Peer-aided Repairer: Empowering Large Language Models to Repair Advanced Student Assignments
2404.01754
0
0

Abstract
Automated generation of feedback on programming assignments holds significant benefits for programming education, especially when it comes to advanced assignments. Automated Program Repair techniques, especially Large Language Model based approaches, have gained notable recognition for their potential to fix introductory assignments. However, the programs used for evaluation are relatively simple. It remains unclear how existing approaches perform in repairing programs from higher-level programming courses. To address these limitations, we curate a new advanced student assignment dataset named Defects4DS from a higher-level programming course. Subsequently, we identify the challenges related to fixing bugs in advanced assignments. Based on the analysis, we develop a framework called PaR that is powered by the LLM. PaR works in three phases: Peer Solution Selection, Multi-Source Prompt Generation, and Program Repair. Peer Solution Selection identifies the closely related peer programs based on lexical, semantic, and syntactic criteria. Then Multi-Source Prompt Generation adeptly combines multiple sources of information to create a comprehensive and informative prompt for the last Program Repair stage. The evaluation on Defects4DS and another well-investigated ITSP dataset reveals that PaR achieves a new state-of-the-art performance, demonstrating impressive improvements of 19.94% and 15.2% in repair rate compared to prior state-of-the-art LLM- and symbolic-based approaches, respectively
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how large language models, which are powerful AI systems trained on vast amounts of text data, can be used to help repair and improve advanced student assignments.
- The researchers developed a "Peer-aided Repairer" system that allows language models to provide feedback and suggestions for improving student work, drawing inspiration from how human peers provide constructive criticism.
- Experiments show the system can outperform traditional methods for providing feedback on complex student assignments, with the potential to enhance learning and writing skills.
Plain English Explanation
Large language models are AI systems that have been trained on huge amounts of text data, allowing them to understand and generate human-like language. The researchers in this paper explored how these powerful models could be used to help improve advanced student assignments.
Normally, providing meaningful feedback on complex student work can be challenging, especially for instructors dealing with large class sizes. The researchers developed a "Peer-aided Repairer" system that taps into the language understanding capabilities of large models to provide constructive feedback, similar to how human classmates might review and critique each other's work.
The key insight is that language models can be trained not just to generate text, but to analyze it and identify areas for improvement. By feeding student assignments into the Peer-aided Repairer, the system can highlight strengths, weaknesses, and specific suggestions for revision - just as a human peer reviewer might do.
Through experiments, the researchers found their Peer-aided Repairer outperformed traditional feedback methods, suggesting it could be a powerful tool for enhancing student learning and writing skills. The language model's ability to provide nuanced, contextual feedback appears to be more effective than simple automated scoring or generic comments from instructors.
Technical Explanation
The core of the Peer-aided Repairer system is a large language model that has been fine-tuned on a dataset of peer reviews and feedback on advanced student assignments. This allows the model to learn the patterns and techniques used by human reviewers when providing constructive criticism.
When a new student assignment is input, the language model analyzes the text and generates feedback highlighting strengths, weaknesses, and specific suggestions for improvement. This feedback is structured to mimic the style and tone of helpful peer reviews, drawing on the model's understanding of effective revision strategies.
The researchers conducted experiments comparing the Peer-aided Repairer to traditional feedback methods, such as instructor comments and generic automated scoring. They found the language model-powered system was able to provide more nuanced, contextual feedback that led to greater improvements in student writing.
Key insights from the research include:
- Leveraging Language Model Capabilities: By fine-tuning large language models on peer review datasets, their natural language understanding can be harnessed to analyze and critique student work.
- Simulating Peer Feedback: The system's feedback is structured to emulate the helpful, constructive tone of feedback from human classmates, which can be more effective than direct instructor comments.
- Scalable, Personalized Support: The automated Peer-aided Repairer can provide tailored feedback at scale, addressing the challenge of providing high-quality guidance for large numbers of student assignments.
