Alleviating Hallucinations in Large Language Models with Scepticism Modeling

0

Sign in to get full access
Overview
- The paper focuses on alleviating hallucinations in large language models (LLMs) using scepticism modeling.
- Hallucinations refer to the generation of plausible-sounding but factually incorrect outputs by LLMs.
- The proposed approach aims to improve the reliability and trustworthiness of LLMs by making them more skeptical of their own outputs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. However, these models can sometimes produce factually incorrect or nonsensical outputs, a phenomenon known as "hallucinations." <a href="https://aimodels.fyi/papers/arxiv/detecting-hallucinations-large-language-model-generation-token">Detecting hallucinations</a> in LLM outputs is an important challenge, as it can undermine the reliability and trustworthiness of these models.
The paper introduces a novel approach called "scepticism modeling" to help alleviate hallucinations in LLMs. The key idea is to make the LLM more skeptical of its own outputs, so that it is less likely to generate hallucinatory content. This is achieved by training the model to assess the plausibility and truthfulness of its own generated text, and to be more cautious about making claims that it is not highly confident about.
The scepticism modeling approach involves training the LLM to predict a "scepticism score" for its own outputs, which reflects the model's level of confidence in the generated text. By incorporating this scepticism score into the model's decision-making process, the LLM becomes more hesitant to make definitive statements and is less likely to "hallucinate" factually incorrect information.
This approach has the potential to improve the reliability and trustworthiness of LLMs, making them more suitable for real-world applications where accurate and trustworthy information is essential. <a href="https://aimodels.fyi/papers/arxiv/can-hallucinating-model-help-reducing-human-hallucination">Reducing human hallucination</a> is another potential benefit of this work, as it can help users better evaluate the reliability of LLM outputs.
Technical Explanation
The paper proposes a novel approach called "scepticism modeling" to alleviate hallucinations in large language models (LLMs). The key idea is to train the LLM to assess the plausibility and truthfulness of its own generated text, and to be more cautious about making claims that it is not highly confident about.
The scepticism modeling approach involves adding an additional output layer to the LLM that predicts a "scepticism score" for each token in the generated text. This scepticism score reflects the model's level of confidence in the truthfulness and plausibility of the generated content. The scepticism score is then incorporated into the model's decision-making process, making the LLM more hesitant to generate definitive statements and less likely to produce hallucinatory outputs.
The authors conduct experiments on two popular LLM architectures, GPT-2 and GPT-3, and find that the scepticism modeling approach significantly reduces the frequency of hallucinations in the generated text. Compared to the baseline LLMs, the scepticism-enhanced models show improved accuracy and reliability in tasks that require factual reasoning and knowledge-intensive generation.
The paper also discusses potential applications and limitations of the scepticism modeling approach. <a href="https://aimodels.fyi/papers/arxiv/large-language-models-hallucination-regard-to-known">Hallucinations in LLMs with respect to known facts</a> are an area of concern, and the authors suggest that scepticism modeling could be particularly useful in domains where factual accuracy is critical, such as scientific writing or medical diagnosis.
Critical Analysis
The scepticism modeling approach proposed in the paper is a promising step towards improving the reliability and trustworthiness of large language models. By making the models more skeptical of their own outputs, the approach can help reduce the frequency of hallucinations, which is a significant challenge for these powerful AI systems.
One potential limitation of the approach is that it relies on the LLM's ability to accurately assess the plausibility and truthfulness of its own generated text. If the model's self-assessment capabilities are imperfect, the scepticism score may not always accurately reflect the reliability of the generated output. <a href="https://aimodels.fyi/papers/arxiv/dont-believe-everything-you-read-enhancing-summarization">Enhancing summarization with scepticism</a> is an area that could be explored further to address this issue.
Additionally, the paper focuses on reducing hallucinations in the generated text, but it does not address the potential for LLMs to introduce other types of biases or errors in their outputs. Developing more comprehensive approaches to ensure the trustworthiness and reliability of these models, beyond just hallucination reduction, is an important area for future research.
