Factual Dialogue Summarization via Learning from Large Language Models
2406.14709
0
0
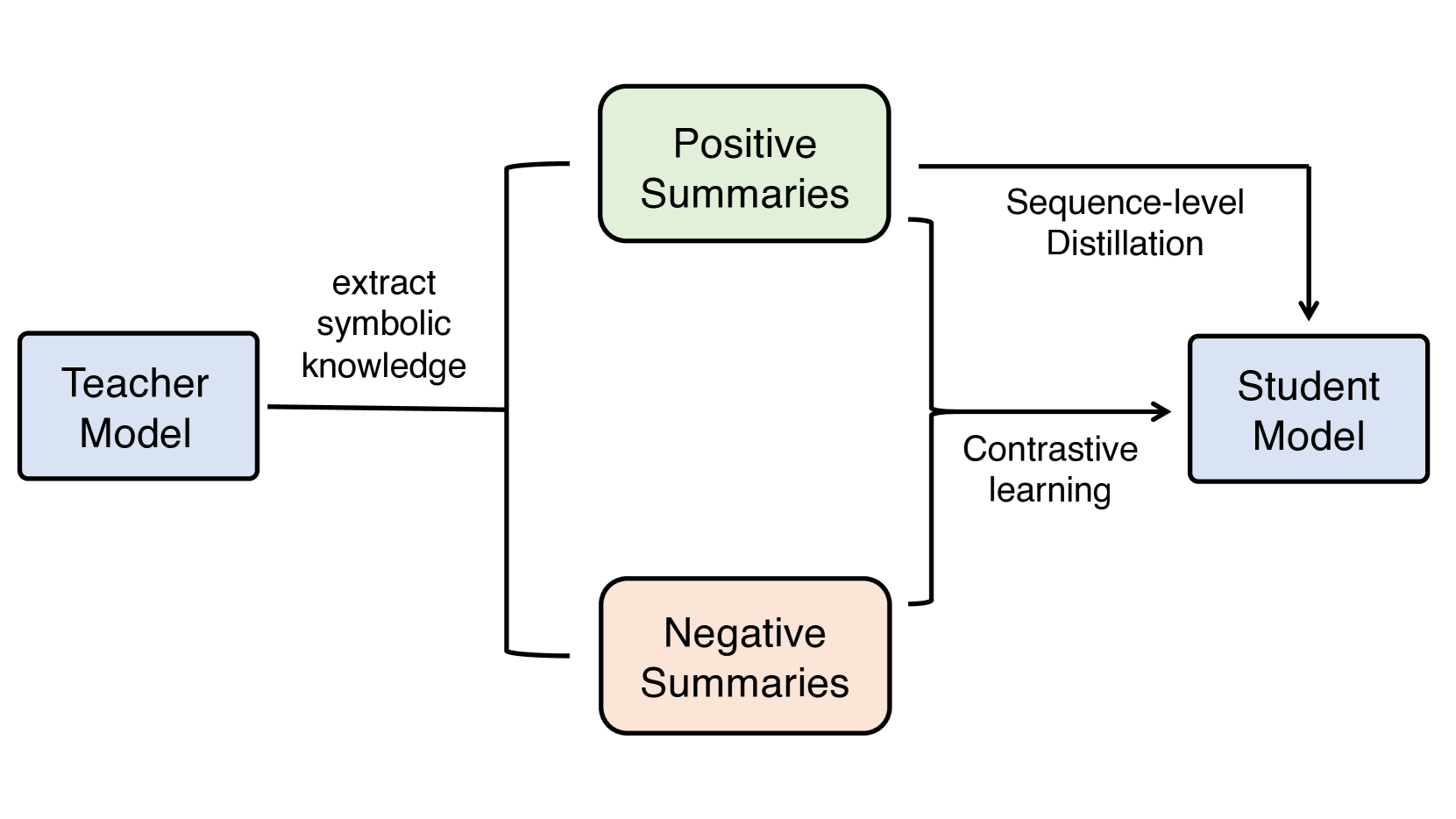
Abstract
Factual consistency is an important quality in dialogue summarization. Large language model (LLM)-based automatic text summarization models generate more factually consistent summaries compared to those by smaller pretrained language models, but they face deployment challenges in real-world applications due to privacy or resource constraints. In this paper, we investigate the use of symbolic knowledge distillation to improve the factual consistency of smaller pretrained models for dialogue summarization. We employ zero-shot learning to extract symbolic knowledge from LLMs, generating both factually consistent (positive) and inconsistent (negative) summaries. We then apply two contrastive learning objectives on these summaries to enhance smaller summarization models. Experiments with BART, PEGASUS, and Flan-T5 indicate that our approach surpasses strong baselines that rely on complex data augmentation strategies. Our approach achieves better factual consistency while maintaining coherence, fluency, and relevance, as confirmed by various automatic evaluation metrics. We also provide access to the data and code to facilitate future research.
