All Roads Lead to Rome? Exploring Representational Similarities Between Latent Spaces of Generative Image Models

0

Sign in to get full access
Overview
- This paper investigates the representational similarities between different generative image models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs).
- The authors aim to understand how these models learn and represent visual concepts, and whether there are common patterns or "roads" that lead to similar representations.
- They propose several techniques to analyze and compare the latent spaces of these models, including Latent Space Translation via Inverse Relative Projection, Latent Functional Maps, and Lost in Latent Space: Disentangled Models Challenge Combinatorial.
Plain English Explanation
Generative image models like VAEs and GANs are powerful tools for creating and manipulating synthetic images. These models learn to represent the visual world in their "latent spaces" - internal representations that capture the essential features of the data. The authors of this paper wanted to understand how these latent spaces compare across different models. Do they all learn similar representations, or do they each find their own unique "roads" to representing the visual world?
To answer this question, the researchers developed several techniques to analyze and compare the latent spaces of various generative models. For example, Latent Space Translation via Inverse Relative Projection allows them to translate the latent representations between models, while Latent Functional Maps and Lost in Latent Space: Disentangled Models Challenge Combinatorial help them understand the geometric structure and disentanglement of the latent spaces.
By applying these techniques, the researchers found that the latent spaces of different generative models do share some common patterns, but also exhibit unique characteristics. This suggests that while there may be "roads" that lead to similar representations, each model also discovers its own unique ways of encoding the visual world.
Technical Explanation
The paper begins by introducing the key concepts of generative image models, such as VAEs and GANs, and their use of latent spaces to represent visual information. The authors then propose several techniques to analyze and compare these latent spaces across different models.
Latent Space Translation via Inverse Relative Projection allows the researchers to translate latent representations between models by learning a mapping function between their latent spaces. Latent Functional Maps are used to compare the geometric structure of the latent spaces, while Lost in Latent Space: Disentangled Models Challenge Combinatorial explores the disentanglement of the learned representations.
The authors then apply these techniques to analyze the latent spaces of several generative models, including VAEs, GANs, and diffusion models. They find that while there are some common patterns in the latent representations, each model also exhibits unique characteristics, suggesting that there are multiple "roads" to representing the visual world.
Critical Analysis
The paper presents a thorough and well-designed investigation of the representational similarities between generative image models. The proposed techniques, such as Latent Space Translation via Inverse Relative Projection and Latent Functional Maps, provide valuable insights into the structure and disentanglement of the latent spaces.
However, the paper does not explore the potential implications of these findings in depth. It would be interesting to see how the authors' insights could inform the design and development of future generative models, or how the observed representational similarities and differences could impact downstream tasks and applications.
Additionally, the paper focuses primarily on visual data and models, and it's unclear whether the same patterns would hold true for other types of generative models, such as those for text or audio. Extending the analysis to a broader range of generative tasks could further strengthen the generalizability of the findings.
Conclusion
This paper offers a comprehensive investigation into the representational similarities between different generative image models, providing valuable insights into how these models learn to encode visual information. By developing and applying novel techniques to analyze the latent spaces of VAEs, GANs, and diffusion models, the authors demonstrate that while there are common "roads" to representing the visual world, each model also discovers unique ways of encoding visual concepts.
These findings have important implications for the design and understanding of generative models, as well as their potential applications in fields such as computer vision, image synthesis, and beyond. The techniques and insights presented in this paper can serve as a foundation for further research into the nature of representation learning in generative models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
All Roads Lead to Rome? Exploring Representational Similarities Between Latent Spaces of Generative Image Models
Charumathi Badrinath, Usha Bhalla, Alex Oesterling, Suraj Srinivas, Himabindu Lakkaraju
Do different generative image models secretly learn similar underlying representations? We investigate this by measuring the latent space similarity of four different models: VAEs, GANs, Normalizing Flows (NFs), and Diffusion Models (DMs). Our methodology involves training linear maps between frozen latent spaces to stitch arbitrary pairs of encoders and decoders and measuring output-based and probe-based metrics on the resulting stitched'' models. Our main findings are that linear maps between latent spaces of performant models preserve most visual information even when latent sizes differ; for CelebA models, gender is the most similarly represented probe-able attribute. Finally we show on an NF that latent space representations converge early in training.