Overall, the scepticism modeling approach presented in the paper is a valuable contribution to the ongoing efforts to improve the reliability and trustworthiness of large language models. Further research and development in this area could lead to more robust and reliable AI systems that can be safely deployed in a wide range of real-world applications.
Conclusion
The paper introduces a novel approach called "scepticism modeling" to alleviate hallucinations in large language models (LLMs). By training the LLMs to assess the plausibility and truthfulness of their own generated text and incorporate a "scepticism score" into their decision-making, the approach can make the models more hesitant to produce definitive statements and less likely to generate hallucinatory outputs.
The experimental results demonstrate the effectiveness of the scepticism modeling approach in reducing hallucinations and improving the accuracy and reliability of LLMs. This work has important implications for the development of trustworthy and reliable AI systems, particularly in domains where factual accuracy is critical.
While the scepticism modeling approach is a promising step forward, there are still challenges and limitations that need to be addressed through further research. Developing more comprehensive approaches to ensuring the overall trustworthiness of LLMs, beyond just hallucination reduction, is an important area for future work in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Alleviating Hallucinations in Large Language Models with Scepticism Modeling
Yetao Wu, Yihong Wang, Teng Chen, Chenxi Liu, Ningyuan Xi, Qingqing Gu, Hongyang Lei, Zhonglin Jiang, Yong Chen, Luo Ji
Hallucinations is a major challenge for large language models (LLMs), prevents adoption in diverse fields. Uncertainty estimation could be used for alleviating the damages of hallucinations. The skeptical emotion of human could be useful for enhancing the ability of self estimation. Inspirited by this observation, we proposed a new approach called Skepticism Modeling (SM). This approach is formalized by combining the information of token and logits for self estimation. We construct the doubt emotion aware data, perform continual pre-training, and then fine-tune the LLMs, improve their ability of self estimation. Experimental results demonstrate this new approach effectively enhances a model's ability to estimate their uncertainty, and validate its generalization ability of other tasks by out-of-domain experiments.
Read more9/11/2024

0
Detecting Hallucinations in Large Language Model Generation: A Token Probability Approach
Ernesto Quevedo, Jorge Yero, Rachel Koerner, Pablo Rivas, Tomas Cerny
Concerns regarding the propensity of Large Language Models (LLMs) to produce inaccurate outputs, also known as hallucinations, have escalated. Detecting them is vital for ensuring the reliability of applications relying on LLM-generated content. Current methods often demand substantial resources and rely on extensive LLMs or employ supervised learning with multidimensional features or intricate linguistic and semantic analyses difficult to reproduce and largely depend on using the same LLM that hallucinated. This paper introduces a supervised learning approach employing two simple classifiers utilizing only four numerical features derived from tokens and vocabulary probabilities obtained from other LLM evaluators, which are not necessarily the same. The method yields promising results, surpassing state-of-the-art outcomes in multiple tasks across three different benchmarks. Additionally, we provide a comprehensive examination of the strengths and weaknesses of our approach, highlighting the significance of the features utilized and the LLM employed as an evaluator. We have released our code publicly at https://github.com/Baylor-AI/HalluDetect.
Read more5/31/2024
📈
0
Can a Hallucinating Model help in Reducing Human Hallucination?
Sowmya S Sundaram, Balaji Alwar
The prevalence of unwarranted beliefs, spanning pseudoscience, logical fallacies, and conspiracy theories, presents substantial societal hurdles and the risk of disseminating misinformation. Utilizing established psychometric assessments, this study explores the capabilities of large language models (LLMs) vis-a-vis the average human in detecting prevalent logical pitfalls. We undertake a philosophical inquiry, juxtaposing the rationality of humans against that of LLMs. Furthermore, we propose methodologies for harnessing LLMs to counter misconceptions, drawing upon psychological models of persuasion such as cognitive dissonance theory and elaboration likelihood theory. Through this endeavor, we highlight the potential of LLMs as personalized misinformation debunking agents.