Create account to get full access
Overview
- This paper explores a novel approach to factual dialogue summarization by leveraging large language models.
- The researchers aim to improve the factual accuracy and consistency of dialogue summaries by training models to learn from the knowledge and reasoning capabilities of pre-trained language models.
- The proposed method outperforms previous state-of-the-art dialogue summarization models on benchmark datasets, demonstrating the potential of this approach.
Plain English Explanation
The paper focuses on the challenge of accurately summarizing the key facts and information from a dialogue or conversation. Existing dialogue summarization models often struggle to maintain factual consistency and produce summaries that faithfully capture the content of the original dialogue.
To address this, the researchers propose a new method that leverages the impressive knowledge and reasoning abilities of large language models, such as GPT-3 [<a class="ltx_ref" href="https://aimodels.fyi/papers/arxiv/towards-logically-consistent-language-models-via-probabilistic">1</a>]. By fine-tuning these powerful language models on dialogue summarization tasks, the researchers aim to imbue the summarization models with a stronger grasp of facts and logical reasoning.
The key idea is that the language models, having been trained on massive amounts of text data, have developed a deep understanding of the world and how information is typically expressed. By incorporating this knowledge into the dialogue summarization process, the researchers hope to generate summaries that are more factually accurate and consistent with the original dialogue.
This approach builds on related work in areas like [<a class="ltx_ref" href="https://aimodels.fyi/papers/arxiv/identifying-factual-inconsistencies-summaries-grounding-model-inference">2</a>] and [<a class="ltx_ref" href="https://aimodels.fyi/papers/arxiv/synfac-edit-synthetic-imitation-edit-feedback-factual">3</a>], which have explored ways to improve the factual grounding of language models and the consistency of their outputs.
Technical Explanation
The core of the proposed approach is a dialogue summarization model that is fine-tuned on large language models like GPT-3. The researchers first pre-train the language model on a diverse corpus of text data, allowing it to develop a rich understanding of language, facts, and reasoning.
They then fine-tune this pre-trained model on a dialogue summarization task, using a dataset of dialogues and their corresponding human-written summaries. By exposing the model to these examples during training, it learns to generate summaries that not only capture the key points of the dialogue but also maintain factual consistency and accuracy.
The researchers experiment with different fine-tuning strategies, including techniques like [<a class="ltx_ref" href="https://aimodels.fyi/papers/arxiv/learning-to-generate-answers-citations-via-factual">4</a>] and [<a class="ltx_ref" href="https://aimodels.fyi/papers/arxiv/fizz-factual-inconsistency-detection-by-zoom-summary">5</a>], to further enhance the factual grounding of the summarization model.
Through extensive evaluation on benchmark dialogue summarization datasets, the researchers demonstrate that their approach outperforms previous state-of-the-art models in terms of both factual accuracy and overall summary quality. The results suggest that leveraging the knowledge and reasoning capabilities of large language models can be a promising avenue for improving the reliability and usefulness of dialogue summarization systems.
Critical Analysis
The researchers acknowledge that their approach is not without limitations. The reliance on pre-trained language models means that the summarization model's performance is ultimately bounded by the capabilities of the underlying language model, which may have biases or gaps in its knowledge.
Additionally, the fine-tuning process can be computationally intensive and may require significant resources, which could limit the practical deployment of this approach in resource-constrained settings.
The paper also does not address the potential ethical implications of using large language models, which have been shown to exhibit biases and generate harmful content in certain cases. Careful consideration of these issues would be necessary before deploying such systems in real-world applications.
Overall, the researchers have made an important contribution to the field of dialogue summarization, demonstrating the potential of leveraging large language models to improve the factual accuracy and consistency of summaries. However, further research is needed to address the limitations and scale this approach for practical use cases.
Conclusion
This paper presents a novel approach to factual dialogue summarization that leverages the knowledge and reasoning capabilities of large language models. By fine-tuning these powerful models on dialogue summarization tasks, the researchers have developed a system that outperforms previous state-of-the-art methods in terms of factual accuracy and overall summary quality.
The findings of this research suggest that incorporating the insights and capabilities of large language models can be a promising direction for improving the reliability and usefulness of dialogue summarization systems. As language models continue to advance, this approach may become increasingly valuable for a wide range of applications that require accurate and consistent summarization of conversational data.
