AMEND: A Mixture of Experts Framework for Long-tailed Trajectory Prediction
2402.08698
0
0
Abstract
Accurate prediction of pedestrians' future motions is critical for intelligent driving systems. Developing models for this task requires rich datasets containing diverse sets of samples. However, the existing naturalistic trajectory prediction datasets are generally imbalanced in favor of simpler samples and lack challenging scenarios. Such a long-tail effect causes prediction models to underperform on the tail portion of the data distribution containing safety-critical scenarios. Previous methods tackle the long-tail problem using methods such as contrastive learning and class-conditioned hypernetworks. These approaches, however, are not modular and cannot be applied to many machine learning architectures. In this work, we propose a modular model-agnostic framework for trajectory prediction that leverages a specialized mixture of experts. In our approach, each expert is trained with a specialized skill with respect to a particular part of the data. To produce predictions, we utilise a router network that selects the best expert by generating relative confidence scores. We conduct experimentation on common pedestrian trajectory prediction datasets and show that our method improves performance on long-tail scenarios. We further conduct ablation studies to highlight the contribution of different proposed components.
Create account to get full access
Overview
- This paper proposes a novel framework called AMEND (A Mixture of Experts for long-tailed Trajectory Prediction) to address the challenge of long-tailed trajectory prediction, where the model needs to accurately predict the future trajectories of diverse agents like pedestrians, cyclists, and vehicles.
- The key idea is to use a mixture of specialized expert models, each focused on a particular subset of the data, to capture the underlying heterogeneity and improve overall prediction performance.
- The framework includes several technical innovations, such as a meta-controller that dynamically selects the most appropriate expert model for each input, and a novel loss function that encourages the experts to specialize in different regions of the input space.
Plain English Explanation
The paper describes a new way to predict the future movements of different types of agents, such as pedestrians, cyclists, and vehicles. This is a challenging problem because there is a wide variety of possible trajectories, and some of the less common ones can be difficult for a single model to capture accurately.
The proposed solution, called AMEND, is to use a collection of specialized "expert" models, each focused on a particular subset of the data. For example, one expert might be better at predicting the trajectories of pedestrians, while another might handle cyclists more effectively. A "meta-controller" then decides which expert to use for each new input, allowing the system to adaptively choose the most appropriate model.
This approach has several advantages. By dividing the problem across multiple experts, the model can better capture the underlying diversity of the data. And the meta-controller ensures that the right expert is used for each situation, rather than relying on a single, general-purpose model that may struggle with less common cases.
The paper also introduces a novel training technique to encourage the experts to specialize in different regions of the input space, further enhancing the model's ability to handle the long-tailed distribution of trajectory data.
Technical Explanation
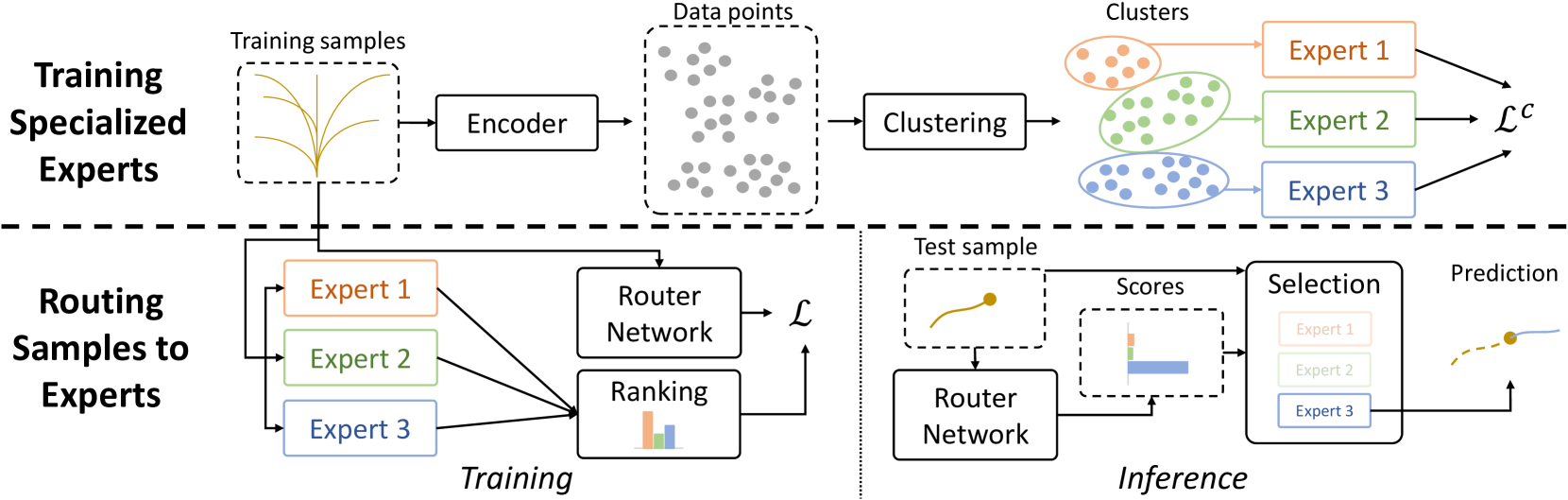
