Ambiguous Annotations: When is a Pedestrian not a Pedestrian?

0
📊
Sign in to get full access
Overview
- Datasets labeled by human annotators are widely used to train and test machine learning models.
- Researchers are increasingly concerned about the quality of these labels, as it's not always clear if a label is correct or not.
- This paper investigates the ambiguity in annotating autonomous driving datasets, an important aspect of data quality.
- The experiments show that excluding highly ambiguous data from training improves the performance of a state-of-the-art pedestrian detector.
- Understanding the properties of the dataset and the target class is crucial to safely remove ambiguous instances while maintaining the representativeness of the training data.
Plain English Explanation
Machine learning models are often trained and tested using datasets that have been labeled by human annotators. In recent years, researchers have become more interested in the quality of these labels, as it's not always easy to determine whether a label is correct or not.
This paper looks at the ambiguity in the annotation of datasets used for autonomous driving research, which is an important factor in the overall quality of the data. The experiments show that removing the most ambiguous data from the training process can actually improve the performance of a state-of-the-art pedestrian detection model, saving time and annotation costs.
However, the researchers also found that in order to safely remove ambiguous instances while still keeping the training data representative of the real world, it's crucial to have a good understanding of the properties of the dataset and the specific class being detected, like pedestrians in this case.
Technical Explanation
The paper investigates the impact of ambiguous annotations in autonomous driving datasets on the performance of a state-of-the-art pedestrian detection model. The authors propose a method to identify and remove highly ambiguous data instances from the training set, and evaluate the impact on model performance in terms of LAMR, precision, and F1 score.
The experiments were conducted on the nuScenes and Waymo datasets, using a pedestrian attribute recognition model as the base detector. The authors first defined a set of ambiguity measures to identify highly ambiguous instances, such as low-confidence annotations or disagreements between multiple annotators.
By excluding these ambiguous instances from the training set, the authors demonstrated significant improvements in the performance of the pedestrian detector, while also reducing training time and annotation costs. The results highlight the importance of understanding the properties of the dataset and the target class in order to safely remove ambiguous data without compromising the representativeness of the training data.
Critical Analysis
The paper provides a valuable contribution to the growing body of research on label quality in machine learning datasets. By focusing on the specific challenge of ambiguous annotations in autonomous driving datasets, the authors have identified an important dimension of data quality that deserves more attention.
One potential limitation of the work is that the experiments were conducted on a relatively small set of datasets, nuScenes and Waymo. It would be interesting to see if the findings hold true for a broader range of autonomous driving datasets, or even in other domains beyond self-driving cars.
Additionally, the paper does not provide much insight into the specific causes of the ambiguity in the annotations, or the factors that contribute to it. A deeper analysis of the annotation process and the characteristics of the data that lead to ambiguity could help inform better annotation strategies and dataset design.
Overall, this research highlights the importance of carefully considering label quality when working with machine learning datasets, and provides a promising approach for improving model performance by selectively excluding ambiguous data instances.
Conclusion
This paper investigates the impact of ambiguous annotations in autonomous driving datasets on the performance of a state-of-the-art pedestrian detection model. The experiments show that excluding highly ambiguous data from the training process can lead to significant improvements in model performance, while also reducing training time and annotation costs.
The key takeaway is that understanding the properties of the dataset and the target class being detected is crucial for safely removing ambiguous instances without compromising the representativeness of the training data. This research contributes to the growing body of work on label quality in machine learning, and provides valuable insights for researchers and practitioners working with complex, real-world datasets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Ambiguous Annotations: When is a Pedestrian not a Pedestrian?
Luisa Schwirten, Jannes Scholz, Daniel Kondermann, Janis Keuper
Datasets labelled by human annotators are widely used in the training and testing of machine learning models. In recent years, researchers are increasingly paying attention to label quality. However, it is not always possible to objectively determine whether an assigned label is correct or not. The present work investigates this ambiguity in the annotation of autonomous driving datasets as an important dimension of data quality. Our experiments show that excluding highly ambiguous data from the training improves model performance of a state-of-the-art pedestrian detector in terms of LAMR, precision and F1 score, thereby saving training time and annotation costs. Furthermore, we demonstrate that, in order to safely remove ambiguous instances and ensure the retained representativeness of the training data, an understanding of the properties of the dataset and class under investigation is crucial.