Critical Analysis
The paper makes a compelling case for how large language models can be leveraged to enhance student learning and writing skills. The experiments demonstrate the potential for the Peer-aided Repairer to outperform traditional feedback methods, which is a significant finding.
However, the research also acknowledges some potential limitations and areas for further study. For example, the paper notes that the system's feedback may not always be accurate or address higher-order concerns in student work. There could also be challenges in ensuring the language model's feedback aligns with instructor expectations and learning objectives.
Additionally, the research does not delve deeply into potential biases or ethical considerations that may arise from using language models to assess student work. As these systems become more widely deployed, it will be important to carefully monitor for issues of fairness, inclusivity, and unintended consequences.
Overall, the Peer-aided Repairer represents a promising application of large language models, but further research and refinement will be needed to fully realize its potential and address any potential drawbacks.
Conclusion
This paper presents a novel approach to leveraging large language models to provide automated, personalized feedback on advanced student assignments. By fine-tuning the models on peer review data, the Peer-aided Repairer system can simulate the helpful, constructive tone of human reviewers, offering nuanced guidance that outperforms traditional feedback methods.
The research highlights the potential for language models to enhance student learning and writing skills at scale, addressing the challenge of providing high-quality feedback on complex work. While the system shows promising results, the authors also acknowledge areas for further exploration, such as ensuring the feedback aligns with instructor expectations and addressing potential biases.
