AMRFact: Enhancing Summarization Factuality Evaluation with AMR-Driven Negative Samples Generation
2311.09521
0
0
🛸
Abstract
Ensuring factual consistency is crucial for natural language generation tasks, particularly in abstractive summarization, where preserving the integrity of information is paramount. Prior works on evaluating factual consistency of summarization often take the entailment-based approaches that first generate perturbed (factual inconsistent) summaries and then train a classifier on the generated data to detect the factually inconsistencies during testing time. However, previous approaches generating perturbed summaries are either of low coherence or lack error-type coverage. To address these issues, we propose AMRFact, a framework that generates perturbed summaries using Abstract Meaning Representations (AMRs). Our approach parses factually consistent summaries into AMR graphs and injects controlled factual inconsistencies to create negative examples, allowing for coherent factually inconsistent summaries to be generated with high error-type coverage. Additionally, we present a data selection module NegFilter based on natural language inference and BARTScore to ensure the quality of the generated negative samples. Experimental results demonstrate our approach significantly outperforms previous systems on the AggreFact-SOTA benchmark, showcasing its efficacy in evaluating factuality of abstractive summarization.
Create account to get full access
Overview
- Ensuring factual consistency is critical for natural language generation tasks, especially in abstractive summarization where preserving information integrity is paramount.
- Prior work on evaluating factual consistency often uses entailment-based approaches that generate factually inconsistent summaries and train a classifier to detect them.
- However, previous approaches have issues with low coherence or limited error-type coverage in the generated summaries.
Plain English Explanation
When computers generate text, it's important that the information is factually accurate. This is especially true for summarization, where the goal is to briefly capture the key points of a longer document. If the summary contains factual errors, it defeats the purpose.
Researchers have tried to address this by creating "wrong" or factually inconsistent summaries and using them to train a system to detect when a summary is inaccurate. However, the previous methods for generating these flawed summaries had problems. The summaries either didn't make sense logically, or they didn't cover a wide enough range of potential errors.
To solve this, the researchers developed a new framework called AMRFact. Their approach first analyzes the structure of a factually correct summary using a technique called Abstract Meaning Representation (AMR). It then systematically introduces controlled factual mistakes into the summary, creating new examples that are coherent but inaccurate. This gives them a diverse dataset of both correct and incorrect summaries to train a model on.
They also include an additional step to further ensure the quality of the generated "bad" summaries, using natural language processing and a scoring metric called BARTScore.
Technical Explanation
The AMRFact framework generates perturbed, factually inconsistent summaries by first parsing factually consistent summaries into Abstract Meaning Representation (AMR) graphs. It then injects controlled factual inconsistencies into these AMR graphs to create negative examples. This approach allows for the generation of coherent, factually inconsistent summaries with high error-type coverage.
Additionally, AMRFact includes a data selection module called NegFilter that leverages natural language inference and BARTScore to ensure the quality of the generated negative samples. The BARTScore metric is used to measure the fluency and coherence of the perturbed summaries.
Experimental results on the AggreFact-SOTA benchmark demonstrate that the AMRFact framework significantly outperforms previous systems in evaluating the factual consistency of abstractive summarization. This showcases the efficacy of the AMR-based perturbation approach and the data selection module in producing high-quality datasets for factuality evaluation.
Critical Analysis
The AMRFact framework represents an important advancement in evaluating the factual consistency of abstractive summarization systems. By generating coherent, factually inconsistent summaries with broad error coverage, it addresses key limitations of prior approaches.
However, the paper does not discuss the scalability of the AMR-based perturbation approach, particularly for summarizing longer, more complex documents. Additionally, the authors acknowledge that their current implementation relies on human-annotated AMR graphs, which may limit the practicality of applying the framework to large-scale summarization tasks.
Further research could explore techniques to automate the AMR parsing and perturbation process, potentially leveraging large language models for this purpose. Investigating the robustness of the NegFilter module to different types of factual errors would also be a valuable direction for future work.
Conclusion
The AMRFact framework represents a significant advancement in evaluating the factual consistency of abstractive summarization systems. By generating coherent, factually inconsistent summaries with broad error coverage, it addresses key limitations of prior approaches and demonstrates impressive performance on the AggreFact-SOTA benchmark.
