No Need to Sacrifice Data Quality for Quantity: Crowd-Informed Machine Annotation for Cost-Effective Understanding of Visual Data

0
📊
Sign in to get full access
Overview
- Manual labeling of visual data is expensive and time-consuming.
- Crowdsourcing can help, but has its own limitations.
- The solution: replace manual work with machine work.
- But how reliable are machine annotators? Sacrificing data quality is not acceptable, especially in safety-critical applications.
- This paper presents a framework to enable quality checking of visual data at large scales without compromising reliability.
Plain English Explanation
Labeling visual data, such as images or videos, is a crucial task in many applications, like autonomous driving. However, this manual work can be costly and time-consuming. To address this, researchers have turned to crowdsourcing, where multiple people are paid to label the data in parallel.
While crowdsourcing can be helpful, it also has its limitations. The solution proposed in this paper is to replace manual work with machine work. But can we trust machines to accurately label data, especially in safety-critical domains like self-driving cars?
The researchers developed a framework that allows for quality checking of visual data at a large scale, without compromising the reliability of the results. Instead of relying on humans to provide complex labels, the system asks annotators simple questions with discrete answers. These responses are then used to train a convolutional neural network to predict the crowd's answers.
Unlike previous approaches that tried to directly predict the "soft" (or uncertain) labels, this system uses the posterior distributions over the soft labels as the training objective. This allows the model to reliably predict human uncertainty, which can be used to filter out difficult examples and reduce the need for multiple human labelers.
The researchers demonstrate the effectiveness of their approach on two real-world automotive datasets, showing that their model can automate a significant portion of the tasks, leading to substantial cost savings. Additionally, the posterior distributions predicted by the model can be used as priors in further inference processes, further streamlining the annotation process.
Technical Explanation
The paper presents a framework that leverages machine learning to enable quality checking of visual data at large scales, without sacrificing the reliability of the results. Instead of relying on human annotators to provide complex labels, the system asks them simple questions with discrete answers, which can be highly automated using a convolutional neural network (CNN) trained to predict the crowd's responses.
Unlike previous methods that aimed to directly predict soft labels to address human uncertainty, the researchers use per-task posterior distributions over soft labels as their training objective, leveraging a Dirichlet prior for analytical accessibility. This allows the model to reliably predict human uncertainty, enabling more accurate inspection and filtering of difficult examples.
The researchers demonstrate their approach on two challenging real-world automotive datasets, showing that their model can fully automate a significant portion of the tasks, resulting in high double-digit percentage cost savings. Additionally, they show that the posterior distributions over soft labels predicted by their model can be used as priors in further inference processes, reducing the need for numerous human labelers to accurately approximate true soft labels. This leads to further cost reductions and more efficient use of human resources in the annotation process.
Critical Analysis
The researchers present a compelling approach to addressing the challenges of manual labeling of visual data, particularly in safety-critical applications. By leveraging machine learning to automate the quality checking process, they demonstrate significant cost savings without compromising the reliability of the results.
One potential limitation of the approach is that it relies on annotators providing simple, discrete responses to questions. While this can be highly automated, it may not capture the full complexity of some labeling tasks. The researchers acknowledge this and suggest that their framework could be extended to handle more nuanced labeling scenarios.
Additionally, the researchers tested their approach on two automotive datasets, which have their own unique challenges and characteristics. It would be interesting to see how the framework performs on a wider range of visual data types and applications, to better understand its generalizability.
Another area for further research could be exploring ways to further improve the model's ability to predict human uncertainty, potentially through the incorporation of additional features or the exploration of alternative learning objectives.
Overall, the researchers have presented a promising solution to a significant challenge in the field of visual data annotation, and their work opens up interesting avenues for future research and development.
Conclusion
This paper presents a framework that enables quality checking of visual data at large scales without sacrificing the reliability of the results. By replacing manual labeling with machine-driven approaches, the system can automate a significant portion of the tasks, leading to substantial cost savings.
The key innovation of the framework is its use of per-task posterior distributions over soft labels as the training objective, which allows the model to reliably predict human uncertainty. This, in turn, enables more accurate inspection and filtering of difficult examples, as well as the use of the predicted posterior distributions as priors in further inference processes, further streamlining the annotation pipeline.
The researchers have demonstrated the effectiveness of their approach on two real-world automotive datasets, but the broader applicability of the framework to other visual data types and domains remains an area for further exploration. Additionally, continued research into improving the model's ability to predict human uncertainty could lead to even more efficient and reliable visual data annotation processes.
