Aligning LLMs for FL-free Program Repair
2404.08877
0
0
Abstract
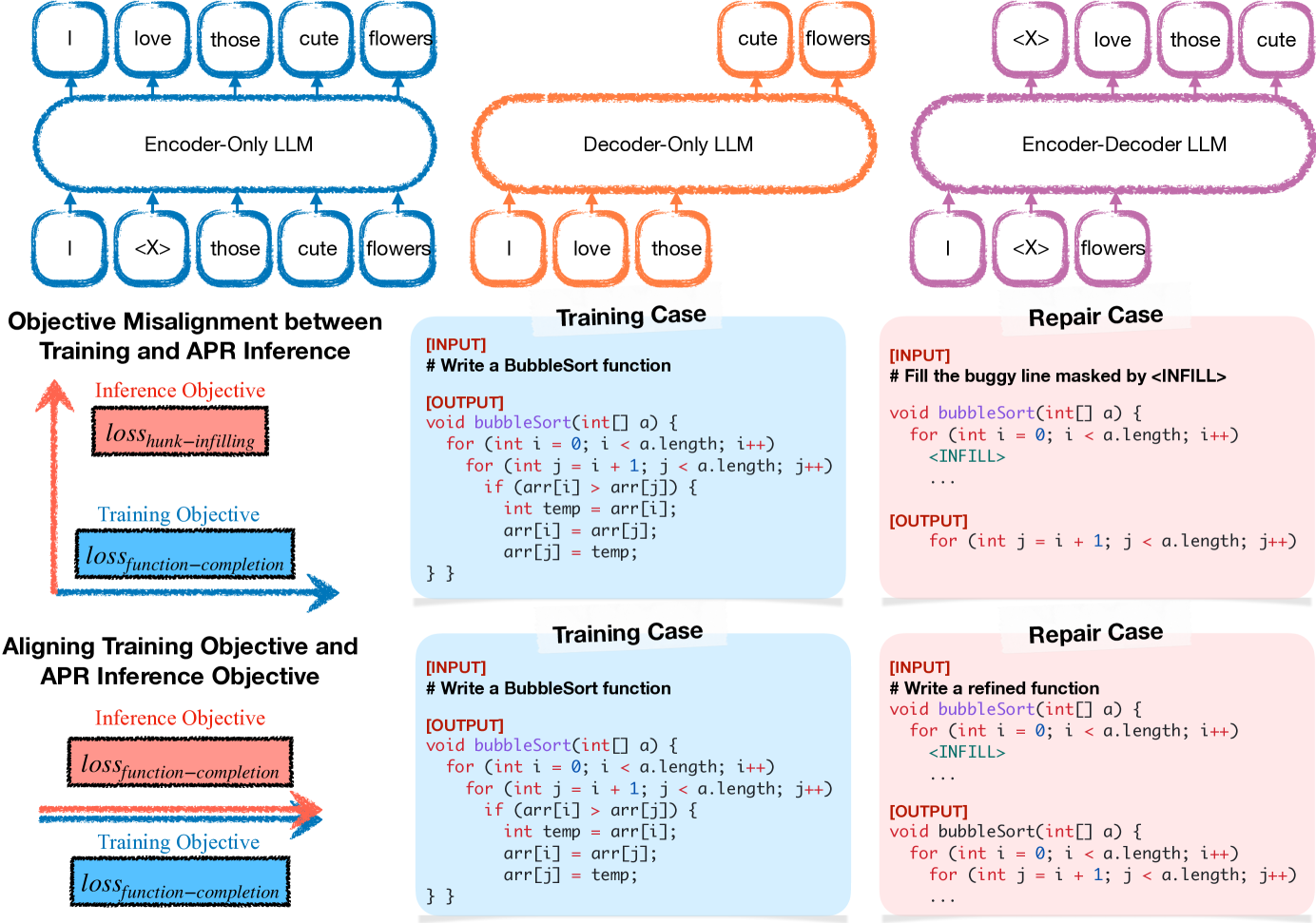
Large language models (LLMs) have achieved decent results on automated program repair (APR). However, the next token prediction training objective of decoder-only LLMs (e.g., GPT-4) is misaligned with the masked span prediction objective of current infilling-style methods, which impedes LLMs from fully leveraging pre-trained knowledge for program repair. In addition, while some LLMs are capable of locating and repairing bugs end-to-end when using the related artifacts (e.g., test cases) as input, existing methods regard them as separate tasks and ask LLMs to generate patches at fixed locations. This restriction hinders LLMs from exploring potential patches beyond the given locations. In this paper, we investigate a new approach to adapt LLMs to program repair. Our core insight is that LLM's APR capability can be greatly improved by simply aligning the output to their training objective and allowing them to refine the whole program without first performing fault localization. Based on this insight, we designed D4C, a straightforward prompting framework for APR. D4C can repair 180 bugs correctly in Defects4J, with each patch being sampled only 10 times. This surpasses the SOTA APR methods with perfect fault localization by 10% and reduces the patch sampling number by 90%. Our findings reveal that (1) objective alignment is crucial for fully exploiting LLM's pre-trained capability, and (2) replacing the traditional localize-then-repair workflow with direct debugging is more effective for LLM-based APR methods. Thus, we believe this paper introduces a new mindset for harnessing LLMs in APR.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores techniques for aligning large language models (LLMs) to enable FL-free (Federated Learning-free) program repair, a method of automatically fixing software bugs without the need for federated learning.
