Latent Space Translation via Inverse Relative Projection
2406.15057
0
0
Abstract
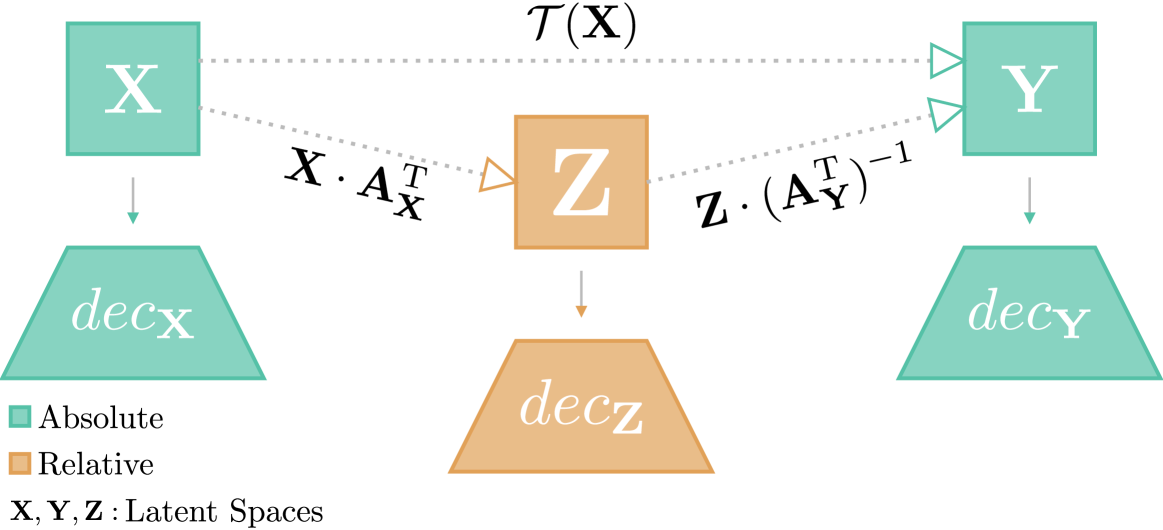
The emergence of similar representations between independently trained neural models has sparked significant interest in the representation learning community, leading to the development of various methods to obtain communication between latent spaces. Latent space communication can be achieved in two ways: i) by independently mapping the original spaces to a shared or relative one; ii) by directly estimating a transformation from a source latent space to a target one. In this work, we combine the two into a novel method to obtain latent space translation through the relative space. By formalizing the invertibility of angle-preserving relative representations and assuming the scale invariance of decoder modules in neural models, we can effectively use the relative space as an intermediary, independently projecting onto and from other semantically similar spaces. Extensive experiments over various architectures and datasets validate our scale invariance assumption and demonstrate the high accuracy of our method in latent space translation. We also apply our method to zero-shot stitching between arbitrary pre-trained text and image encoders and their classifiers, even across modalities. Our method has significant potential for facilitating the reuse of models in a practical manner via compositionality.
Create account to get full access
Overview
- This paper presents a novel method called Latent Space Translation via Inverse Relative Projection (LSTIRP) for translating between different latent spaces of artificial neural networks.
- The key idea is to learn a mapping between latent spaces that can be used to translate between them, enabling cross-modal and cross-task capabilities.
- The authors demonstrate the effectiveness of LSTIRP on various tasks, including image-to-image translation, text-to-image generation, and few-shot learning.
Plain English Explanation
Artificial neural networks are powerful machine learning models that can learn complex tasks, like recognizing objects in images or generating realistic-looking images from text descriptions. These models work by encoding the input data into a compressed "latent" representation, which the network can then use to perform the desired task.
In this paper, the researchers propose a new method called "Latent Space Translation via Inverse Relative Projection" (LSTIRP) that allows these latent representations to be shared and transferred between different neural network models. This means that a model trained to generate images from text descriptions could potentially be used to generate images from other types of inputs, like a user's voice or a hand-drawn sketch.
The key insight behind LSTIRP is that the latent representations of different neural networks, even if they were trained on completely different tasks, often have some underlying similarities. By learning a mapping between these latent spaces, the researchers show that it's possible to translate between them and unlock new capabilities.
For example, a model trained on image classification could be used to generate images from text descriptions, or a language model could be used to generate images from a user's voice. This cross-modal and cross-task capability could be very useful in real-world applications, where flexibility and adaptability are highly valued.
Technical Explanation
The core of the LSTIRP method is a mechanism for learning a mapping between the latent spaces of different neural network models. This mapping is learned using a technique called "inverse relative projection," which aims to find a linear transformation that can translate between the latent spaces while preserving the underlying relationships between data points.
Specifically, the authors first train two separate neural networks, each on a different task (e.g., image classification and text-to-image generation). They then extract the latent representations from each model and use a linear layer to learn the mapping between them. This mapping is trained to minimize the distance between corresponding latent vectors from the two models, while also preserving the relative distances between data points.
The authors demonstrate the effectiveness of LSTIRP on a variety of tasks, including image-to-image translation, text-to-image generation, and few-shot learning. In each case, they show that the learned mapping can be used to transfer the capabilities of one model to another, enabling new and more flexible applications.
Critical Analysis
The LSTIRP method presented in this paper is a promising approach for enabling cross-modal and cross-task capabilities in artificial neural networks. By learning a mapping between latent spaces, the researchers have shown that it's possible to unlock new capabilities and applications that were not possible with the individual models alone.