Read more7/19/2024
0
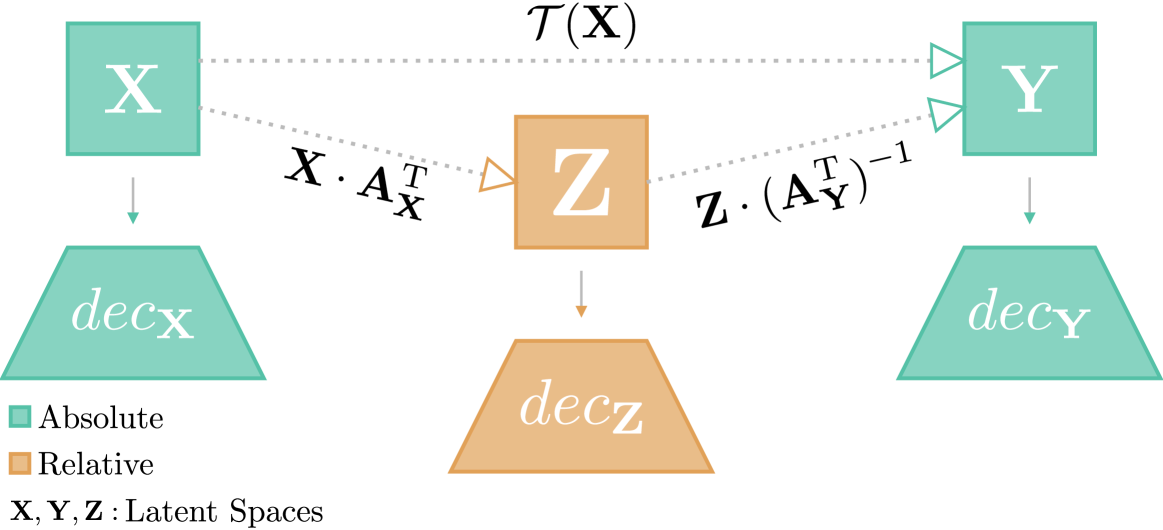
Latent Space Translation via Inverse Relative Projection
Valentino Maiorca, Luca Moschella, Marco Fumero, Francesco Locatello, Emanuele Rodol`a
The emergence of similar representations between independently trained neural models has sparked significant interest in the representation learning community, leading to the development of various methods to obtain communication between latent spaces. Latent space communication can be achieved in two ways: i) by independently mapping the original spaces to a shared or relative one; ii) by directly estimating a transformation from a source latent space to a target one. In this work, we combine the two into a novel method to obtain latent space translation through the relative space. By formalizing the invertibility of angle-preserving relative representations and assuming the scale invariance of decoder modules in neural models, we can effectively use the relative space as an intermediary, independently projecting onto and from other semantically similar spaces. Extensive experiments over various architectures and datasets validate our scale invariance assumption and demonstrate the high accuracy of our method in latent space translation. We also apply our method to zero-shot stitching between arbitrary pre-trained text and image encoders and their classifiers, even across modalities. Our method has significant potential for facilitating the reuse of models in a practical manner via compositionality.
Read more6/24/2024
🤯
0
Latent. Functional Map
Marco Fumero, Marco Pegoraro, Valentino Maiorca, Francesco Locatello, Emanuele Rodol`a
Neural models learn data representations that lie on low-dimensional manifolds, yet modeling the relation between these representational spaces is an ongoing challenge. By integrating spectral geometry principles into neural modeling, we show that this problem can be better addressed in the functional domain, mitigating complexity, while enhancing interpretability and performances on downstream tasks. To this end, we introduce a multi-purpose framework to the representation learning community, which allows to: (i) compare different spaces in an interpretable way and measure their intrinsic similarity; (ii) find correspondences between them, both in unsupervised and weakly supervised settings, and (iii) to effectively transfer representations between distinct spaces. We validate our framework on various applications, ranging from stitching to retrieval tasks, demonstrating that latent functional maps can serve as a swiss-army knife for representation alignment.
Read more6/24/2024
👨🏫
0
Lost in Latent Space: Disentangled Models and the Challenge of Combinatorial Generalisation
Milton L. Montero, Jeffrey S. Bowers, Rui Ponte Costa, Casimir J. H. Ludwig, Gaurav Malhotra
Recent research has shown that generative models with highly disentangled representations fail to generalise to unseen combination of generative factor values. These findings contradict earlier research which showed improved performance in out-of-training distribution settings when compared to entangled representations. Additionally, it is not clear if the reported failures are due to (a) encoders failing to map novel combinations to the proper regions of the latent space or (b) novel combinations being mapped correctly but the decoder/downstream process is unable to render the correct output for the unseen combinations. We investigate these alternatives by testing several models on a range of datasets and training settings. We find that (i) when models fail, their encoders also fail to map unseen combinations to correct regions of the latent space and (ii) when models succeed, it is either because the test conditions do not exclude enough examples, or because excluded generative factors determine independent parts of the output image. Based on these results, we argue that to generalise properly, models not only need to capture factors of variation, but also understand how to invert the generative process that was used to generate the data.
Read more6/17/2024