- The authors investigate different LLM architectures and training objectives to improve the performance of LLMs in the context of program repair.
- The paper aims to provide insights into the strengths and limitations of various LLM approaches in the program repair domain.
Plain English Explanation
The paper is about using large language models (LLMs) to automatically fix software bugs without the need for a technique called federated learning. Federated learning is a way of training AI models using data from multiple devices or organizations without sharing the raw data.
The researchers explore different ways of designing and training LLMs to make them better at the task of program repair, which is the process of automatically fixing bugs in computer programs. They look at how the architecture (the way the model is structured) and the training objectives (what the model is trying to learn) can impact the performance of LLMs in this context.
The goal is to provide a better understanding of the strengths and weaknesses of different LLM approaches when it comes to program repair, without relying on federated learning. This could help developers and researchers create more effective AI-powered tools for automatically fixing software issues.
Technical Explanation
The paper investigates the use of large language models (LLMs) for FL-free (Federated Learning-free) program repair. The authors explore different LLM architectures and training objectives to improve the performance of LLMs in the context of program repair.
The authors discuss the potential of using CodeCLM, a language model tailored for code, to align LLMs with the task of program repair. They also explore the use of //: # (Internal link: https://aimodels.fyi/papers/arxiv/latent-distance-guided-alignment-training-large-language)latent distance-guided alignment training to improve the performance of LLMs on program repair tasks.
//: # (Internal link: https://aimodels.fyi/papers/arxiv/large-language-model-vulnerability-detection-repair-literature)The paper also reviews the existing literature on the use of large language models for vulnerability detection and program repair, providing a comprehensive overview of the state of the art in this field.
Critical Analysis
The paper presents a thorough investigation of the use of large language models for FL-free program repair. The authors acknowledge the limitations of their approach, such as the potential for LLMs to exhibit biases or make incorrect inferences, which could impact their performance on program repair tasks.
//: # (Internal link: https://aimodels.fyi/papers/arxiv/how-effective-are-neural-networks-fixing-security)Additionally, the authors mention the need for further research to understand the effectiveness of LLMs in fixing security-related bugs, as this is a critical aspect of program repair.
//: # (Internal link: https://aimodels.fyi/papers/arxiv/peer-aided-repairer-empowering-large-language-models)The paper also highlights the potential of incorporating peer-aided repair techniques, which leverage the knowledge of multiple LLMs, to improve the overall performance of the program repair system.
Conclusion
This paper provides valuable insights into the use of large language models for FL-free program repair. The authors explore various LLM architectures and training objectives, offering a comprehensive understanding of the strengths and limitations of this approach.
The findings from this research could inform the development of more effective AI-powered tools for automatic program repair, which could have significant implications for software development and maintenance. However, the authors also identify areas for further research, such as addressing biases and improving the effectiveness of LLMs in fixing security-related bugs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Automated Program Repair: Emerging trends pose and expose problems for benchmarks
Joseph Renzullo, Pemma Reiter, Westley Weimer, Stephanie Forrest
0
0
Machine learning (ML) now pervades the field of Automated Program Repair (APR). Algorithms deploy neural machine translation and large language models (LLMs) to generate software patches, among other tasks. But, there are important differences between these applications of ML and earlier work. Evaluations and comparisons must take care to ensure that results are valid and likely to generalize. A challenge is that the most popular APR evaluation benchmarks were not designed with ML techniques in mind. This is especially true for LLMs, whose large and often poorly-disclosed training datasets may include problems on which they are evaluated.
