FIZZ: Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document
2404.11184
0
0

Abstract
Through the advent of pre-trained language models, there have been notable advancements in abstractive summarization systems. Simultaneously, a considerable number of novel methods for evaluating factual consistency in abstractive summarization systems has been developed. But these evaluation approaches incorporate substantial limitations, especially on refinement and interpretability. In this work, we propose highly effective and interpretable factual inconsistency detection method metric Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document for abstractive summarization systems that is based on fine-grained atomic facts decomposition. Moreover, we align atomic facts decomposed from the summary with the source document through adaptive granularity expansion. These atomic facts represent a more fine-grained unit of information, facilitating detailed understanding and interpretability of the summary's factual inconsistency. Experimental results demonstrate that our proposed factual consistency checking system significantly outperforms existing systems.
Create account to get full access
Overview
- This paper introduces FIZZ, a novel approach to detecting factual inconsistencies in text summaries by leveraging a "zoom-in" and "zoom-out" document understanding strategy.
- FIZZ aims to identify discrepancies between the key facts presented in a summary and the broader context and details provided in the original document.
- The proposed method involves generating a concise summary of the document, then cross-checking that summary against the full text to identify any factual inconsistencies.
Plain English Explanation
The researchers developed a system called FIZZ to help identify mistakes or contradictions in automatically generated text summaries. When you summarize a long document, it's easy to miss or misrepresent key facts. FIZZ tries to catch these errors by first creating a short, high-level summary of the document. It then compares this summary back to the original full-length text to see if anything important is missing or inconsistent.
The AMRFACT and Less is More papers have also explored ways to evaluate the factual accuracy of text summaries. The FactCheck and SynFAC projects have developed benchmarks and methods for this task as well. FIZZ builds on this prior work with a novel "zoom-in, zoom-out" approach.
The key idea is that by looking at both the high-level summary and the full document context, FIZZ can more effectively identify factual inconsistencies that might be missed by only examining one or the other. This could help improve the reliability and trustworthiness of automatically generated text summaries, which are increasingly used in a variety of applications.
Technical Explanation
The FIZZ system consists of two main components:
-
Zoom-in Summary: FIZZ first generates a concise summary of the input document using a summarization model. This "zoom-in" summary captures the key facts and high-level information.
-
Zoom-out Document Understanding: FIZZ then compares the summary to the original document text using a language model that can understand the broader context and details. This "zoom-out" component helps identify any factual inconsistencies between the summary and the full document.
The researchers evaluated FIZZ on several benchmark datasets for summarization factual consistency, including BookScore and FactCheck. They found that FIZZ outperformed previous state-of-the-art methods, demonstrating its effectiveness at detecting factual errors in text summaries.
Critical Analysis
The FIZZ paper presents a compelling approach to the important challenge of ensuring the factual accuracy of automatically generated text summaries. By combining a concise "zoom-in" summary with a broader "zoom-out" document understanding, the system appears to be more effective at identifying inconsistencies than prior methods.
However, the authors acknowledge several limitations and areas for future work. For example, the current FIZZ implementation relies on pre-trained language models, which can be biased or make mistakes. Incorporating more robust and transparent fact-checking mechanisms could further improve the system's reliability.
Additionally, the evaluation datasets used in the paper, while valuable, may not fully capture the diverse range of real-world scenarios where factual consistency is crucial. Expanding the testing to a wider variety of domains and applications could help validate the generalizability of FIZZ's performance.
Overall, the FIZZ approach represents an interesting and potentially impactful contribution to the field of summarization factual consistency evaluation. As language models and text generation systems become more advanced, tools like FIZZ will be increasingly important for ensuring the trustworthiness and reliability of automatically produced content.
Conclusion
The FIZZ system introduced in this paper offers a novel "zoom-in, zoom-out" approach to detecting factual inconsistencies in text summaries. By generating a concise summary and then cross-checking it against the broader document context, FIZZ demonstrates improved performance in identifying errors and discrepancies compared to prior methods.