Overall, this work represents an important step forward in addressing the challenges of manual labeling, particularly in safety-critical applications where data quality is paramount.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
No Need to Sacrifice Data Quality for Quantity: Crowd-Informed Machine Annotation for Cost-Effective Understanding of Visual Data
Christopher Klugmann, Rafid Mahmood, Guruprasad Hegde, Amit Kale, Daniel Kondermann
Labeling visual data is expensive and time-consuming. Crowdsourcing systems promise to enable highly parallelizable annotations through the participation of monetarily or otherwise motivated workers, but even this approach has its limits. The solution: replace manual work with machine work. But how reliable are machine annotators? Sacrificing data quality for high throughput cannot be acceptable, especially in safety-critical applications such as autonomous driving. In this paper, we present a framework that enables quality checking of visual data at large scales without sacrificing the reliability of the results. We ask annotators simple questions with discrete answers, which can be highly automated using a convolutional neural network trained to predict crowd responses. Unlike the methods of previous work, which aim to directly predict soft labels to address human uncertainty, we use per-task posterior distributions over soft labels as our training objective, leveraging a Dirichlet prior for analytical accessibility. We demonstrate our approach on two challenging real-world automotive datasets, showing that our model can fully automate a significant portion of tasks, saving costs in the high double-digit percentage range. Our model reliably predicts human uncertainty, allowing for more accurate inspection and filtering of difficult examples. Additionally, we show that the posterior distributions over soft labels predicted by our model can be used as priors in further inference processes, reducing the need for numerous human labelers to approximate true soft labels accurately. This results in further cost reductions and more efficient use of human resources in the annotation process.
Read more9/4/2024
🌀
0
Noise Correction on Subjective Datasets
Uthman Jinadu, Yi Ding
Incorporating every annotator's perspective is crucial for unbiased data modeling. Annotator fatigue and changing opinions over time can distort dataset annotations. To combat this, we propose to learn a more accurate representation of diverse opinions by utilizing multitask learning in conjunction with loss-based label correction. We show that using our novel formulation, we can cleanly separate agreeing and disagreeing annotations. Furthermore, this method provides a controllable way to encourage or discourage disagreement. We demonstrate that this modification can improve prediction performance in a single or multi-annotator setting. Lastly, we show that this method remains robust to additional label noise that is applied to subjective data.
Read more6/5/2024
0
Assistive Image Annotation Systems with Deep Learning and Natural Language Capabilities: A Review
Moseli Mots'oehli