Read more5/3/2024
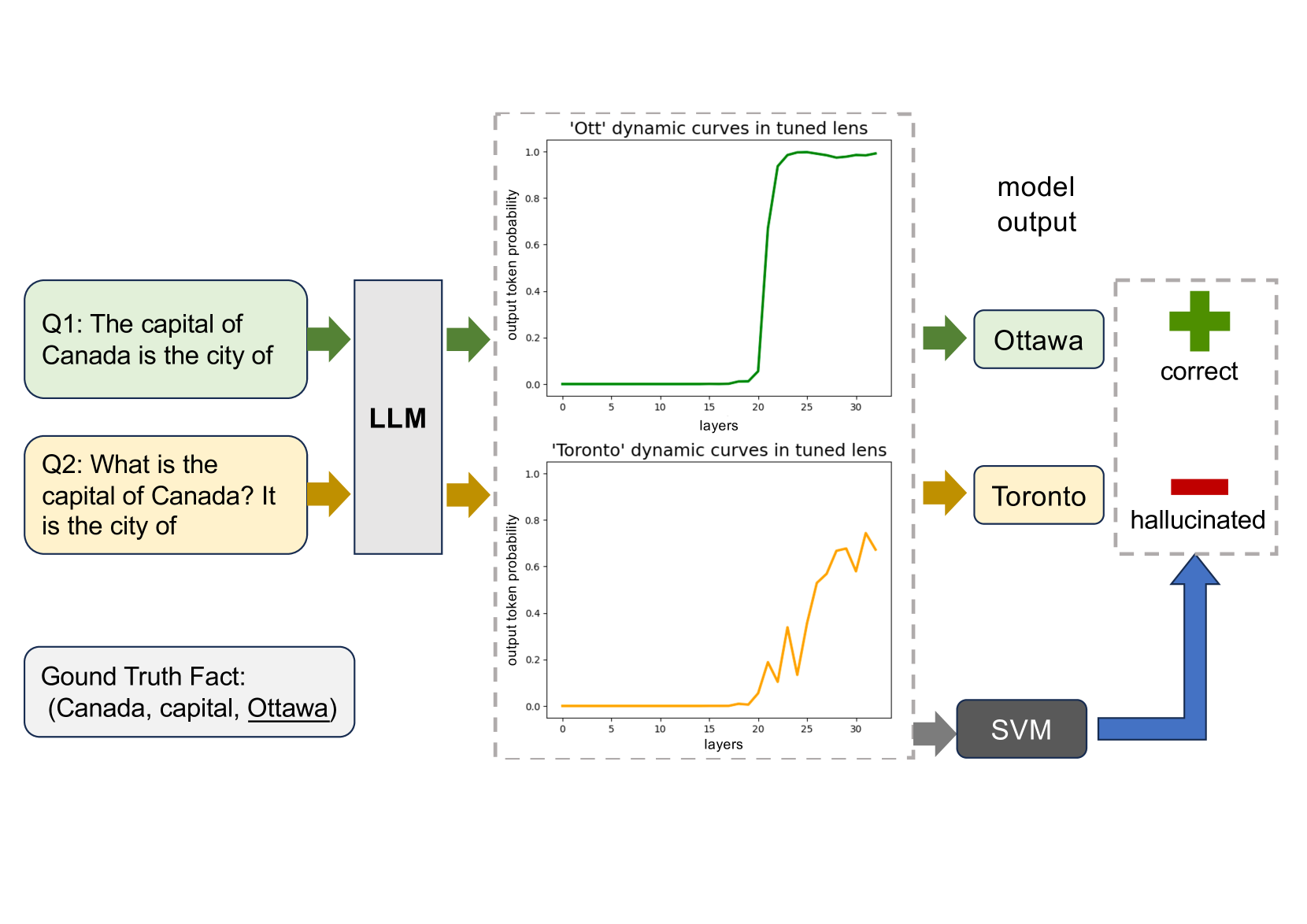
0
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
Read more4/1/2024