While the current implementation has some limitations, the core ideas behind FIZZ have significant potential to enhance the reliability and trustworthiness of automatically generated summaries, which are becoming increasingly prevalent in a wide range of applications. Further research and refinement of this approach could lead to important advancements in the field of summarization factual consistency evaluation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
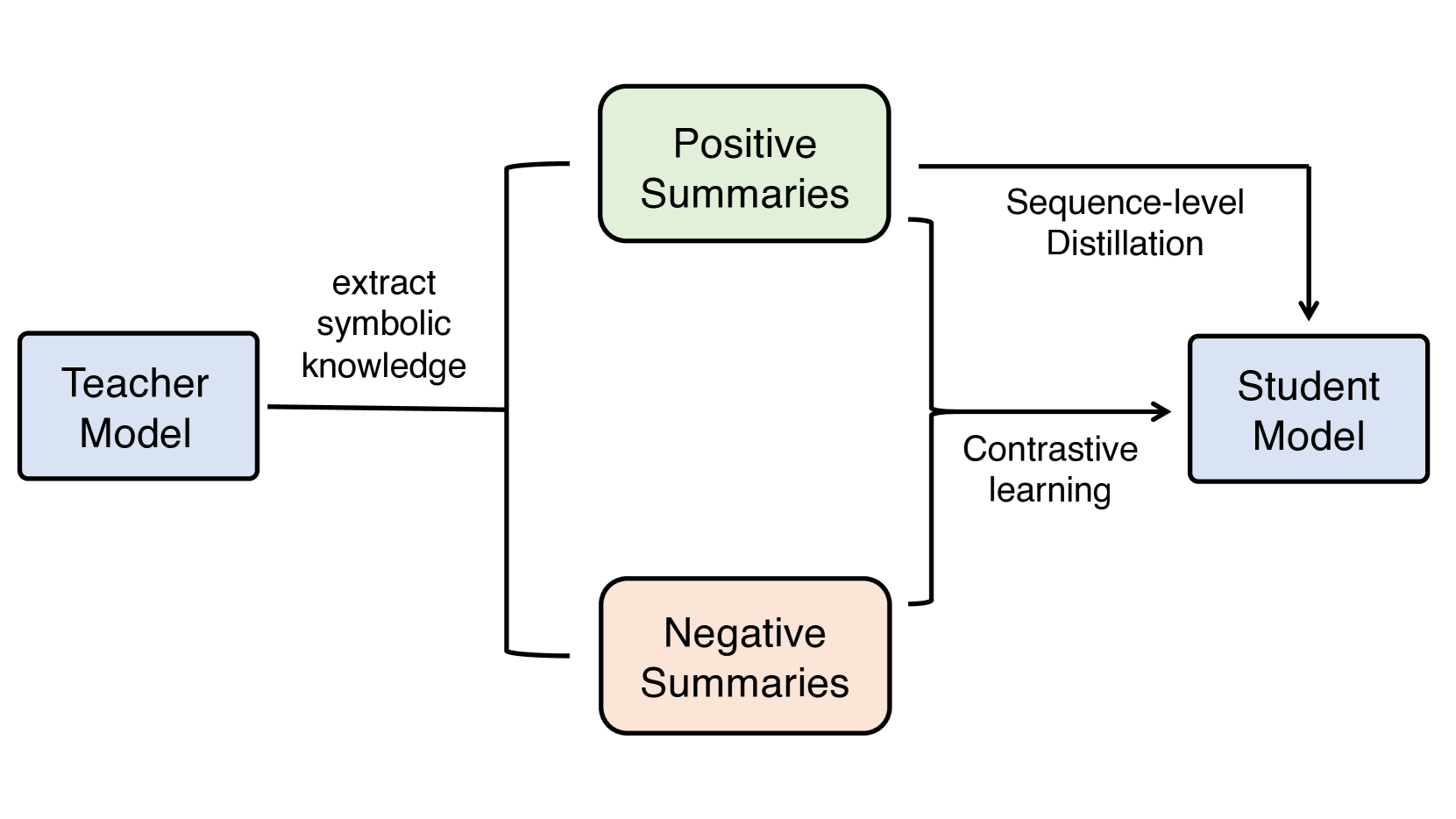
Factual Dialogue Summarization via Learning from Large Language Models
Rongxin Zhu, Jey Han Lau, Jianzhong Qi
0
0
Factual consistency is an important quality in dialogue summarization. Large language model (LLM)-based automatic text summarization models generate more factually consistent summaries compared to those by smaller pretrained language models, but they face deployment challenges in real-world applications due to privacy or resource constraints. In this paper, we investigate the use of symbolic knowledge distillation to improve the factual consistency of smaller pretrained models for dialogue summarization. We employ zero-shot learning to extract symbolic knowledge from LLMs, generating both factually consistent (positive) and inconsistent (negative) summaries. We then apply two contrastive learning objectives on these summaries to enhance smaller summarization models. Experiments with BART, PEGASUS, and Flan-T5 indicate that our approach surpasses strong baselines that rely on complex data augmentation strategies. Our approach achieves better factual consistency while maintaining coherence, fluency, and relevance, as confirmed by various automatic evaluation metrics. We also provide access to the data and code to facilitate future research.