As large language models continue to advance, the Peer-aided Repairer represents an exciting application that could transform how we support student development and improve educational outcomes. However, ongoing research and careful consideration of ethical implications will be crucial as these technologies are more widely deployed.
Related Papers
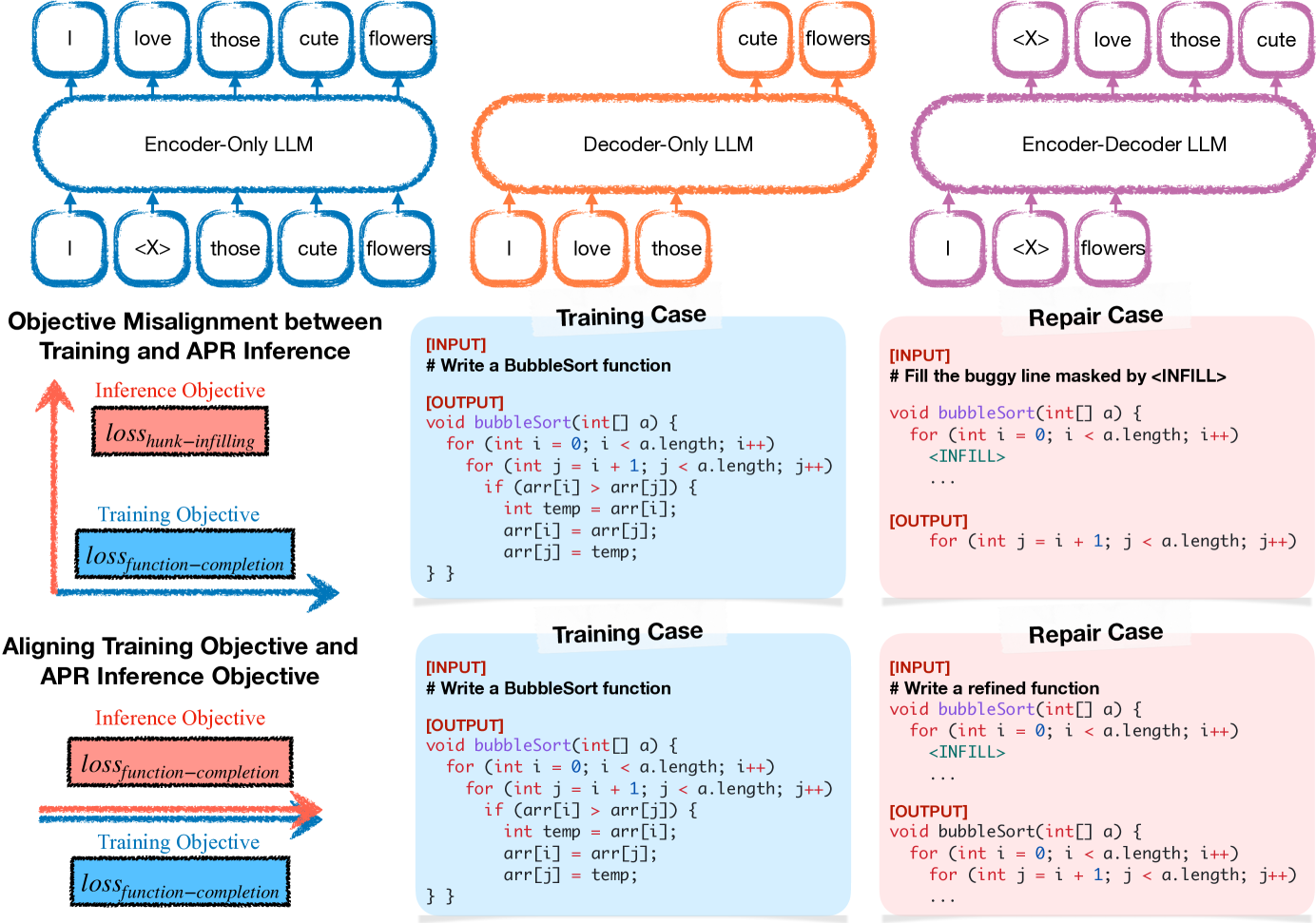
Aligning LLMs for FL-free Program Repair
Junjielong Xu, Ying Fu, Shin Hwei Tan, Pinjia He
0
0
Large language models (LLMs) have achieved decent results on automated program repair (APR). However, the next token prediction training objective of decoder-only LLMs (e.g., GPT-4) is misaligned with the masked span prediction objective of current infilling-style methods, which impedes LLMs from fully leveraging pre-trained knowledge for program repair. In addition, while some LLMs are capable of locating and repairing bugs end-to-end when using the related artifacts (e.g., test cases) as input, existing methods regard them as separate tasks and ask LLMs to generate patches at fixed locations. This restriction hinders LLMs from exploring potential patches beyond the given locations. In this paper, we investigate a new approach to adapt LLMs to program repair. Our core insight is that LLM's APR capability can be greatly improved by simply aligning the output to their training objective and allowing them to refine the whole program without first performing fault localization. Based on this insight, we designed D4C, a straightforward prompting framework for APR. D4C can repair 180 bugs correctly in Defects4J, with each patch being sampled only 10 times. This surpasses the SOTA APR methods with perfect fault localization by 10% and reduces the patch sampling number by 90%. Our findings reveal that (1) objective alignment is crucial for fully exploiting LLM's pre-trained capability, and (2) replacing the traditional localize-then-repair workflow with direct debugging is more effective for LLM-based APR methods. Thus, we believe this paper introduces a new mindset for harnessing LLMs in APR.