While the current implementation has some scalability and automation challenges, the core ideas behind AMRFact – leveraging structured representations like AMR and employing rigorous data selection – offer a promising path forward for ensuring the integrity of information in natural language generation tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Factual Dialogue Summarization via Learning from Large Language Models
Rongxin Zhu, Jey Han Lau, Jianzhong Qi
0
0
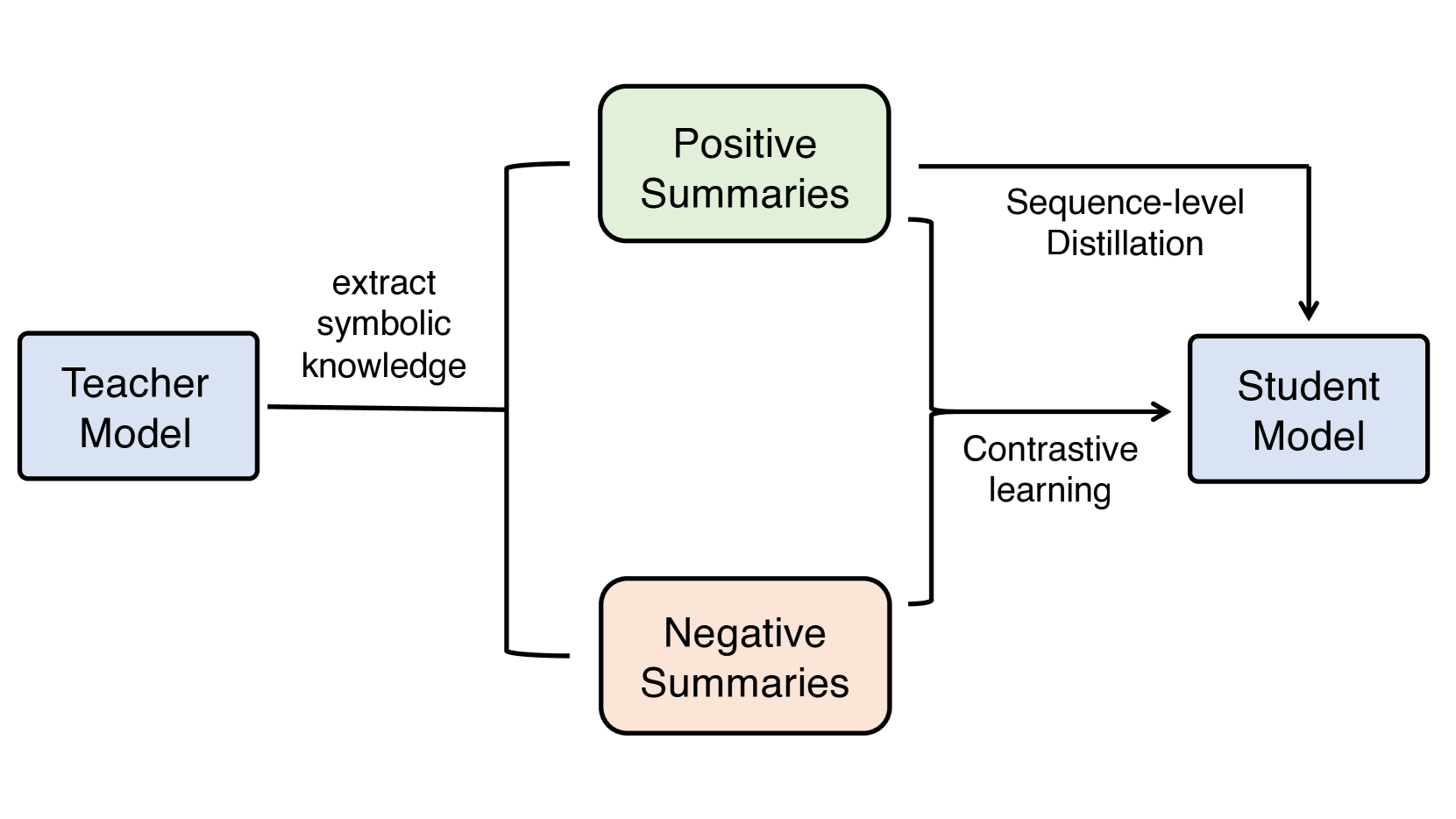
Factual consistency is an important quality in dialogue summarization. Large language model (LLM)-based automatic text summarization models generate more factually consistent summaries compared to those by smaller pretrained language models, but they face deployment challenges in real-world applications due to privacy or resource constraints. In this paper, we investigate the use of symbolic knowledge distillation to improve the factual consistency of smaller pretrained models for dialogue summarization. We employ zero-shot learning to extract symbolic knowledge from LLMs, generating both factually consistent (positive) and inconsistent (negative) summaries. We then apply two contrastive learning objectives on these summaries to enhance smaller summarization models. Experiments with BART, PEGASUS, and Flan-T5 indicate that our approach surpasses strong baselines that rely on complex data augmentation strategies. Our approach achieves better factual consistency while maintaining coherence, fluency, and relevance, as confirmed by various automatic evaluation metrics. We also provide access to the data and code to facilitate future research.
