AMSA-UNet: An Asymmetric Multiple Scales U-net Based on Self-attention for Deblurring

0

Sign in to get full access
Overview
- The paper presents AMSA-UNet, an asymmetric multiple scales U-net model with a self-attention mechanism for image deblurring.
- The model leverages a multi-scale approach and a self-attention mechanism to enhance the deblurring performance.
- The authors claim the AMSA-UNet outperforms state-of-the-art deblurring methods on several benchmark datasets.
Plain English Explanation
AMSA-UNet is a deep learning model designed to remove blur from images. Blur can happen in photos for various reasons, like camera shake or moving objects. Removing blur is important for many applications, like surveillance, medical imaging, and photography.
The key ideas behind AMSA-UNet are:
-
Multi-scale Approach: The model takes the input image and processes it at different scales or resolutions. This allows it to capture details at various levels, from coarse to fine.
-
Self-attention Mechanism: The model uses a self-attention mechanism to help it focus on the most relevant parts of the image when removing the blur. This allows it to better understand the context and structure of the image.
-
Asymmetric Architecture: The model has an asymmetric design, meaning the encoder (downsampling) and decoder (upsampling) parts of the model are not identical. This helps the model process information more efficiently.
By combining these techniques, the AMSA-UNet model is able to achieve state-of-the-art performance in image deblurring, outperforming other methods on standard benchmark datasets. This can be useful for various real-world applications where clear, sharp images are important.
Technical Explanation
The AMSA-UNet model is based on the popular U-Net architecture, which is commonly used for image-to-image translation tasks. However, the authors have introduced several key modifications to improve the deblurring performance.
-
Multi-scale Encoding: The encoder part of the model processes the input image at multiple scales, using a pyramid-like structure. This allows the model to capture details at different resolutions, which is crucial for effective deblurring.
-
Self-attention Mechanism: The model incorporates a self-attention module, which helps it focus on the most relevant regions of the image when removing the blur. This is inspired by the Attention is All You Need paper and similar techniques used in PAM-UNet and MCMS.
-
Asymmetric Decoder: The decoder part of the model has a different structure than the encoder, with additional convolutional layers and skip connections. This asymmetric design helps the model process information more efficiently during the upsampling process.
-
Fast Fourier Transform (FFT): The model also leverages the Fast Fourier Transform to capture the frequency information of the blurred image, which can be useful for deblurring.
The authors evaluate the AMSA-UNet model on several benchmark datasets for image deblurring, including GoPro, HIDE, and RealBlur. They demonstrate that AMSA-UNet outperforms state-of-the-art methods in terms of both quantitative metrics (e.g., PSNR, SSIM) and visual quality.
Critical Analysis
The paper presents a well-designed and effective model for image deblurring, with several innovative techniques that contribute to its strong performance. However, a few points are worth considering:
-
Computational Complexity: The multi-scale and self-attention mechanisms used in AMSA-UNet may increase the computational cost and inference time compared to simpler deblurring models. This could be a limitation for real-time or resource-constrained applications.
-
Generalization Capability: The authors primarily evaluate the model on synthetic and semi-synthetic datasets. It would be valuable to assess its performance on more diverse and challenging real-world deblurring scenarios, which may reveal additional limitations or areas for improvement.
-
Interpretability: While the self-attention mechanism can help the model focus on relevant regions, the inner workings of the model remain somewhat opaque. Providing more insights into how the model makes decisions could enhance its interpretability and understanding.
-