4/16/2024
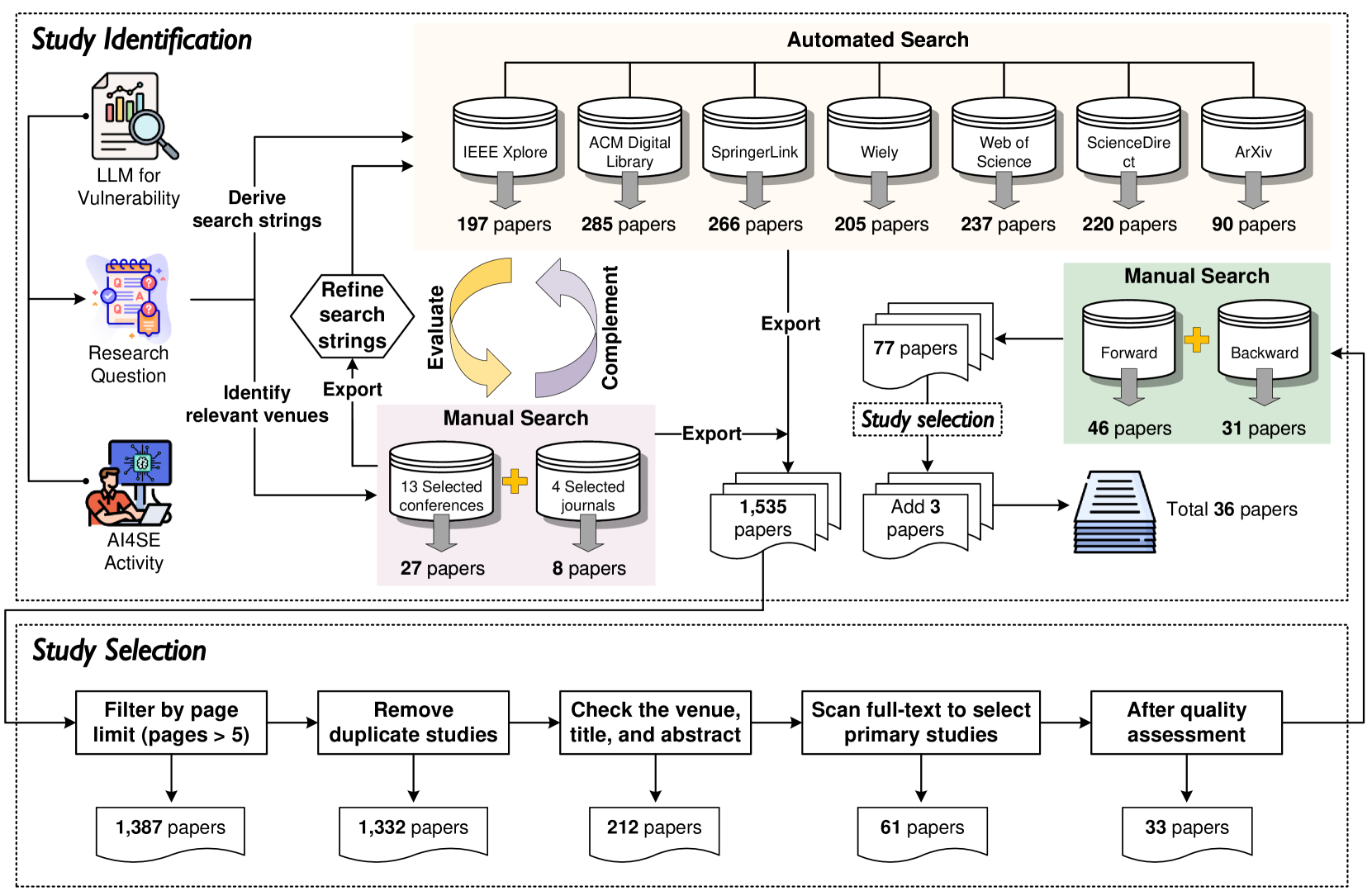
Large Language Model for Vulnerability Detection and Repair: Literature Review and Roadmap
Xin Zhou, Sicong Cao, Xiaobing Sun, David Lo
0
0
The significant advancements in Large Language Models (LLMs) have resulted in their widespread adoption across various tasks within Software Engineering (SE), including vulnerability detection and repair. Numerous recent studies have investigated the application of LLMs to enhance vulnerability detection and repair tasks. Despite the increasing research interest, there is currently no existing survey that focuses on the utilization of LLMs for vulnerability detection and repair. In this paper, we aim to bridge this gap by offering a systematic literature review of approaches aimed at improving vulnerability detection and repair through the utilization of LLMs. The review encompasses research work from leading SE, AI, and Security conferences and journals, covering 36 papers published at 21 distinct venues. By answering three key research questions, we aim to (1) summarize the LLMs employed in the relevant literature, (2) categorize various LLM adaptation techniques in vulnerability detection, and (3) classify various LLM adaptation techniques in vulnerability repair. Based on our findings, we have identified a series of challenges that still need to be tackled considering existing studies. Additionally, we have outlined a roadmap highlighting potential opportunities that we believe are pertinent and crucial for future research endeavors.