The AMEND framework [<a href="https://aimodels.fyi/papers/arxiv/tract-training-dynamics-aware-contrastive-learning-framework">1</a>, <a href="https://aimodels.fyi/papers/arxiv/cognitive-driven-trajectory-prediction-model-autonomous-driving">2</a>, <a href="https://aimodels.fyi/papers/arxiv/evaluating-pedestrian-trajectory-prediction-methods-respect-to">3</a>] consists of a collection of specialized "expert" models, each focused on a particular subset of the trajectory data. A "meta-controller" dynamically selects the most appropriate expert to use for each input.
The experts are trained using a novel loss function that encourages them to specialize in different regions of the input space. This is achieved by adding a term that penalizes experts for making confident predictions on samples that are better handled by other experts. This "competitive" training process helps the experts to diversify and collectively cover the long-tailed distribution of trajectory data.
The meta-controller is implemented as a neural network that takes the current observation and history as input, and outputs a probability distribution over the experts. This allows the framework to adaptively choose the most appropriate expert for each new situation.
The authors evaluate AMEND on several standard trajectory prediction benchmarks, including the Stanford Drone Dataset and the nuScenes dataset. The results show that AMEND outperforms a range of state-of-the-art baselines, particularly on the long-tailed regions of the data distribution.
Critical Analysis
The AMEND framework represents an interesting and promising approach to the challenging problem of long-tailed trajectory prediction. By leveraging a mixture of specialized experts, the model is able to better capture the underlying heterogeneity in the data, which is a key strength.
However, the paper does not fully address the potential limitations of this approach. For example, the training process required to encourage the experts to specialize may be computationally expensive and sensitive to hyperparameter tuning. Additionally, the reliance on a meta-controller to dynamically select the experts introduces an additional layer of complexity that could impact the model's interpretability and robustness.
Furthermore, the evaluation is primarily focused on standard benchmark datasets, which may not fully reflect the real-world challenges faced by trajectory prediction systems, such as the presence of dynamic obstacles, sensor noise, and partial observability [<a href="https://aimodels.fyi/papers/arxiv/survey-robustness-trajectory-prediction-autonomous-vehicles">4</a>]. Additional studies on the model's performance in more realistic settings would be valuable.
Finally, the paper does not explore the potential connections between the AMEND framework and other related research areas, such as [<a href="https://aimodels.fyi/papers/arxiv/multi-agent-long-term-3d-human-pose">5</a>], which could provide additional insights and opportunities for further development.
Conclusion
The AMEND framework proposed in this paper represents a significant advance in the field of long-tailed trajectory prediction. By leveraging a mixture of specialized expert models and a dynamic meta-controller, the system is able to adaptively handle the diverse range of trajectories encountered in real-world scenarios.
The technical innovations introduced in this work, particularly the novel training process that encourages expert diversification, are likely to have broader implications for other areas of machine learning and AI. As the field continues to grapple with the challenges of long-tailed and heterogeneous data distributions, the principles and insights from this research will likely become increasingly important.
