How Effective Are Neural Networks for Fixing Security Vulnerabilities
2305.18607
0
0
🧠
Abstract
Security vulnerability repair is a difficult task that is in dire need of automation. Two groups of techniques have shown promise: (1) large code language models (LLMs) that have been pre-trained on source code for tasks such as code completion, and (2) automated program repair (APR) techniques that use deep learning (DL) models to automatically fix software bugs. This paper is the first to study and compare Java vulnerability repair capabilities of LLMs and DL-based APR models. The contributions include that we (1) apply and evaluate five LLMs (Codex, CodeGen, CodeT5, PLBART and InCoder), four fine-tuned LLMs, and four DL-based APR techniques on two real-world Java vulnerability benchmarks (Vul4J and VJBench), (2) design code transformations to address the training and test data overlapping threat to Codex, (3) create a new Java vulnerability repair benchmark VJBench, and its transformed version VJBench-trans and (4) evaluate LLMs and APR techniques on the transformed vulnerabilities in VJBench-trans. Our findings include that (1) existing LLMs and APR models fix very few Java vulnerabilities. Codex fixes 10.2 (20.4%), the most number of vulnerabilities. (2) Fine-tuning with general APR data improves LLMs' vulnerability-fixing capabilities. (3) Our new VJBench reveals that LLMs and APR models fail to fix many Common Weakness Enumeration (CWE) types, such as CWE-325 Missing cryptographic step and CWE-444 HTTP request smuggling. (4) Codex still fixes 8.3 transformed vulnerabilities, outperforming all the other LLMs and APR models on transformed vulnerabilities. The results call for innovations to enhance automated Java vulnerability repair such as creating larger vulnerability repair training data, tuning LLMs with such data, and applying code simplification transformation to facilitate vulnerability repair.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Automating the repair of software security vulnerabilities is a pressing need in the industry.
- Two promising approaches have emerged: (1) large language models pre-trained on code, and (2) deep learning-based automated program repair techniques.
- This paper is the first to compare the Java vulnerability repair capabilities of these two approaches.
Plain English Explanation
Fixing software security holes is a difficult and time-consuming task. Researchers are exploring ways to automate this process to make it faster and more efficient. Two main strategies have shown promise:
-
Large Language Models (LLMs): These are powerful AI models that have been trained on vast amounts of computer code. They can be used for tasks like predicting the next line of code or even generating new code snippets.
-
Automated Program Repair (APR): These techniques use deep learning models to automatically detect and fix software bugs, including security vulnerabilities.
The researchers in this paper wanted to see how well these two approaches perform at repairing Java vulnerabilities. They tested several LLMs and APR models on real-world Java security benchmarks to understand their strengths and weaknesses.
Technical Explanation
The researchers applied and evaluated five LLMs (Codex, CodeGen, CodeT5, PLBART, and InCoder) and four fine-tuned LLMs, as well as four DL-based APR techniques, on two Java vulnerability benchmarks: Vul4J and VJBench.
To address the potential issue of training and test data overlap with Codex, they designed code transformations to create a new benchmark called VJBench-trans.
The key findings include:
- Existing LLMs and APR models can only fix a small number of Java vulnerabilities, with Codex fixing the most at 10.2 (20.4%).
- Fine-tuning LLMs with general APR data improves their vulnerability-fixing capabilities.
- The new VJBench benchmark revealed that LLMs and APR models struggle with certain Common Weakness Enumeration (CWE) types, such as missing cryptographic steps and HTTP request smuggling.
- Codex still outperformed the other models on the transformed vulnerabilities in VJBench-trans, fixing 8.3 of them.
Critical Analysis
The paper highlights the limitations of current LLMs and APR techniques in repairing Java vulnerabilities, particularly for certain types of security flaws. This suggests that more work is needed to develop models that can effectively handle the complexity and diversity of real-world software vulnerabilities.
The researchers acknowledge the potential issue of training-test data overlap and address it by creating the VJBench-trans benchmark. However, it would be interesting to see how the models perform on an even more diverse set of vulnerabilities to better understand their generalization capabilities.
Additionally, the paper does not delve into the reasons why the models struggle with certain CWE types. Further analysis of the model failures could provide valuable insights to guide future research in this area.