Read more5/15/2024

0
Annotating Ambiguous Images: General Annotation Strategy for High-Quality Data with Real-World Biomedical Validation
Lars Schmarje, Vasco Grossmann, Claudius Zelenka, Johannes Brunger, Reinhard Koch
In the field of image classification, existing methods often struggle with biased or ambiguous data, a prevalent issue in real-world scenarios. Current strategies, including semi-supervised learning and class blending, offer partial solutions but lack a definitive resolution. Addressing this gap, our paper introduces a novel strategy for generating high-quality labels in challenging datasets. Central to our approach is a clearly designed flowchart, based on a broad literature review, which enables the creation of reliable labels. We validate our methodology through a rigorous real-world test case in the biomedical field, specifically in deducing height reduction from vertebral imaging. Our empirical study, leveraging over 250,000 annotations, demonstrates the effectiveness of our strategies decisions compared to their alternatives.
Read more4/30/2024
📊
0
No Need to Sacrifice Data Quality for Quantity: Crowd-Informed Machine Annotation for Cost-Effective Understanding of Visual Data
Christopher Klugmann, Rafid Mahmood, Guruprasad Hegde, Amit Kale, Daniel Kondermann
Labeling visual data is expensive and time-consuming. Crowdsourcing systems promise to enable highly parallelizable annotations through the participation of monetarily or otherwise motivated workers, but even this approach has its limits. The solution: replace manual work with machine work. But how reliable are machine annotators? Sacrificing data quality for high throughput cannot be acceptable, especially in safety-critical applications such as autonomous driving. In this paper, we present a framework that enables quality checking of visual data at large scales without sacrificing the reliability of the results. We ask annotators simple questions with discrete answers, which can be highly automated using a convolutional neural network trained to predict crowd responses. Unlike the methods of previous work, which aim to directly predict soft labels to address human uncertainty, we use per-task posterior distributions over soft labels as our training objective, leveraging a Dirichlet prior for analytical accessibility. We demonstrate our approach on two challenging real-world automotive datasets, showing that our model can fully automate a significant portion of tasks, saving costs in the high double-digit percentage range. Our model reliably predicts human uncertainty, allowing for more accurate inspection and filtering of difficult examples. Additionally, we show that the posterior distributions over soft labels predicted by our model can be used as priors in further inference processes, reducing the need for numerous human labelers to approximate true soft labels accurately. This results in further cost reductions and more efficient use of human resources in the annotation process.
Read more9/4/2024
0
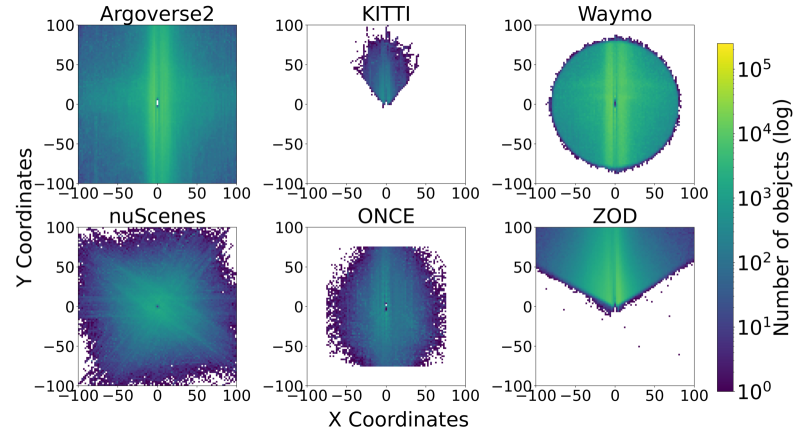
A Survey on Autonomous Driving Datasets: Statistics, Annotation Quality, and a Future Outlook
Mingyu Liu, Ekim Yurtsever, Jonathan Fossaert, Xingcheng Zhou, Walter Zimmer, Yuning Cui, Bare Luka Zagar, Alois C. Knoll
Autonomous driving has rapidly developed and shown promising performance due to recent advances in hardware and deep learning techniques. High-quality datasets are fundamental for developing reliable autonomous driving algorithms. Previous dataset surveys either focused on a limited number or lacked detailed investigation of dataset characteristics. To this end, we present an exhaustive study of 265 autonomous driving datasets from multiple perspectives, including sensor modalities, data size, tasks, and contextual conditions. We introduce a novel metric to evaluate the impact of datasets, which can also be a guide for creating new datasets. Besides, we analyze the annotation processes, existing labeling tools, and the annotation quality of datasets, showing the importance of establishing a standard annotation pipeline. On the other hand, we thoroughly analyze the impact of geographical and adversarial environmental conditions on the performance of autonomous driving systems. Moreover, we exhibit the data distribution of several vital datasets and discuss their pros and cons accordingly. Finally, we discuss the current challenges and the development trend of the future autonomous driving datasets.
Read more4/24/2024