ALLaM: Large Language Models for Arabic and English

0
Sign in to get full access
Overview
- This paper introduces ALLaM, a set of large language models for both Arabic and English.
- The models are trained on a large corpus of web data in both languages.
- The goal is to create high-performing language models that can be used for a variety of natural language processing tasks in Arabic and English.
Plain English Explanation
Large language models like GPT-3 have shown impressive capabilities in natural language processing for English. However, developing similar high-performing models for other languages like Arabic has been more challenging.
The researchers behind this paper have created ALLaM, a set of large language models trained on massive datasets in both Arabic and English. The goal is to make powerful language understanding and generation tools available for a wider range of applications and users.
These models can be used for tasks like automatic story generation, localizing language models for Arabic, and other natural language processing needs in the Arabic-speaking world. By making these high-quality models publicly available, the researchers hope to accelerate progress in Arabic NLP and enable new applications.
Technical Explanation
The researchers trained the ALLaM models using a large corpus of web data in both Arabic and English. This included web pages, books, and other text sources crawled from the internet. The total dataset size was over 100 billion Arabic words.
The models were trained using standard large language model techniques like masked language modeling and autoregressive generation. The researchers experimented with different model sizes, architectures, and training strategies to optimize the performance of the Arabic and English models.
The final ALLaM models demonstrated strong performance on a variety of benchmarks for language understanding and generation in both languages. The researchers also showed that the models could be successfully fine-tuned for specific tasks and domains, leveraging the broad knowledge captured during pretraining.
Critical Analysis
The researchers acknowledge several limitations and areas for future work. For example, they note that the models may still struggle with some dialectal variations of Arabic and could benefit from further adaptation. The dataset also likely has biases that could lead to unfairness or undesirable outputs in certain applications.
Additionally, the authors do not provide in-depth analysis of the models' performance on real-world tasks or their robustness to adversarial attacks. More thorough evaluation is needed to fully understand the strengths and weaknesses of these language models.
Overall, the ALLaM models represent an important step forward in Arabic NLP, but continued research and responsible deployment will be crucial to realizing their full potential.
Conclusion
This paper introduces the ALLaM set of large language models for both Arabic and English. By pretraining on massive multilingual datasets, the researchers have created powerful tools for natural language processing that can be applied to a wide range of applications, from story generation to model localization.
While further research is needed, the ALLaM models demonstrate the potential for large language models to drive progress in under-resourced languages like Arabic. By making these models publicly available, the researchers hope to accelerate innovation and enable new use cases in the Arabic-speaking world and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ALLaM: Large Language Models for Arabic and English
M Saiful Bari, Yazeed Alnumay, Norah A. Alzahrani, Nouf M. Alotaibi, Hisham A. Alyahya, Sultan AlRashed, Faisal A. Mirza, Shaykhah Z. Alsubaie, Hassan A. Alahmed, Ghadah Alabduljabbar, Raghad Alkhathran, Yousef Almushayqih, Raneem Alnajim, Salman Alsubaihi, Maryam Al Mansour, Majed Alrubaian, Ali Alammari, Zaki Alawami, Abdulmohsen Al-Thubaity, Ahmed Abdelali, Jeril Kuriakose, Abdalghani Abujabal, Nora Al-Twairesh, Areeb Alowisheq, Haidar Khan
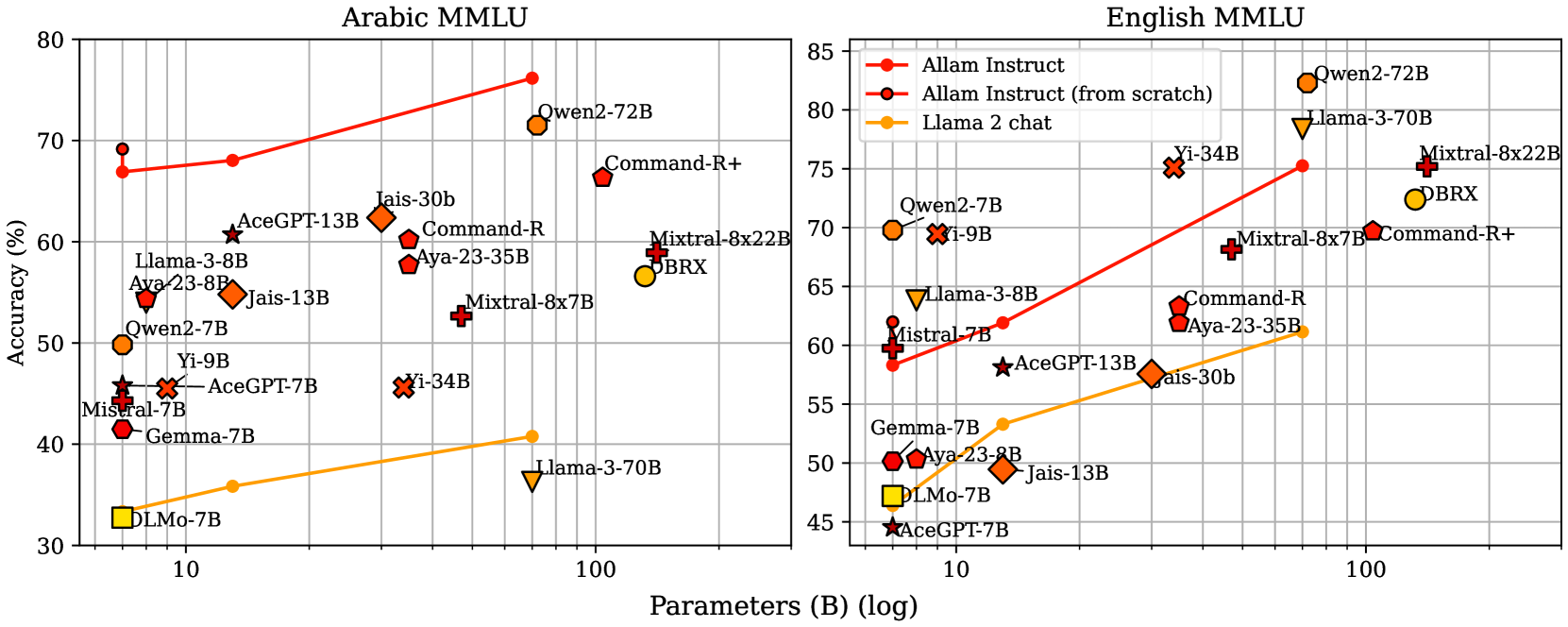