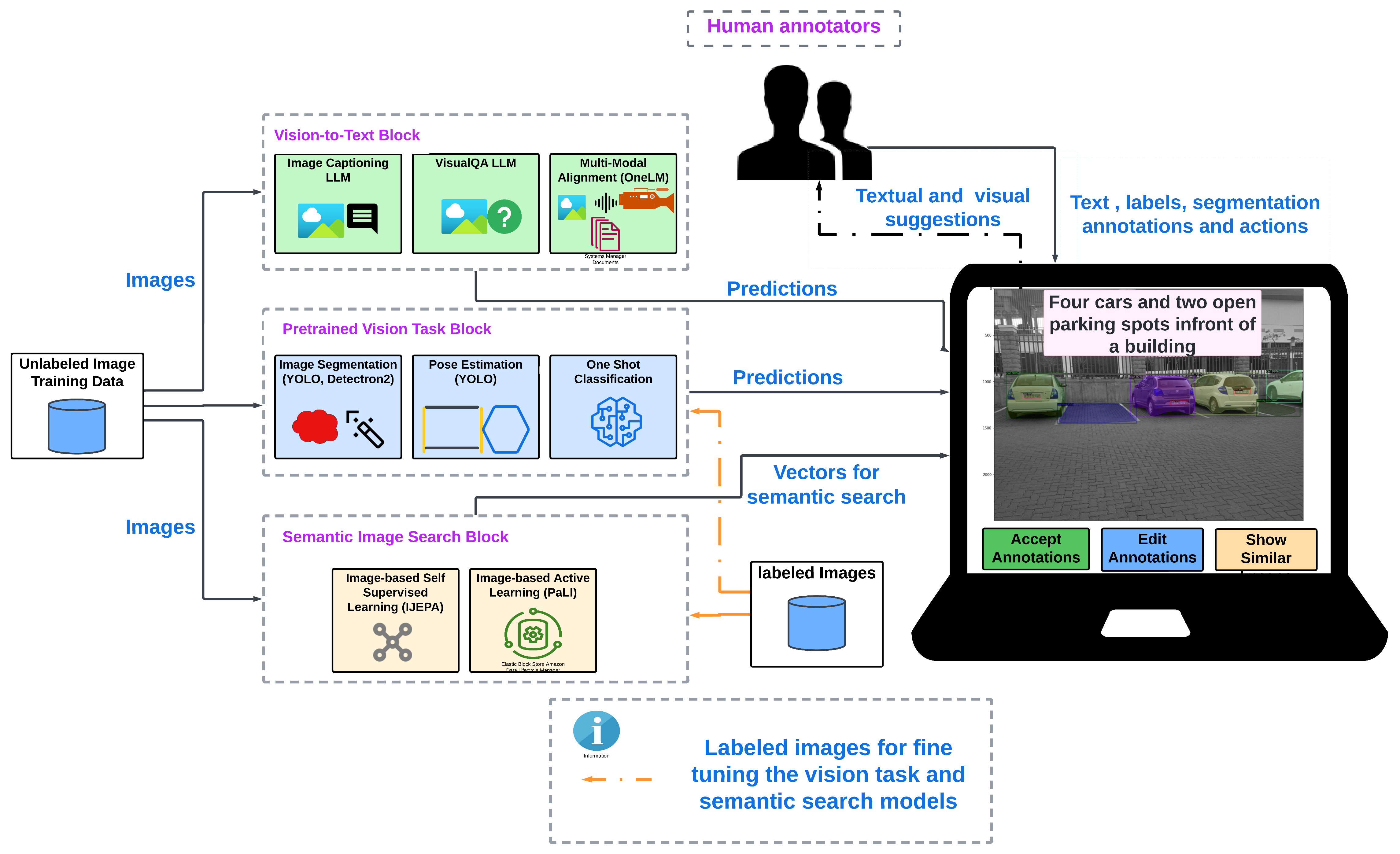
While supervised learning has achieved significant success in computer vision tasks, acquiring high-quality annotated data remains a bottleneck. This paper explores both scholarly and non-scholarly works in AI-assistive deep learning image annotation systems that provide textual suggestions, captions, or descriptions of the input image to the annotator. This potentially results in higher annotation efficiency and quality. Our exploration covers annotation for a range of computer vision tasks including image classification, object detection, regression, instance, semantic segmentation, and pose estimation. We review various datasets and how they contribute to the training and evaluation of AI-assistive annotation systems. We also examine methods leveraging neuro-symbolic learning, deep active learning, and self-supervised learning algorithms that enable semantic image understanding and generate free-text output. These include image captioning, visual question answering, and multi-modal reasoning. Despite the promising potential, there is limited publicly available work on AI-assistive image annotation with textual output capabilities. We conclude by suggesting future research directions to advance this field, emphasizing the need for more publicly accessible datasets and collaborative efforts between academia and industry.
Read more7/2/2024
🔎
0
Automated Detection of Label Errors in Semantic Segmentation Datasets via Deep Learning and Uncertainty Quantification
Matthias Rottmann, Marco Reese
In this work, we for the first time present a method for detecting label errors in image datasets with semantic segmentation, i.e., pixel-wise class labels. Annotation acquisition for semantic segmentation datasets is time-consuming and requires plenty of human labor. In particular, review processes are time consuming and label errors can easily be overlooked by humans. The consequences are biased benchmarks and in extreme cases also performance degradation of deep neural networks (DNNs) trained on such datasets. DNNs for semantic segmentation yield pixel-wise predictions, which makes detection of label errors via uncertainty quantification a complex task. Uncertainty is particularly pronounced at the transitions between connected components of the prediction. By lifting the consideration of uncertainty to the level of predicted components, we enable the usage of DNNs together with component-level uncertainty quantification for the detection of label errors. We present a principled approach to benchmarking the task of label error detection by dropping labels from the Cityscapes dataset as well from a dataset extracted from the CARLA driving simulator, where in the latter case we have the labels under control. Our experiments show that our approach is able to detect the vast majority of label errors while controlling the number of false label error detections. Furthermore, we apply our method to semantic segmentation datasets frequently used by the computer vision community and present a collection of label errors along with sample statistics.
Read more8/27/2024