However, the researchers acknowledge the limitations of their approach and the need for further research to address ethical concerns and practical deployment challenges. Nonetheless, this work represents an important step forward in the quest for more trustworthy and informative dialogue summarization systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning to Generate Answers with Citations via Factual Consistency Models
Rami Aly, Zhiqiang Tang, Samson Tan, George Karypis
0
0
Large Language Models (LLMs) frequently hallucinate, impeding their reliability in mission-critical situations. One approach to address this issue is to provide citations to relevant sources alongside generated content, enhancing the verifiability of generations. However, citing passages accurately in answers remains a substantial challenge. This paper proposes a weakly-supervised fine-tuning method leveraging factual consistency models (FCMs). Our approach alternates between generating texts with citations and supervised fine-tuning with FCM-filtered citation data. Focused learning is integrated into the objective, directing the fine-tuning process to emphasise the factual unit tokens, as measured by an FCM. Results on the ALCE few-shot citation benchmark with various instruction-tuned LLMs demonstrate superior performance compared to in-context learning, vanilla supervised fine-tuning, and state-of-the-art methods, with an average improvement of $34.1$, $15.5$, and $10.5$ citation F$_1$ points, respectively. Moreover, in a domain transfer setting we show that the obtained citation generation ability robustly transfers to unseen datasets. Notably, our citation improvements contribute to the lowest factual error rate across baselines.
6/21/2024

Identifying Factual Inconsistencies in Summaries: Grounding Model Inference via Task Taxonomy
Liyan Xu, Zhenlin Su, Mo Yu, Jin Xu, Jinho D. Choi, Jie Zhou, Fei Liu
0
0
Factual inconsistencies pose a significant hurdle for the faithful summarization by generative models. While a major direction to enhance inconsistency detection is to derive stronger Natural Language Inference (NLI) models, we propose an orthogonal aspect that underscores the importance of incorporating task-specific taxonomy into the inference. To this end, we consolidate key error types of inconsistent facts in summaries, and incorporate them to facilitate both the zero-shot and supervised paradigms of LLMs. Extensive experiments on ten datasets of five distinct domains suggest that, zero-shot LLM inference could benefit from the explicit solution space depicted by the error type taxonomy, and achieves state-of-the-art performance overall, surpassing specialized non-LLM baselines, as well as recent LLM baselines. We further distill models that fuse the taxonomy into parameters through our designed prompt completions and supervised training strategies, efficiently substituting state-of-the-art zero-shot inference with much larger LLMs.
6/21/2024
Towards Logically Consistent Language Models via Probabilistic Reasoning
Diego Calanzone, Stefano Teso, Antonio Vergari
0
0
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about beliefs of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with our loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines and allows them to extrapolate to unseen but semantically similar factual knowledge more systematically.
4/22/2024

SYNFAC-EDIT: Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Prakamya Mishra, Zonghai Yao, Parth Vashisht, Feiyun Ouyang, Beining Wang, Vidhi Dhaval Mody, Hong Yu
0
0
Large Language Models (LLMs) such as GPT & Llama have demonstrated significant achievements in summarization tasks but struggle with factual inaccuracies, a critical issue in clinical NLP applications where errors could lead to serious consequences. To counter the high costs and limited availability of expert-annotated data for factual alignment, this study introduces an innovative pipeline that utilizes >100B parameter GPT variants like GPT-3.5 & GPT-4 to act as synthetic experts to generate high-quality synthetics feedback aimed at enhancing factual consistency in clinical note summarization. Our research primarily focuses on edit feedback generated by these synthetic feedback experts without additional human annotations, mirroring and optimizing the practical scenario in which medical professionals refine AI system outputs. Although such 100B+ parameter GPT variants have proven to demonstrate expertise in various clinical NLP tasks, such as the Medical Licensing Examination, there is scant research on their capacity to act as synthetic feedback experts and deliver expert-level edit feedback for improving the generation quality of weaker (<10B parameter) LLMs like GPT-2 (1.5B) & Llama 2 (7B) in clinical domain. So in this work, we leverage 100B+ GPT variants to act as synthetic feedback experts offering expert-level edit feedback, that is used to reduce hallucinations and align weaker (<10B parameter) LLMs with medical facts using two distinct alignment algorithms (DPO & SALT), endeavoring to narrow the divide between AI-generated content and factual accuracy. This highlights the substantial potential of LLM-based synthetic edits in enhancing the alignment of clinical factuality.
4/19/2024