4/4/2024

AutoCodeRover: Autonomous Program Improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, Abhik Roychoudhury
0
0
Researchers have made significant progress in automating the software development process in the past decades. Recent progress in Large Language Models (LLMs) has significantly impacted the development process, where developers can use LLM-based programming assistants to achieve automated coding. Nevertheless software engineering involves the process of program improvement apart from coding, specifically to enable software maintenance (e.g. bug fixing) and software evolution (e.g. feature additions). In this paper, we propose an automated approach for solving GitHub issues to autonomously achieve program improvement. In our approach called AutoCodeRover, LLMs are combined with sophisticated code search capabilities, ultimately leading to a program modification or patch. In contrast to recent LLM agent approaches from AI researchers and practitioners, our outlook is more software engineering oriented. We work on a program representation (abstract syntax tree) as opposed to viewing a software project as a mere collection of files. Our code search exploits the program structure in the form of classes/methods to enhance LLM's understanding of the issue's root cause, and effectively retrieve a context via iterative search. The use of spectrum based fault localization using tests, further sharpens the context, as long as a test-suite is available. Experiments on SWE-bench-lite which consists of 300 real-life GitHub issues show increased efficacy in solving GitHub issues (22-23% on SWE-bench-lite). On the full SWE-bench consisting of 2294 GitHub issues, AutoCodeRover solved around 16% of issues, which is higher than the efficacy of the recently reported AI software engineer Devin from Cognition Labs, while taking time comparable to Devin. We posit that our workflow enables autonomous software engineering, where, in future, auto-generated code from LLMs can be autonomously improved.
4/16/2024
🧠
How Effective Are Neural Networks for Fixing Security Vulnerabilities
Yi Wu, Nan Jiang, Hung Viet Pham, Thibaud Lutellier, Jordan Davis, Lin Tan, Petr Babkin, Sameena Shah
0
0
Security vulnerability repair is a difficult task that is in dire need of automation. Two groups of techniques have shown promise: (1) large code language models (LLMs) that have been pre-trained on source code for tasks such as code completion, and (2) automated program repair (APR) techniques that use deep learning (DL) models to automatically fix software bugs. This paper is the first to study and compare Java vulnerability repair capabilities of LLMs and DL-based APR models. The contributions include that we (1) apply and evaluate five LLMs (Codex, CodeGen, CodeT5, PLBART and InCoder), four fine-tuned LLMs, and four DL-based APR techniques on two real-world Java vulnerability benchmarks (Vul4J and VJBench), (2) design code transformations to address the training and test data overlapping threat to Codex, (3) create a new Java vulnerability repair benchmark VJBench, and its transformed version VJBench-trans and (4) evaluate LLMs and APR techniques on the transformed vulnerabilities in VJBench-trans. Our findings include that (1) existing LLMs and APR models fix very few Java vulnerabilities. Codex fixes 10.2 (20.4%), the most number of vulnerabilities. (2) Fine-tuning with general APR data improves LLMs' vulnerability-fixing capabilities. (3) Our new VJBench reveals that LLMs and APR models fail to fix many Common Weakness Enumeration (CWE) types, such as CWE-325 Missing cryptographic step and CWE-444 HTTP request smuggling. (4) Codex still fixes 8.3 transformed vulnerabilities, outperforming all the other LLMs and APR models on transformed vulnerabilities. The results call for innovations to enhance automated Java vulnerability repair such as creating larger vulnerability repair training data, tuning LLMs with such data, and applying code simplification transformation to facilitate vulnerability repair.
4/3/2024