Overall, the AMEND framework is a valuable contribution to the trajectory prediction literature, and the authors have demonstrated its effectiveness on standard benchmarks. However, further research is needed to fully understand the model's limitations and explore its potential applications in more realistic, real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

TrACT: A Training Dynamics Aware Contrastive Learning Framework for Long-tail Trajectory Prediction
Junrui Zhang, Mozhgan Pourkeshavarz, Amir Rasouli
0
0
As a safety critical task, autonomous driving requires accurate predictions of road users' future trajectories for safe motion planning, particularly under challenging conditions. Yet, many recent deep learning methods suffer from a degraded performance on the challenging scenarios, mainly because these scenarios appear less frequently in the training data. To address such a long-tail issue, existing methods force challenging scenarios closer together in the feature space during training to trigger information sharing among them for more robust learning. These methods, however, primarily rely on the motion patterns to characterize scenarios, omitting more informative contextual information, such as interactions and scene layout. We argue that exploiting such information not only improves prediction accuracy but also scene compliance of the generated trajectories. In this paper, we propose to incorporate richer training dynamics information into a prototypical contrastive learning framework. More specifically, we propose a two-stage process. First, we generate rich contextual features using a baseline encoder-decoder framework. These features are split into clusters based on the model's output errors, using the training dynamics information, and a prototype is computed within each cluster. Second, we retrain the model using the prototypes in a contrastive learning framework. We conduct empirical evaluations of our approach using two large-scale naturalistic datasets and show that our method achieves state-of-the-art performance by improving accuracy and scene compliance on the long-tail samples. Furthermore, we perform experiments on a subset of the clusters to highlight the additional benefit of our approach in reducing training bias.
5/1/2024
🐍
Delving into the Trajectory Long-tail Distribution for Muti-object Tracking
Sijia Chen, En Yu, Jinyang Li, Wenbing Tao
0
0
Multiple Object Tracking (MOT) is a critical area within computer vision, with a broad spectrum of practical implementations. Current research has primarily focused on the development of tracking algorithms and enhancement of post-processing techniques. Yet, there has been a lack of thorough examination concerning the nature of tracking data it self. In this study, we pioneer an exploration into the distribution patterns of tracking data and identify a pronounced long-tail distribution issue within existing MOT datasets. We note a significant imbalance in the distribution of trajectory lengths across different pedestrians, a phenomenon we refer to as ``pedestrians trajectory long-tail distribution''. Addressing this challenge, we introduce a bespoke strategy designed to mitigate the effects of this skewed distribution. Specifically, we propose two data augmentation strategies, including Stationary Camera View Data Augmentation (SVA) and Dynamic Camera View Data Augmentation (DVA) , designed for viewpoint states and the Group Softmax (GS) module for Re-ID. SVA is to backtrack and predict the pedestrian trajectory of tail classes, and DVA is to use diffusion model to change the background of the scene. GS divides the pedestrians into unrelated groups and performs softmax operation on each group individually. Our proposed strategies can be integrated into numerous existing tracking systems, and extensive experimentation validates the efficacy of our method in reducing the influence of long-tail distribution on multi-object tracking performance. The code is available at https://github.com/chen-si-jia/Trajectory-Long-tail-Distribution-for-MOT.
5/27/2024
Continual Traffic Forecasting via Mixture of Experts
Sanghyun Lee, Chanyoung Park
0
0
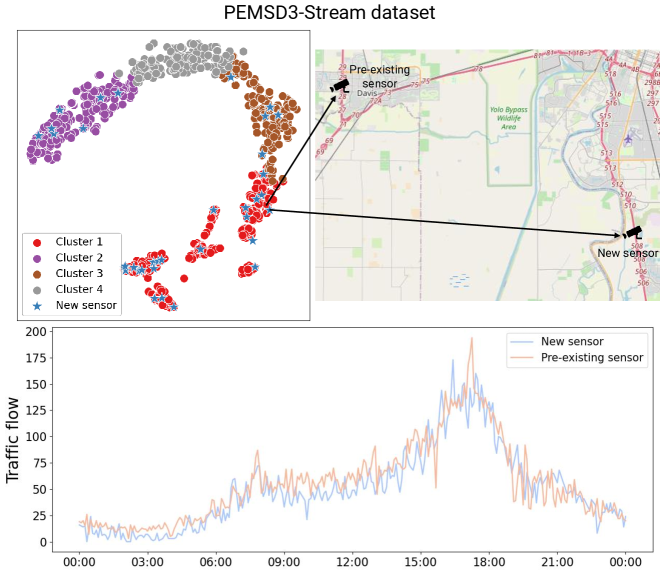
The real-world traffic networks undergo expansion through the installation of new sensors, implying that the traffic patterns continually evolve over time. Incrementally training a model on the newly added sensors would make the model forget the past knowledge, i.e., catastrophic forgetting, while retraining the model on the entire network to capture these changes is highly inefficient. To address these challenges, we propose a novel Traffic Forecasting Mixture of Experts (TFMoE) for traffic forecasting under evolving networks. The main idea is to segment the traffic flow into multiple homogeneous groups, and assign an expert model responsible for a specific group. This allows each expert model to concentrate on learning and adapting to a specific set of patterns, while minimizing interference between the experts during training, thereby preventing the dilution or replacement of prior knowledge, which is a major cause of catastrophic forgetting. Through extensive experiments on a real-world long-term streaming network dataset, PEMSD3-Stream, we demonstrate the effectiveness and efficiency of TFMoE. Our results showcase superior performance and resilience in the face of catastrophic forgetting, underscoring the effectiveness of our approach in dealing with continual learning for traffic flow forecasting in long-term streaming networks.