Conclusion
This paper presents a comprehensive evaluation of LLMs and APR techniques for Java vulnerability repair, highlighting their current limitations and the need for continued innovation in this important field. The insights from this research can inform the development of more robust and versatile solutions for automatically fixing software security flaws, ultimately making systems more secure and resilient.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Automated Program Repair: Emerging trends pose and expose problems for benchmarks
Joseph Renzullo, Pemma Reiter, Westley Weimer, Stephanie Forrest
0
0
Machine learning (ML) now pervades the field of Automated Program Repair (APR). Algorithms deploy neural machine translation and large language models (LLMs) to generate software patches, among other tasks. But, there are important differences between these applications of ML and earlier work. Evaluations and comparisons must take care to ensure that results are valid and likely to generalize. A challenge is that the most popular APR evaluation benchmarks were not designed with ML techniques in mind. This is especially true for LLMs, whose large and often poorly-disclosed training datasets may include problems on which they are evaluated.
5/10/2024
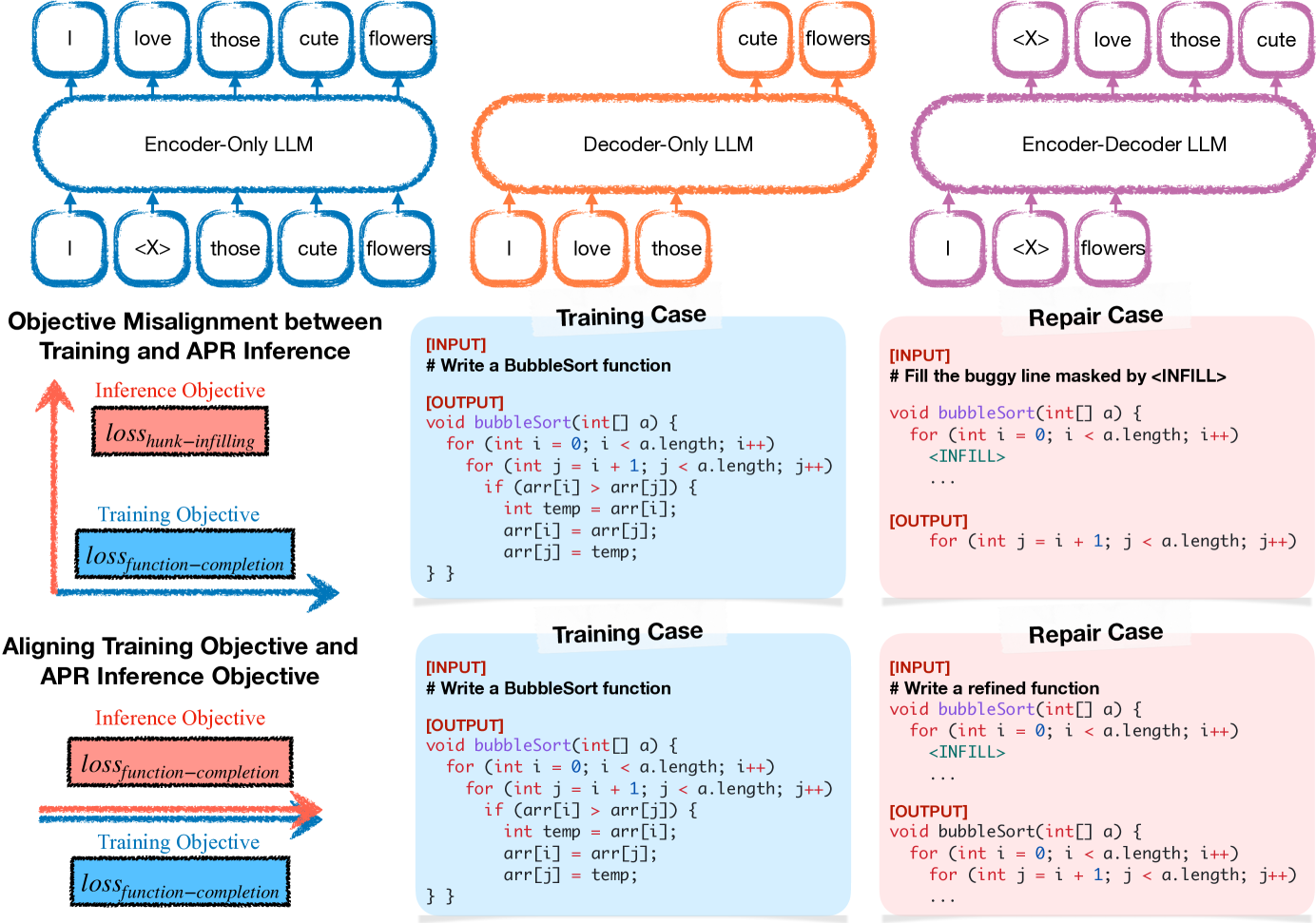
Aligning LLMs for FL-free Program Repair
Junjielong Xu, Ying Fu, Shin Hwei Tan, Pinjia He
0
0
Large language models (LLMs) have achieved decent results on automated program repair (APR). However, the next token prediction training objective of decoder-only LLMs (e.g., GPT-4) is misaligned with the masked span prediction objective of current infilling-style methods, which impedes LLMs from fully leveraging pre-trained knowledge for program repair. In addition, while some LLMs are capable of locating and repairing bugs end-to-end when using the related artifacts (e.g., test