Open-Vocabulary Federated Learning with Multimodal Prototyping
2404.01232
0
0

Abstract
Existing federated learning (FL) studies usually assume the training label space and test label space are identical. However, in real-world applications, this assumption is too ideal to be true. A new user could come up with queries that involve data from unseen classes, and such open-vocabulary queries would directly defect such FL systems. Therefore, in this work, we explicitly focus on the under-explored open-vocabulary challenge in FL. That is, for a new user, the global server shall understand her/his query that involves arbitrary unknown classes. To address this problem, we leverage the pre-trained vision-language models (VLMs). In particular, we present a novel adaptation framework tailored for VLMs in the context of FL, named as Federated Multimodal Prototyping (Fed-MP). Fed-MP adaptively aggregates the local model weights based on light-weight client residuals, and makes predictions based on a novel multimodal prototyping mechanism. Fed-MP exploits the knowledge learned from the seen classes, and robustifies the adapted VLM to unseen categories. Our empirical evaluation on various datasets validates the effectiveness of Fed-MP.
Create account to get full access
Overview
• The paper explores "open-vocabulary federated learning with multimodal prototyping", which aims to improve the performance of machine learning models by leveraging diverse data and collaboration across different organizations.
• Federated learning allows multiple organizations to train a shared model without directly sharing their private data. Multimodal prototyping uses a combination of text, images, and other data types to create more robust models.
• The proposed approach combines these two techniques to enable organizations to collaboratively train models on a wide range of data, without compromising privacy.
Plain English Explanation
Machine learning models are powerful tools, but they often struggle when facing new or unfamiliar data. This paper presents a novel technique to address this challenge.
The key idea is to have multiple organizations work together to train a single model, without anyone having to share their private data. Each organization contributes their unique data and knowledge, allowing the model to learn from a much broader range of information.
This collaborative "federated learning" approach is combined with the use of "multimodal prototyping". Rather than relying on a single data type like text, the model is trained on a diverse mix of text, images, and other modalities. This makes the model more versatile and able to handle a wider variety of real-world scenarios.
By bringing these two ideas together, the researchers have created a system that can produce highly capable machine learning models, while still protecting the privacy of the participating organizations. This could enable new applications and services that were previously infeasible due to data access or privacy constraints.
Technical Explanation
The paper proposes a federated learning framework that leverages multimodal prototyping to improve model performance on open-vocabulary tasks. The key components are:
-
Federated Learning: The model is trained collaboratively across multiple organizations, without any organization sharing their raw data. This preserves privacy while enabling the model to learn from diverse data sources.
-
Multimodal Prototyping: The model is trained on a mix of text, images, and other modalities. This allows it to build a more comprehensive understanding of concepts, rather than relying solely on textual information.
-
Open-Vocabulary Learning: The model is designed to handle a dynamic, open-ended vocabulary, rather than being limited to a fixed set of known entities or classes. This enhances the model's real-world applicability.
The researchers evaluate their approach on several benchmark tasks, demonstrating improvements over federated learning baselines that use unimodal data. The results suggest that the combination of federated learning and multimodal prototyping can indeed produce more capable and adaptable machine learning models.
Critical Analysis
The paper presents a well-designed study that makes a compelling case for the proposed approach. However, a few points are worth considering:
-
The experiments are conducted on idealized benchmark datasets, which may not fully capture the complexities of real-world federated learning scenarios. Further evaluation on more diverse, realistic data would help validate the practical benefits.
-
The paper does not address potential challenges around incentivizing organizations to participate in the federated learning process or managing the complexities of multi-party collaboration.
-
While the open-vocabulary aspect is a strength, the authors do not explore how the model might handle rare or emerging concepts that are not well-represented in the training data.
Overall, the research represents a significant advance in federated learning and multimodal learning, with promising implications for privacy-preserving machine learning applications. Further investigation of the practical deployment and scalability considerations would help strengthen the impact of this work.
Conclusion
This paper introduces an innovative approach that combines federated learning and multimodal prototyping to enable open-vocabulary machine learning while preserving privacy. By allowing multiple organizations to collaboratively train a shared model using diverse data sources, the researchers have developed a system that can produce more capable and adaptable models than traditional federated learning methods.
The results demonstrate the potential for this technique to unlock new applications and services that were previously constrained by data access or privacy concerns. As the field of machine learning continues to evolve, techniques like this that balance performance and privacy will become increasingly crucial for realizing the full benefits of AI technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Mitigating Heterogeneity in Federated Multimodal Learning with Biomedical Vision-Language Pre-training
Zitao Shuai, Liyue Shen
0
0
Vision-language pre-training (VLP) has arised as an efficient scheme for multimodal representation learning, but it requires large-scale multimodal data for pre-training, making it an obstacle especially for medical applications. To overcome the data limitation, federated learning (FL) can be a promising strategy to scale up the dataset for medical VLP while protecting data privacy. However, client data are often heterogeneous in real-world scenarios, and we observe that local training on heterogeneous client data would distort the multimodal representation learning and lead to biased cross-modal alignment. To address this challenge, we propose a Federated Align as IDeal (FedAID) framework for federated VLP with robustness to data heterogeneity, to bind local clients with an ideal crossmodal alignment. Specifically, to reduce distortions on global-aggregated features while learning diverse semantics from client datasets during local training, we propose to bind the cross-model aligned representation space learned by local models with an unbiased one via guidance-based regularization. Moreover, we employ a distribution-based min-max optimization to learn the unbiased cross-modal alignment at each communication turn of federated pre-training. The experiments on real-world datasets demonstrate our method successfully promotes efficient federated multimodal learning for medical VLP with data heterogeneity.
