Mitigating Heterogeneity in Federated Multimodal Learning with Biomedical Vision-Language Pre-training

0

Sign in to get full access
Overview
- This paper explores how to mitigate data heterogeneity in federated multimodal learning using biomedical vision-language pre-training.
- Federated learning allows multiple parties to collaboratively train a model without sharing their data, but data heterogeneity across parties can degrade performance.
- The authors propose a method that leverages vision-language pre-training to improve performance on multimodal tasks in a federated setting.
Plain English Explanation
The paper looks at a problem in federated learning, which is a way for different organizations to train a shared AI model without sharing their private data. One challenge with federated learning is that the data held by each organization may be quite different, which can make it hard for the model to learn effectively.
To address this, the researchers use a technique called vision-language pre-training. This involves first training the model on a large dataset that combines images and text, which helps the model learn general concepts that are useful across different datasets.
The researchers then use this pre-trained model as a starting point for the federated learning process. This allows the model to leverage the knowledge gained from the pre-training, which helps it adapt better to the diverse data held by the different organizations.
Overall, the goal is to improve the performance of federated learning systems, especially for multimodal tasks that involve both images and text, by using this vision-language pre-training approach to mitigate the challenges posed by data heterogeneity.
Technical Explanation
The paper proposes a method for mitigating heterogeneity in federated multimodal learning using biomedical vision-language pre-training.
They first pre-train a multimodal model on a large biomedical dataset containing images and text. This allows the model to learn general representations that are useful across different multimodal tasks and datasets.
They then use this pre-trained model as the starting point for a federated learning process, where multiple parties collaboratively train the model without sharing their private data. The pre-training helps the model adapt more effectively to the diverse data distributions held by the different parties, mitigating the challenge of data heterogeneity in federated learning.
The authors evaluate their approach on several biomedical multimodal tasks and find that it outperforms standard federated learning baselines, demonstrating the benefits of leveraging vision-language pre-training to improve federated multimodal learning.
Critical Analysis
The paper makes a compelling case for using vision-language pre-training to address data heterogeneity in federated multimodal learning. However, a few potential limitations or areas for further research are worth noting:
-
The experiments are focused on biomedical tasks, so it's unclear how well the approach would generalize to other domains. Further testing on a wider range of multimodal applications would be valuable.
-
The paper does not explore the performance impact of the pre-training dataset size or composition. Investigating different pre-training strategies could lead to further improvements.
-
The authors acknowledge that federated learning still faces challenges around communication overhead and privacy risk. Combining their approach with advanced federated optimization techniques could help address these broader issues.
Overall, the work represents an important step forward in mitigating heterogeneity in federated multimodal learning, and the insights could have significant implications for developing more robust and inclusive AI systems.
Conclusion
This paper presents a novel method for improving federated multimodal learning by leveraging biomedical vision-language pre-training. The key insight is that pre-training the model on a large, diverse multimodal dataset can help it adapt more effectively to the heterogeneous data distributions encountered in a federated setting.
The results demonstrate the benefits of this approach, suggesting that it could be a valuable tool for building high-performance AI systems that can be collaboratively trained without compromising data privacy. As federated learning continues to gain traction, techniques like this will be crucial for unlocking its full potential across a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mitigating Heterogeneity in Federated Multimodal Learning with Biomedical Vision-Language Pre-training
Zitao Shuai, Liyue Shen
Vision-language pre-training (VLP) has arised as an efficient scheme for multimodal representation learning, but it requires large-scale multimodal data for pre-training, making it an obstacle especially for medical applications. To overcome the data limitation, federated learning (FL) can be a promising strategy to scale up the dataset for medical VLP while protecting data privacy. However, client data are often heterogeneous in real-world scenarios, and we observe that local training on heterogeneous client data would distort the multimodal representation learning and lead to biased cross-modal alignment. To address this challenge, we propose a Federated Align as IDeal (FedAID) framework for federated VLP with robustness to data heterogeneity, to bind local clients with an ideal crossmodal alignment. Specifically, to reduce distortions on global-aggregated features while learning diverse semantics from client datasets during local training, we propose to bind the cross-model aligned representation space learned by local models with an unbiased one via guidance-based regularization. Moreover, we employ a distribution-based min-max optimization to learn the unbiased cross-modal alignment at each communication turn of federated pre-training. The experiments on real-world datasets demonstrate our method successfully promotes efficient federated multimodal learning for medical VLP with data heterogeneity.
Read more5/27/2024