6/24/2024

LongDocFACTScore: Evaluating the Factuality of Long Document Abstractive Summarisation
Jennifer A Bishop, Qianqian Xie, Sophia Ananiadou
0
0
Maintaining factual consistency is a critical issue in abstractive text summarisation, however, it cannot be assessed by traditional automatic metrics used for evaluating text summarisation, such as ROUGE scoring. Recent efforts have been devoted to developing improved metrics for measuring factual consistency using pre-trained language models, but these metrics have restrictive token limits, and are therefore not suitable for evaluating long document text summarisation. Moreover, there is limited research and resources available for evaluating whether existing automatic evaluation metrics are fit for purpose when applied in long document settings. In this work, we evaluate the efficacy of automatic metrics for assessing the factual consistency of long document text summarisation. We create a human-annotated data set for evaluating automatic factuality metrics, LongSciVerify, which contains fine-grained factual consistency annotations for long document summaries from the scientific domain. We also propose a new evaluation framework, LongDocFACTScore, which is suitable for evaluating long document summarisation. This framework allows metrics to be efficiently extended to any length document and outperforms existing state-of-the-art metrics in its ability to correlate with human measures of factuality when used to evaluate long document summarisation data sets. We make our code and LongSciVerify data set publicly available: https://github.com/jbshp/LongDocFACTScore.
5/29/2024

Identifying Factual Inconsistencies in Summaries: Grounding Model Inference via Task Taxonomy
Liyan Xu, Zhenlin Su, Mo Yu, Jin Xu, Jinho D. Choi, Jie Zhou, Fei Liu
0
0
Factual inconsistencies pose a significant hurdle for the faithful summarization by generative models. While a major direction to enhance inconsistency detection is to derive stronger Natural Language Inference (NLI) models, we propose an orthogonal aspect that underscores the importance of incorporating task-specific taxonomy into the inference. To this end, we consolidate key error types of inconsistent facts in summaries, and incorporate them to facilitate both the zero-shot and supervised paradigms of LLMs. Extensive experiments on ten datasets of five distinct domains suggest that, zero-shot LLM inference could benefit from the explicit solution space depicted by the error type taxonomy, and achieves state-of-the-art performance overall, surpassing specialized non-LLM baselines, as well as recent LLM baselines. We further distill models that fuse the taxonomy into parameters through our designed prompt completions and supervised training strategies, efficiently substituting state-of-the-art zero-shot inference with much larger LLMs.
6/21/2024
🛸
AMRFact: Enhancing Summarization Factuality Evaluation with AMR-Driven Negative Samples Generation
Haoyi Qiu, Kung-Hsiang Huang, Jingnong Qu, Nanyun Peng
0
0
Ensuring factual consistency is crucial for natural language generation tasks, particularly in abstractive summarization, where preserving the integrity of information is paramount. Prior works on evaluating factual consistency of summarization often take the entailment-based approaches that first generate perturbed (factual inconsistent) summaries and then train a classifier on the generated data to detect the factually inconsistencies during testing time. However, previous approaches generating perturbed summaries are either of low coherence or lack error-type coverage. To address these issues, we propose AMRFact, a framework that generates perturbed summaries using Abstract Meaning Representations (AMRs). Our approach parses factually consistent summaries into AMR graphs and injects controlled factual inconsistencies to create negative examples, allowing for coherent factually inconsistent summaries to be generated with high error-type coverage. Additionally, we present a data selection module NegFilter based on natural language inference and BARTScore to ensure the quality of the generated negative samples. Experimental results demonstrate our approach significantly outperforms previous systems on the AggreFact-SOTA benchmark, showcasing its efficacy in evaluating factuality of abstractive summarization.
4/4/2024