5/27/2024
⚙️
Leveraging Foundation Models for Multi-modal Federated Learning with Incomplete Modality
Liwei Che, Jiaqi Wang, Xinyue Liu, Fenglong Ma
0
0
Federated learning (FL) has obtained tremendous progress in providing collaborative training solutions for distributed data silos with privacy guarantees. However, few existing works explore a more realistic scenario where the clients hold multiple data modalities. In this paper, we aim to solve a novel challenge in multi-modal federated learning (MFL) -- modality missing -- the clients may lose part of the modalities in their local data sets. To tackle the problems, we propose a novel multi-modal federated learning method, Federated Multi-modal contrastiVe training with Pre-trained completion (FedMVP), which integrates the large-scale pre-trained models to enhance the federated training. In the proposed FedMVP framework, each client deploys a large-scale pre-trained model with frozen parameters for modality completion and representation knowledge transfer, enabling efficient and robust local training. On the server side, we utilize generated data to uniformly measure the representation similarity among the uploaded client models and construct a graph perspective to aggregate them according to their importance in the system. We demonstrate that the model achieves superior performance over two real-world image-text classification datasets and is robust to the performance degradation caused by missing modality.
6/18/2024
🐍
FLoRA: Enhancing Vision-Language Models with Parameter-Efficient Federated Learning
Duy Phuong Nguyen, J. Pablo Munoz, Ali Jannesari
0
0
In the rapidly evolving field of artificial intelligence, multimodal models, e.g., integrating vision and language into visual-language models (VLMs), have become pivotal for many applications, ranging from image captioning to multimodal search engines. Among these models, the Contrastive Language-Image Pre-training (CLIP) model has demonstrated remarkable performance in understanding and generating nuanced relationships between text and images. However, the conventional training of such models often requires centralized aggregation of vast datasets, posing significant privacy and data governance challenges. To address these concerns, this paper proposes a novel approach that leverages Federated Learning and parameter-efficient adapters, i.e., Low-Rank Adaptation (LoRA), to train VLMs. This methodology preserves data privacy by training models across decentralized data sources and ensures model adaptability and efficiency through LoRA's parameter-efficient fine-tuning. Our approach accelerates training time by up to 34.72 times and requires 2.47 times less memory usage than full fine-tuning.
4/24/2024
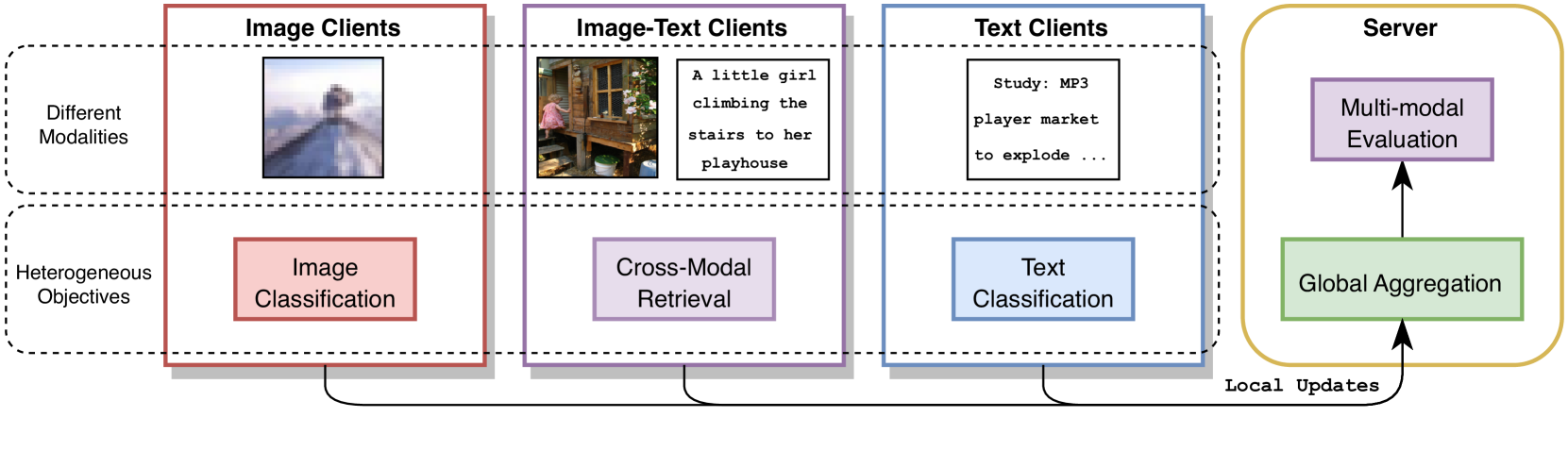
Towards Multi-modal Transformers in Federated Learning
Guangyu Sun, Matias Mendieta, Aritra Dutta, Xin Li, Chen Chen
0
0
Multi-modal transformers mark significant progress in different domains, but siloed high-quality data hinders their further improvement. To remedy this, federated learning (FL) has emerged as a promising privacy-preserving paradigm for training models without direct access to the raw data held by different clients. Despite its potential, a considerable research direction regarding the unpaired uni-modal clients and the transformer architecture in FL remains unexplored. To fill this gap, this paper explores a transfer multi-modal federated learning (MFL) scenario within the vision-language domain, where clients possess data of various modalities distributed across different datasets. We systematically evaluate the performance of existing methods when a transformer architecture is utilized and introduce a novel framework called Federated modality complementary and collaboration (FedCola) by addressing the in-modality and cross-modality gaps among clients. Through extensive experiments across various FL settings, FedCola demonstrates superior performance over previous approaches, offering new perspectives on future federated training of multi-modal transformers.
4/22/2024