6/24/2024
Structured Information Matters: Incorporating Abstract Meaning Representation into LLMs for Improved Open-Domain Dialogue Evaluation
Bohao Yang, Kun Zhao, Chen Tang, Liang Zhan, Chenghua Lin
0
0
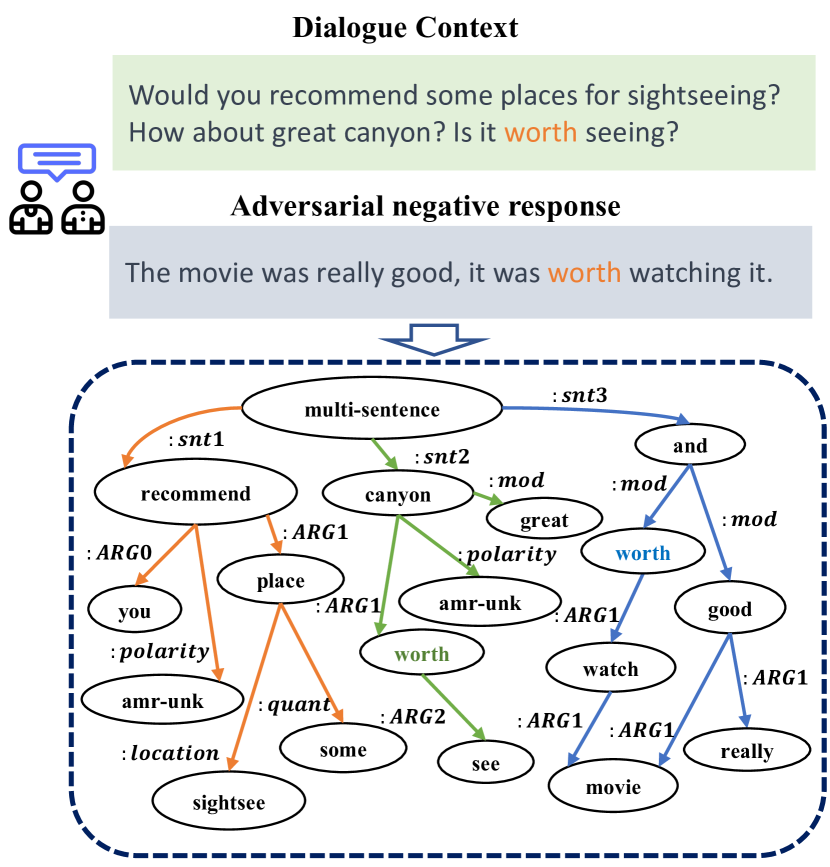
Automatic open-domain dialogue evaluation has attracted increasing attention. Trainable evaluation metrics are commonly trained with true positive and randomly selected negative responses, resulting in a tendency for them to assign a higher score to the responses that share higher content similarity with a given context. However, adversarial negative responses possess high content similarity with the contexts whilst being semantically different. Therefore, existing evaluation metrics are not robust enough to evaluate such responses, resulting in low correlations with human judgments. While recent studies have shown some efficacy in utilizing Large Language Models (LLMs) for open-domain dialogue evaluation, they still encounter challenges in effectively handling adversarial negative examples. In this paper, we propose a simple yet effective framework for open-domain dialogue evaluation, which combines domain-specific language models (SLMs) with LLMs. The SLMs can explicitly incorporate Abstract Meaning Representation (AMR) graph information of the dialogue through a gating mechanism for enhanced semantic representation learning. The evaluation result of SLMs and AMR graph information are plugged into the prompt of LLM, for the enhanced in-context learning performance. Experimental results on open-domain dialogue evaluation tasks demonstrate the superiority of our method compared to a wide range of state-of-the-art baselines, especially in discriminating adversarial negative responses. Our code is available at https://github.com/Bernard-Yang/SIMAMR.