We present ALLaM: Arabic Large Language Model, a series of large language models to support the ecosystem of Arabic Language Technologies (ALT). ALLaM is carefully trained considering the values of language alignment and knowledge transfer at scale. Our autoregressive decoder-only architecture models demonstrate how second-language acquisition via vocabulary expansion and pretraining on a mixture of Arabic and English text can steer a model towards a new language (Arabic) without any catastrophic forgetting in the original language (English). Furthermore, we highlight the effectiveness of using parallel/translated data to aid the process of knowledge alignment between languages. Finally, we show that extensive alignment with human preferences can significantly enhance the performance of a language model compared to models of a larger scale with lower quality alignment. ALLaM achieves state-of-the-art performance in various Arabic benchmarks, including MMLU Arabic, ACVA, and Arabic Exams. Our aligned models improve both in Arabic and English from their base aligned models.
Read more7/23/2024
💬
0
AlcLaM: Arabic Dialectal Language Model
Murtadha Ahmed, Saghir Alfasly, Bo Wen, Jamaal Qasem, Mohammed Ahmed, Yunfeng Liu
Pre-trained Language Models (PLMs) are integral to many modern natural language processing (NLP) systems. Although multilingual models cover a wide range of languages, they often grapple with challenges like high inference costs and a lack of diverse non-English training data. Arabic-specific PLMs are trained predominantly on modern standard Arabic, which compromises their performance on regional dialects. To tackle this, we construct an Arabic dialectal corpus comprising 3.4M sentences gathered from social media platforms. We utilize this corpus to expand the vocabulary and retrain a BERT-based model from scratch. Named AlcLaM, our model was trained using only 13 GB of text, which represents a fraction of the data used by existing models such as CAMeL, MARBERT, and ArBERT, compared to 7.8%, 10.2%, and 21.3%, respectively. Remarkably, AlcLaM demonstrates superior performance on a variety of Arabic NLP tasks despite the limited training data. AlcLaM is available at GitHub https://github.com/amurtadha/Alclam and HuggingFace https://huggingface.co/rahbi.
Read more7/19/2024

0
Dallah: A Dialect-Aware Multimodal Large Language Model for Arabic
Fakhraddin Alwajih, Gagan Bhatia, Muhammad Abdul-Mageed
Recent advancements have significantly enhanced the capabilities of Multimodal Large Language Models (MLLMs) in generating and understanding image-to-text content. Despite these successes, progress is predominantly limited to English due to the scarcity of high quality multimodal resources in other languages. This limitation impedes the development of competitive models in languages such as Arabic. To alleviate this situation, we introduce an efficient Arabic multimodal assistant, dubbed Dallah, that utilizes an advanced language model based on LLaMA-2 to facilitate multimodal interactions. Dallah demonstrates state-of-the-art performance in Arabic MLLMs. Through fine-tuning six Arabic dialects, Dallah showcases its capability to handle complex dialectal interactions incorporating both textual and visual elements. The model excels in two benchmark tests: one evaluating its performance on Modern Standard Arabic (MSA) and another specifically designed to assess dialectal responses. Beyond its robust performance in multimodal interaction tasks, Dallah has the potential to pave the way for further development of dialect-aware Arabic MLLMs.
Read more7/29/2024
0
AceGPT, Localizing Large Language Models in Arabic
Huang Huang, Fei Yu, Jianqing Zhu, Xuening Sun, Hao Cheng, Dingjie Song, Zhihong Chen, Abdulmohsen Alharthi, Bang An, Juncai He, Ziche Liu, Zhiyi Zhang, Junying Chen, Jianquan Li, Benyou Wang, Lian Zhang, Ruoyu Sun, Xiang Wan, Haizhou Li, Jinchao Xu
This paper is devoted to the development of a localized Large Language Model (LLM) specifically for Arabic, a language imbued with unique cultural characteristics inadequately addressed by current mainstream models. Significant concerns emerge when addressing cultural sensitivity and local values. To address this, the paper proposes a comprehensive solution that includes further pre-training with Arabic texts, Supervised Fine-Tuning (SFT) utilizing native Arabic instructions, and GPT-4 responses in Arabic, alongside Reinforcement Learning with AI Feedback (RLAIF) employing a reward model attuned to local culture and values. The goal is to cultivate culturally cognizant and value-aligned Arabic LLMs capable of accommodating the diverse, application-specific needs of Arabic-speaking communities. Comprehensive evaluations reveal that the resulting model, dubbed `AceGPT', sets the state-of-the-art standard for open Arabic LLMs across various benchmarks. Codes, data, and models are in https://github.com/FreedomIntelligence/AceGPT.
Read more4/3/2024