6/6/2024
Mixture-of-Linear-Experts for Long-term Time Series Forecasting
Ronghao Ni, Zinan Lin, Shuaiqi Wang, Giulia Fanti
0
0
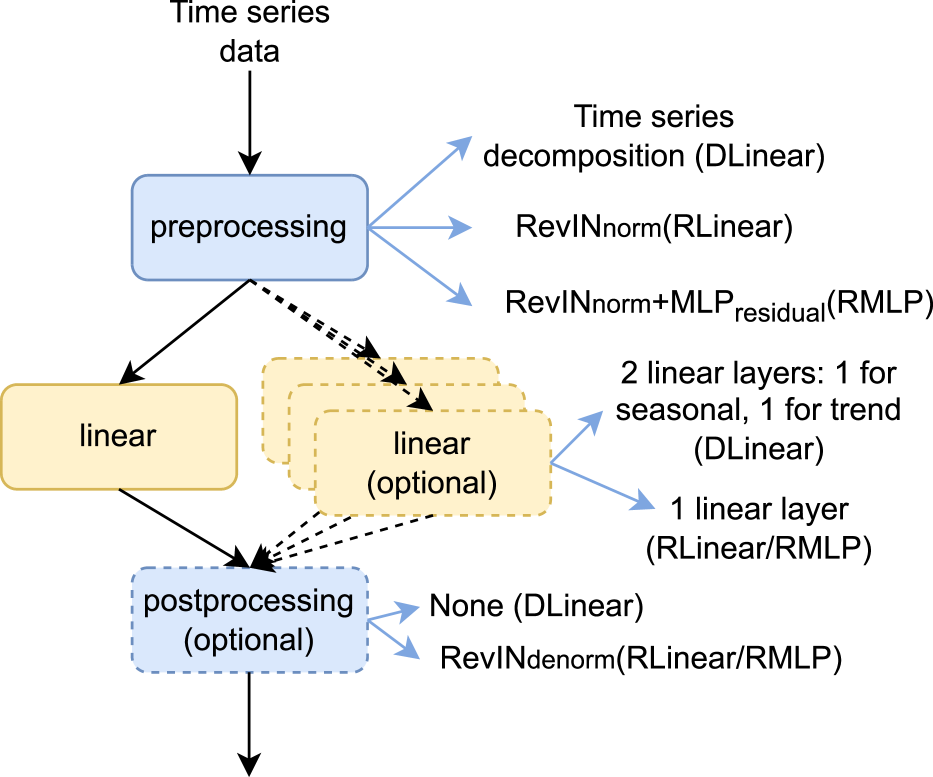
Long-term time series forecasting (LTSF) aims to predict future values of a time series given the past values. The current state-of-the-art (SOTA) on this problem is attained in some cases by linear-centric models, which primarily feature a linear mapping layer. However, due to their inherent simplicity, they are not able to adapt their prediction rules to periodic changes in time series patterns. To address this challenge, we propose a Mixture-of-Experts-style augmentation for linear-centric models and propose Mixture-of-Linear-Experts (MoLE). Instead of training a single model, MoLE trains multiple linear-centric models (i.e., experts) and a router model that weighs and mixes their outputs. While the entire framework is trained end-to-end, each expert learns to specialize in a specific temporal pattern, and the router model learns to compose the experts adaptively. Experiments show that MoLE reduces forecasting error of linear-centric models, including DLinear, RLinear, and RMLP, in over 78% of the datasets and settings we evaluated. By using MoLE existing linear-centric models can achieve SOTA LTSF results in 68% of the experiments that PatchTST reports and we compare to, whereas existing single-head linear-centric models achieve SOTA results in only 25% of cases.
5/3/2024