However, the paper does mention some limitations and areas for further research. For example, the linear mapping learned by LSTIRP may not be able to capture more complex, non-linear relationships between the latent spaces. Additionally, the method relies on having access to the latent representations of the individual models, which may not always be feasible in real-world scenarios.
Furthermore, the authors do not extensively explore the potential biases or reliability issues that could arise when translating between latent spaces. It would be important to carefully analyze the outputs of these translated models to ensure they are accurate, unbiased, and behave as expected.
Overall, the LSTIRP method represents an interesting and valuable contribution to the field of artificial intelligence, but there is still room for further research and development to address the potential limitations and ensure the safe and responsible deployment of these techniques in real-world applications.
Conclusion
The Latent Space Translation via Inverse Relative Projection (LSTIRP) method presented in this paper offers a novel approach for enabling cross-modal and cross-task capabilities in artificial neural networks. By learning a mapping between the latent spaces of different models, the researchers have demonstrated the ability to transfer capabilities between tasks, unlocking new and more flexible applications.
The key innovation of LSTIRP is its ability to leverage the underlying similarities in the latent representations of neural networks, even when they were trained on completely different tasks. This allows for the sharing and reuse of learned knowledge, which could be highly valuable in real-world scenarios where adaptability and flexibility are important.
While the paper highlights some limitations and areas for further research, the LSTIRP method represents an exciting advance in the field of artificial intelligence. As the researchers continue to refine and expand upon this work, it will be interesting to see how these techniques are applied to solve increasingly complex problems and enable new and transformative applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Latent Communication in Artificial Neural Networks
Luca Moschella
0
0
As NNs permeate various scientific and industrial domains, understanding the universality and reusability of their representations becomes crucial. At their core, these networks create intermediate neural representations, indicated as latent spaces, of the input data and subsequently leverage them to perform specific downstream tasks. This dissertation focuses on the universality and reusability of neural representations. Do the latent representations crafted by a NN remain exclusive to a particular trained instance, or can they generalize across models, adapting to factors such as randomness during training, model architecture, or even data domain? This adaptive quality introduces the notion of Latent Communication -- a phenomenon that describes when representations can be unified or reused across neural spaces. A salient observation from our research is the emergence of similarities in latent representations, even when these originate from distinct or seemingly unrelated NNs. By exploiting a partial correspondence between the two data distributions that establishes a semantic link, we found that these representations can either be projected into a universal representation, coined as Relative Representation, or be directly translated from one space to another. Latent Communication allows for a bridge between independently trained NN, irrespective of their training regimen, architecture, or the data modality they were trained on -- as long as the data semantic content stays the same (e.g., images and their captions). This holds true for both generation, classification and retrieval downstream tasks; in supervised, weakly supervised, and unsupervised settings; and spans various data modalities including images, text, audio, and graphs -- showcasing the universality of the Latent Communication phenomenon. [...]
6/18/2024
🤯
Latent. Functional Map
Marco Fumero, Marco Pegoraro, Valentino Maiorca, Francesco Locatello, Emanuele Rodol`a
0
0
Neural models learn data representations that lie on low-dimensional manifolds, yet modeling the relation between these representational spaces is an ongoing challenge. By integrating spectral geometry principles into neural modeling, we show that this problem can be better addressed in the functional domain, mitigating complexity, while enhancing interpretability and performances on downstream tasks. To this end, we introduce a multi-purpose framework to the representation learning community, which allows to: (i) compare different spaces in an interpretable way and measure their intrinsic similarity; (ii) find correspondences between them, both in unsupervised and weakly supervised settings, and (iii) to effectively transfer representations between distinct spaces. We validate our framework on various applications, ranging from stitching to retrieval tasks, demonstrating that latent functional maps can serve as a swiss-army knife for representation alignment.
6/24/2024

New!Dynamic Relative Representations for Goal-Oriented Semantic Communications
Simone Fiorellino, Claudio Battiloro, Emilio Calvanese Strinati, Paolo Di Lorenzo
0
0
In future 6G wireless networks, semantic and effectiveness aspects of communications will play a fundamental role, incorporating meaning and relevance into transmissions. However, obstacles arise when devices employ diverse languages, logic, or internal representations, leading to semantic mismatches that might jeopardize understanding. In latent space communication, this challenge manifests as misalignment within high-dimensional representations where deep neural networks encode data. This paper presents a novel framework for goal-oriented semantic communication, leveraging relative representations to mitigate semantic mismatches via latent space alignment. We propose a dynamic optimization strategy that adapts relative representations, communication parameters, and computation resources for energy-efficient, low-latency, goal-oriented semantic communications. Numerical results demonstrate our methodology's effectiveness in mitigating mismatches among devices, while optimizing energy consumption, delay, and effectiveness.
7/2/2024

Exploring the Impact of a Transformer's Latent Space Geometry on Downstream Task Performance
Anna C. Marbut, John W. Chandler, Travis J. Wheeler
0
0
It is generally thought that transformer-based large language models benefit from pre-training by learning generic linguistic knowledge that can be focused on a specific task during fine-tuning. However, we propose that much of the benefit from pre-training may be captured by geometric characteristics of the latent space representations, divorced from any specific linguistic knowledge. In this work we explore the relationship between GLUE benchmarking task performance and a variety of measures applied to the latent space resulting from BERT-type contextual language models. We find that there is a strong linear relationship between a measure of quantized cell density and average GLUE performance and that these measures may be predictive of otherwise surprising GLUE performance for several non-standard BERT-type models from the literature. These results may be suggestive of a strategy for decreasing pre-training requirements, wherein model initialization can be informed by the geometric characteristics of the model's latent space.
6/19/2024