cases) as input, existing methods regard them as separate tasks and ask LLMs to generate patches at fixed locations. This restriction hinders LLMs from exploring potential patches beyond the given locations. In this paper, we investigate a new approach to adapt LLMs to program repair. Our core insight is that LLM's APR capability can be greatly improved by simply aligning the output to their training objective and allowing them to refine the whole program without first performing fault localization. Based on this insight, we designed D4C, a straightforward prompting framework for APR. D4C can repair 180 bugs correctly in Defects4J, with each patch being sampled only 10 times. This surpasses the SOTA APR methods with perfect fault localization by 10% and reduces the patch sampling number by 90%. Our findings reveal that (1) objective alignment is crucial for fully exploiting LLM's pre-trained capability, and (2) replacing the traditional localize-then-repair workflow with direct debugging is more effective for LLM-based APR methods. Thus, we believe this paper introduces a new mindset for harnessing LLMs in APR.
4/16/2024
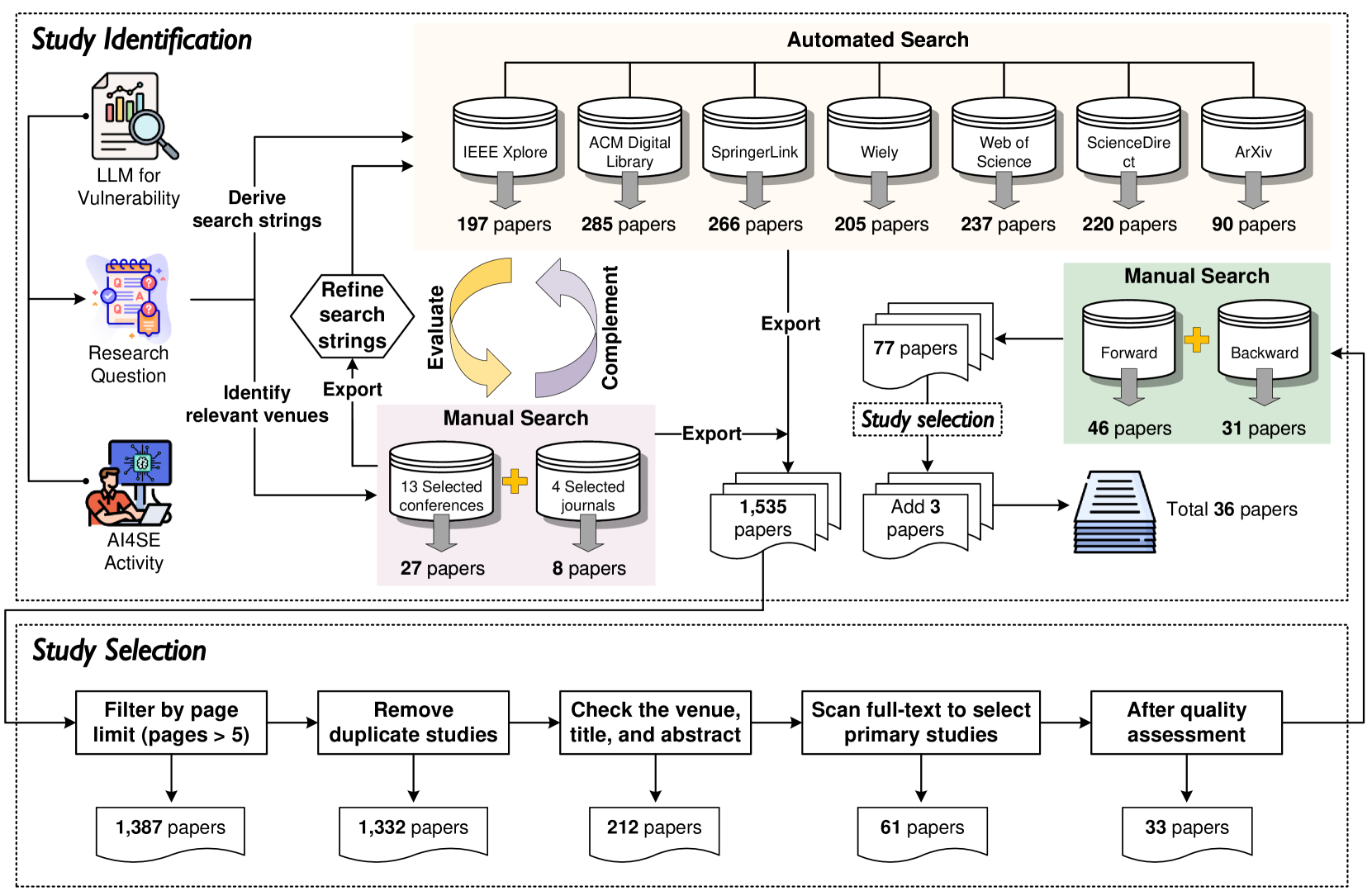
Large Language Model for Vulnerability Detection and Repair: Literature Review and Roadmap
Xin Zhou, Sicong Cao, Xiaobing Sun, David Lo
0
0
The significant advancements in Large Language Models (LLMs) have resulted in their widespread adoption across various tasks within Software Engineering (SE), including vulnerability detection and repair. Numerous recent studies have investigated the application of LLMs to enhance vulnerability detection and repair tasks. Despite the increasing research interest, there is currently no existing survey that focuses on the utilization of LLMs for vulnerability detection and repair. In this paper, we aim to bridge this gap by offering a systematic literature review of