5/10/2024
🧠
How Effective Are Neural Networks for Fixing Security Vulnerabilities
Yi Wu, Nan Jiang, Hung Viet Pham, Thibaud Lutellier, Jordan Davis, Lin Tan, Petr Babkin, Sameena Shah
0
0
Security vulnerability repair is a difficult task that is in dire need of automation. Two groups of techniques have shown promise: (1) large code language models (LLMs) that have been pre-trained on source code for tasks such as code completion, and (2) automated program repair (APR) techniques that use deep learning (DL) models to automatically fix software bugs. This paper is the first to study and compare Java vulnerability repair capabilities of LLMs and DL-based APR models. The contributions include that we (1) apply and evaluate five LLMs (Codex, CodeGen, CodeT5, PLBART and InCoder), four fine-tuned LLMs, and four DL-based APR techniques on two real-world Java vulnerability benchmarks (Vul4J and VJBench), (2) design code transformations to address the training and test data overlapping threat to Codex, (3) create a new Java vulnerability repair benchmark VJBench, and its transformed version VJBench-trans and (4) evaluate LLMs and APR techniques on the transformed vulnerabilities in VJBench-trans. Our findings include that (1) existing LLMs and APR models fix very few Java vulnerabilities. Codex fixes 10.2 (20.4%), the most number of vulnerabilities. (2) Fine-tuning with general APR data improves LLMs' vulnerability-fixing capabilities. (3) Our new VJBench reveals that LLMs and APR models fail to fix many Common Weakness Enumeration (CWE) types, such as CWE-325 Missing cryptographic step and CWE-444 HTTP request smuggling. (4) Codex still fixes 8.3 transformed vulnerabilities, outperforming all the other LLMs and APR models on transformed vulnerabilities. The results call for innovations to enhance automated Java vulnerability repair such as creating larger vulnerability repair training data, tuning LLMs with such data, and applying code simplification transformation to facilitate vulnerability repair.
4/3/2024

Peer-aided Repairer: Empowering Large Language Models to Repair Advanced Student Assignments
Qianhui Zhao, Fang Liu, Li Zhang, Yang Liu, Zhen Yan, Zhenghao Chen, Yufei Zhou, Jing Jiang, Ge Li
0
0
Automated generation of feedback on programming assignments holds significant benefits for programming education, especially when it comes to advanced assignments. Automated Program Repair techniques, especially Large Language Model based approaches, have gained notable recognition for their potential to fix introductory assignments. However, the programs used for evaluation are relatively simple. It remains unclear how existing approaches perform in repairing programs from higher-level programming courses. To address these limitations, we curate a new advanced student assignment dataset named Defects4DS from a higher-level programming course. Subsequently, we identify the challenges related to fixing bugs in advanced assignments. Based on the analysis, we develop a framework called PaR that is powered by the LLM. PaR works in three phases: Peer Solution Selection, Multi-Source Prompt Generation, and Program Repair. Peer Solution Selection identifies the closely related peer programs based on lexical, semantic, and syntactic criteria. Then Multi-Source Prompt Generation adeptly combines multiple sources of information to create a comprehensive and informative prompt for the last Program Repair stage. The evaluation on Defects4DS and another well-investigated ITSP dataset reveals that PaR achieves a new state-of-the-art performance, demonstrating impressive improvements of 19.94% and 15.2% in repair rate compared to prior state-of-the-art LLM- and symbolic-based approaches, respectively
4/3/2024
Benchmarking Educational Program Repair
Charles Koutcheme, Nicola Dainese, Sami Sarsa, Juho Leinonen, Arto Hellas, Paul Denny
0
0
The emergence of large language models (LLMs) has sparked enormous interest due to their potential application across a range of educational tasks. For example, recent work in programming education has used LLMs to generate learning resources, improve error messages, and provide feedback on code. However, one factor that limits progress within the field is that much of the research uses bespoke datasets and different evaluation metrics, making direct comparisons between results unreliable. Thus, there is a pressing need for standardization and benchmarks that facilitate the equitable comparison of competing approaches. One task where LLMs show great promise is program repair, which can be used to provide debugging support and next-step hints to students. In this article, we propose a novel educational program repair benchmark. We curate two high-quality publicly available programming datasets, present a unified evaluation procedure introducing a novel evaluation metric rouge@k for approximating the quality of repairs, and evaluate a set of five recent models to establish baseline performance.
5/10/2024