0
Open-Vocabulary Federated Learning with Multimodal Prototyping
Huimin Zeng, Zhenrui Yue, Dong Wang
Existing federated learning (FL) studies usually assume the training label space and test label space are identical. However, in real-world applications, this assumption is too ideal to be true. A new user could come up with queries that involve data from unseen classes, and such open-vocabulary queries would directly defect such FL systems. Therefore, in this work, we explicitly focus on the under-explored open-vocabulary challenge in FL. That is, for a new user, the global server shall understand her/his query that involves arbitrary unknown classes. To address this problem, we leverage the pre-trained vision-language models (VLMs). In particular, we present a novel adaptation framework tailored for VLMs in the context of FL, named as Federated Multimodal Prototyping (Fed-MP). Fed-MP adaptively aggregates the local model weights based on light-weight client residuals, and makes predictions based on a novel multimodal prototyping mechanism. Fed-MP exploits the knowledge learned from the seen classes, and robustifies the adapted VLM to unseen categories. Our empirical evaluation on various datasets validates the effectiveness of Fed-MP.
Read more4/3/2024
⚙️
0
Leveraging Foundation Models for Multi-modal Federated Learning with Incomplete Modality
Liwei Che, Jiaqi Wang, Xinyue Liu, Fenglong Ma
Federated learning (FL) has obtained tremendous progress in providing collaborative training solutions for distributed data silos with privacy guarantees. However, few existing works explore a more realistic scenario where the clients hold multiple data modalities. In this paper, we aim to solve a novel challenge in multi-modal federated learning (MFL) -- modality missing -- the clients may lose part of the modalities in their local data sets. To tackle the problems, we propose a novel multi-modal federated learning method, Federated Multi-modal contrastiVe training with Pre-trained completion (FedMVP), which integrates the large-scale pre-trained models to enhance the federated training. In the proposed FedMVP framework, each client deploys a large-scale pre-trained model with frozen parameters for modality completion and representation knowledge transfer, enabling efficient and robust local training. On the server side, we utilize generated data to uniformly measure the representation similarity among the uploaded client models and construct a graph perspective to aggregate them according to their importance in the system. We demonstrate that the model achieves superior performance over two real-world image-text classification datasets and is robust to the performance degradation caused by missing modality.
Read more6/18/2024
0
Vertical Federated Learning Hybrid Local Pre-training
Wenguo Li, Xinling Guo, Xu Jiao, Tiancheng Huang, Xiaoran Yan, Yao Yang
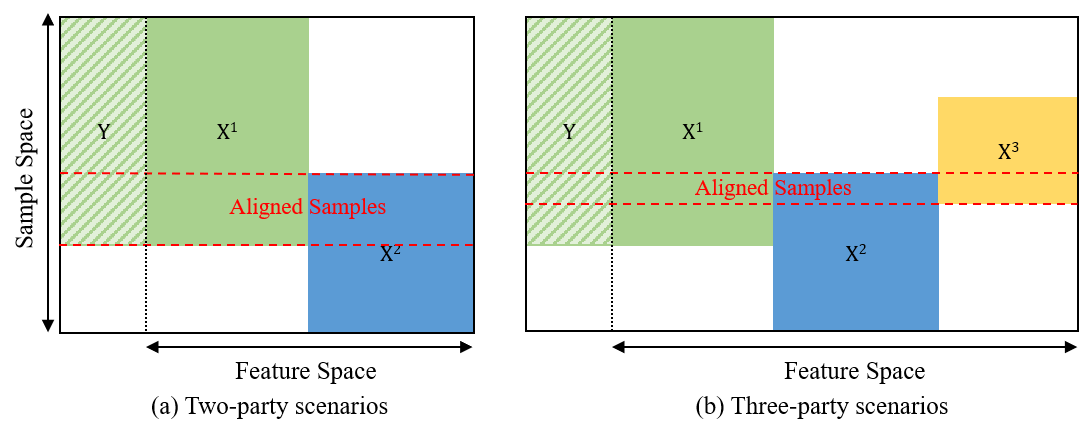
Vertical Federated Learning (VFL), which has a broad range of real-world applications, has received much attention in both academia and industry. Enterprises aspire to exploit more valuable features of the same users from diverse departments to boost their model prediction skills. VFL addresses this demand and concurrently secures individual parties from exposing their raw data. However, conventional VFL encounters a bottleneck as it only leverages aligned samples, whose size shrinks with more parties involved, resulting in data scarcity and the waste of unaligned data. To address this problem, we propose a novel VFL Hybrid Local Pre-training (VFLHLP) approach. VFLHLP first pre-trains local networks on the local data of participating parties. Then it utilizes these pre-trained networks to adjust the sub-model for the labeled party or enhance representation learning for other parties during downstream federated learning on aligned data, boosting the performance of federated models. The experimental results on real-world advertising datasets, demonstrate that our approach achieves the best performance over baseline methods by large margins. The ablation study further illustrates the contribution of each technique in VFLHLP to its overall performance.
Read more5/22/2024