approaches aimed at improving vulnerability detection and repair through the utilization of LLMs. The review encompasses research work from leading SE, AI, and Security conferences and journals, covering 36 papers published at 21 distinct venues. By answering three key research questions, we aim to (1) summarize the LLMs employed in the relevant literature, (2) categorize various LLM adaptation techniques in vulnerability detection, and (3) classify various LLM adaptation techniques in vulnerability repair. Based on our findings, we have identified a series of challenges that still need to be tackled considering existing studies. Additionally, we have outlined a roadmap highlighting potential opportunities that we believe are pertinent and crucial for future research endeavors.
4/4/2024
Automated Repair of AI Code with Large Language Models and Formal Verification
Yiannis Charalambous, Edoardo Manino, Lucas C. Cordeiro
0
0
The next generation of AI systems requires strong safety guarantees. This report looks at the software implementation of neural networks and related memory safety properties, including NULL pointer deference, out-of-bound access, double-free, and memory leaks. Our goal is to detect these vulnerabilities, and automatically repair them with the help of large language models. To this end, we first expand the size of NeuroCodeBench, an existing dataset of neural network code, to about 81k programs via an automated process of program mutation. Then, we verify the memory safety of the mutated neural network implementations with ESBMC, a state-of-the-art software verifier. Whenever ESBMC spots a vulnerability, we invoke a large language model to repair the source code. For the latest task, we compare the performance of various state-of-the-art prompt engineering techniques, and an iterative approach that repeatedly calls the large language model.
5/16/2024