigation into the generalizability, interpretability, computational efficiency, and robustness of the system would be beneficial to strengthen the foundation for real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
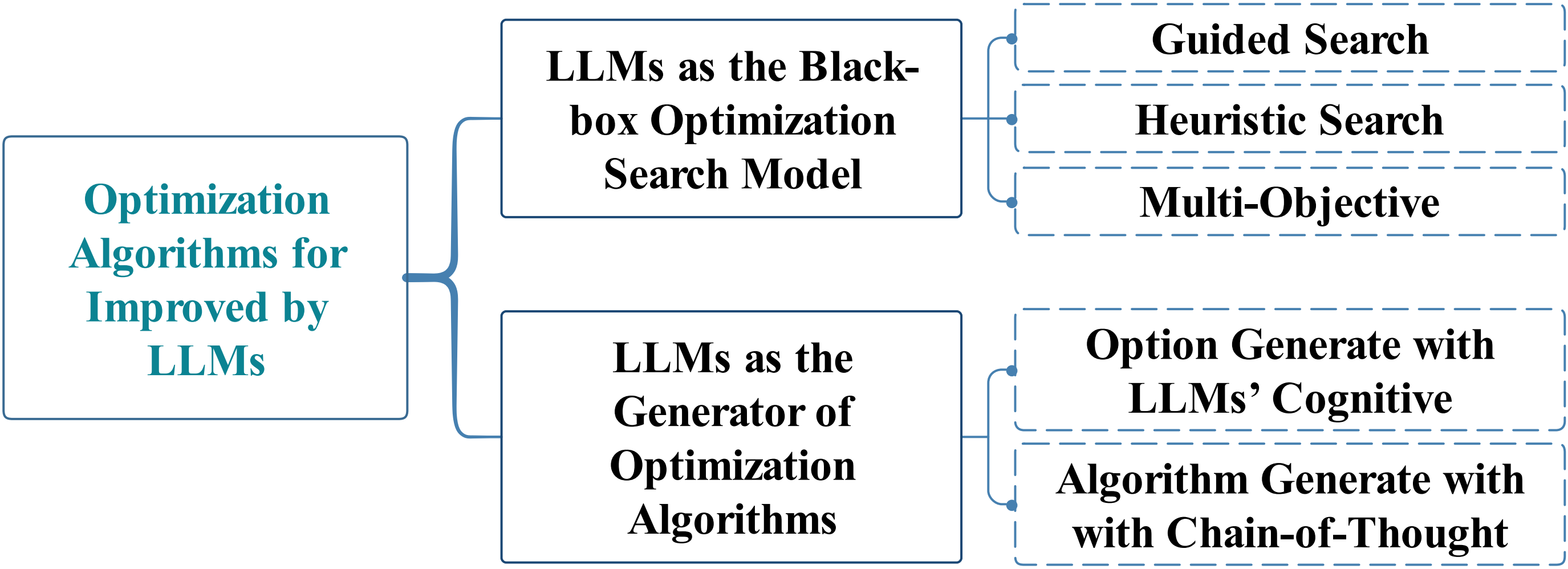
When Large Language Model Meets Optimization
Sen Huang, Kaixiang Yang, Sheng Qi, Rui Wang
0
0
Optimization algorithms and large language models (LLMs) enhance decision-making in dynamic environments by integrating artificial intelligence with traditional techniques. LLMs, with extensive domain knowledge, facilitate intelligent modeling and strategic decision-making in optimization, while optimization algorithms refine LLM architectures and output quality. This synergy offers novel approaches for advancing general AI, addressing both the computational challenges of complex problems and the application of LLMs in practical scenarios. This review outlines the progress and potential of combining LLMs with optimization algorithms, providing insights for future research directions.
5/17/2024
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Tianyu Ding, Tianyi Chen, Haidong Zhu, Jiachen Jiang, Yiqi Zhong, Jinxin Zhou, Guangzhi Wang, Zhihui Zhu, Ilya Zharkov, Luming Liang
0
0
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.
4/22/2024
💬
Efficient Large Language Models: A Survey
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang
0
0
Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding and language generation, and thus have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we organize the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. We will actively maintain the repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient LLMs research and inspire them to contribute to this important and exciting field.
5/24/2024
💬
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
0
0
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
6/19/2024