4/9/2024
Retrieval Augmented Fact Verification by Synthesizing Contrastive Arguments
Zhenrui Yue, Huimin Zeng, Lanyu Shang, Yifan Liu, Yang Zhang, Dong Wang
0
0
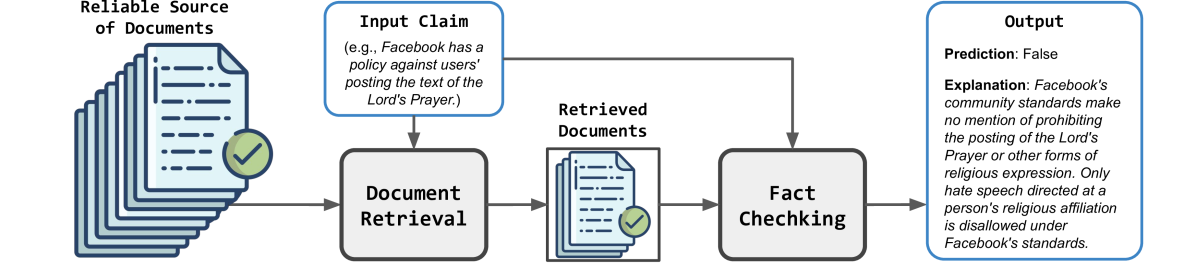
The rapid propagation of misinformation poses substantial risks to public interest. To combat misinformation, large language models (LLMs) are adapted to automatically verify claim credibility. Nevertheless, existing methods heavily rely on the embedded knowledge within LLMs and / or black-box APIs for evidence collection, leading to subpar performance with smaller LLMs or upon unreliable context. In this paper, we propose retrieval augmented fact verification through the synthesis of contrasting arguments (RAFTS). Upon input claims, RAFTS starts with evidence retrieval, where we design a retrieval pipeline to collect and re-rank relevant documents from verifiable sources. Then, RAFTS forms contrastive arguments (i.e., supporting or refuting) conditioned on the retrieved evidence. In addition, RAFTS leverages an embedding model to identify informative demonstrations, followed by in-context prompting to generate the prediction and explanation. Our method effectively retrieves relevant documents as evidence and evaluates arguments from varying perspectives, incorporating nuanced information for fine-grained decision-making. Combined with informative in-context examples as prior, RAFTS achieves significant improvements to supervised and LLM baselines without complex prompts. We demonstrate the effectiveness of our method through extensive experiments, where RAFTS can outperform GPT-based methods with a significantly smaller 7B LLM.
6/17/2024

FIZZ: Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document
Joonho Yang, Seunghyun Yoon, Byeongjeong Kim, Hwanhee Lee
0
0
Through the advent of pre-trained language models, there have been notable advancements in abstractive summarization systems. Simultaneously, a considerable number of novel methods for evaluating factual consistency in abstractive summarization systems has been developed. But these evaluation approaches incorporate substantial limitations, especially on refinement and interpretability. In this work, we propose highly effective and interpretable factual inconsistency detection method metric Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document for abstractive summarization systems that is based on fine-grained atomic facts decomposition. Moreover, we align atomic facts decomposed from the summary with the source document through adaptive granularity expansion. These atomic facts represent a more fine-grained unit of information, facilitating detailed understanding and interpretability of the summary's factual inconsistency. Experimental results demonstrate that our proposed factual consistency checking system significantly outperforms existing systems.
4/19/2024