Potential Extensions: The authors mention the possibility of extending the AMSA-UNet architecture to other image restoration tasks, such as super-resolution or inpainting. Exploring these directions could further demonstrate the versatility and broader applicability of the proposed approach.
Conclusion
The AMSA-UNet model presented in this paper represents a significant advancement in image deblurring, leveraging a multi-scale approach and a self-attention mechanism to achieve state-of-the-art performance. The asymmetric design and use of the Fast Fourier Transform further contribute to the model's effectiveness.
While the model may have some computational and interpretability challenges, it showcases the power of combining multiple cutting-edge techniques to tackle a complex image processing task. The insights and ideas presented in this work could inspire further research and development in the field of image restoration and enhancement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AMSA-UNet: An Asymmetric Multiple Scales U-net Based on Self-attention for Deblurring
Yingying Wang
The traditional ingle-scale U-Net often leads to the loss of spatial information during deblurring, which affects the deblurring accracy. Additionally, due to the convolutional method's limitation in capturing long-range dependencies, the quality of the recovered image is degraded. To address the above problems, an asymmetric multiple scales U-net based on self-attention (AMSA-UNet) is proposed to improve the accuracy and computational complexity. By introducing a multiple-scales U shape architecture, the network can focus on blurry regions at the global level and better recover image details at the local level. In order to overcome the limitations of traditional convolutional methods in capturing the long-range dependencies of information, a self-attention mechanism is introduced into the decoder part of the backbone network, which significantly increases the model's receptive field, enabling it to pay more attention to semantic information of the image, thereby producing more accurate and visually pleasing deblurred images. What's more, a frequency domain-based computation method was introduced to reduces the computation amount. The experimental results demonstrate that the proposed method exhibits significant improvements in both accuracy and speed compared to eight excellent methods
Read more6/14/2024
0
AMMUNet: Multi-Scale Attention Map Merging for Remote Sensing Image Segmentation
Yang Yang, Shunyi Zheng
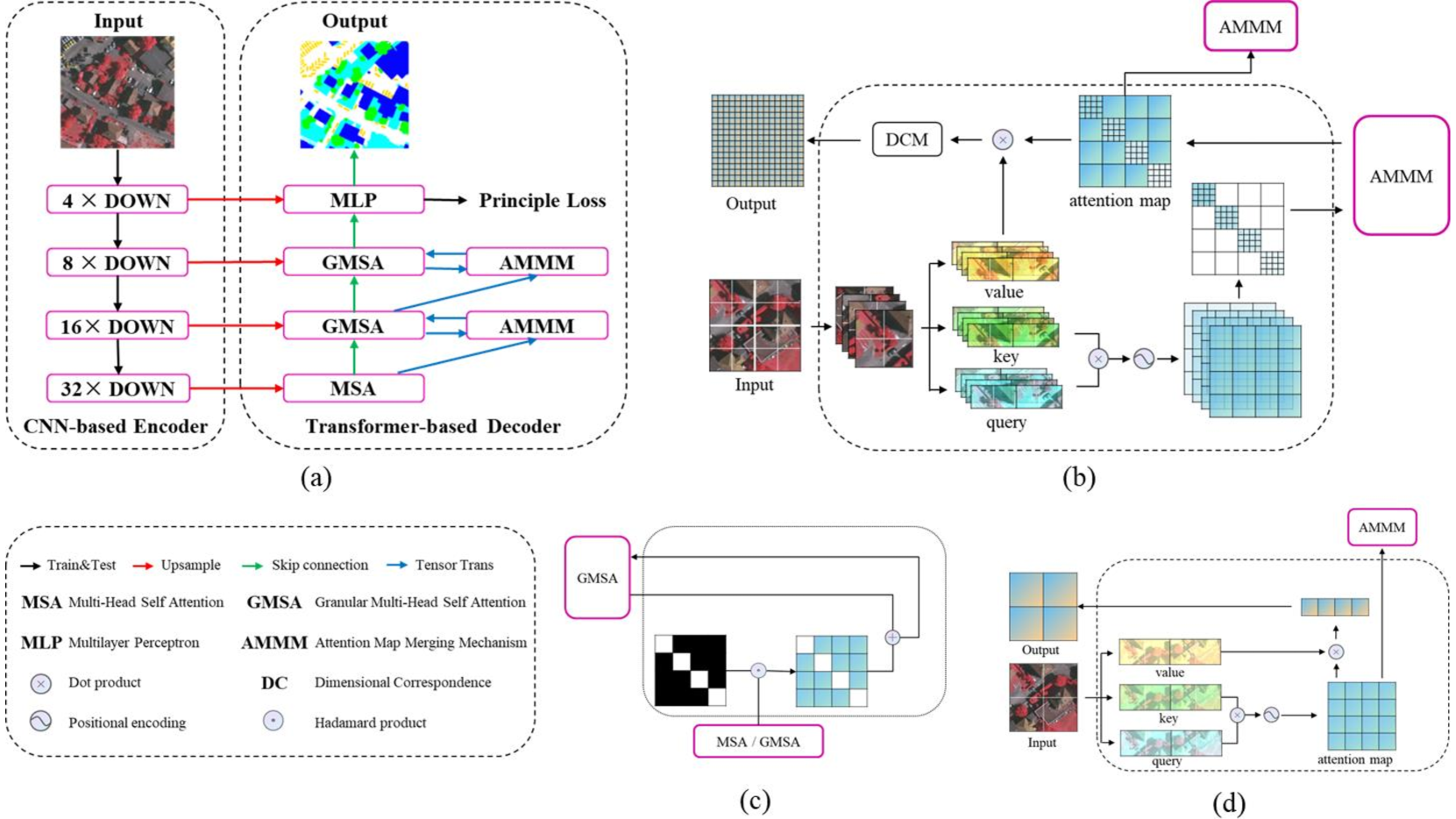
The advancement of deep learning has driven notable progress in remote sensing semantic segmentation. Attention mechanisms, while enabling global modeling and utilizing contextual information, face challenges of high computational costs and require window-based operations that weaken capturing long-range dependencies, hindering their effectiveness for remote sensing image processing. In this letter, we propose AMMUNet, a UNet-based framework that employs multi-scale attention map merging, comprising two key innovations: the granular multi-head self-attention (GMSA) module and the attention map merging mechanism (AMMM). GMSA efficiently acquires global information while substantially mitigating computational costs in contrast to global multi-head self-attention mechanism. This is accomplished through the strategic utilization of dimension correspondence to align granularity and the reduction of relative position bias parameters, thereby optimizing computational efficiency. The proposed AMMM effectively combines multi-scale attention maps into a unified representation using a fixed mask template, enabling the modeling of global attention mechanism. Experimental evaluations highlight the superior performance of our approach, achieving remarkable mean intersection over union (mIoU) scores of 75.48% on the challenging Vaihingen dataset and an exceptional 77.90% on the Potsdam dataset, demonstrating the superiority of our method in precise remote sensing semantic segmentation. Codes are available at https://github.com/interpretty/AMMUNet.
Read more4/23/2024

0
MSA2Net: Multi-scale Adaptive Attention-guided Network for Medical Image Segmentation
Sina Ghorbani Kolahi, Seyed Kamal Chaharsooghi, Toktam Khatibi, Afshin Bozorgpour, Reza Azad, Moein Heidari, Ilker Hacihaliloglu, Dorit Merhof
Medical image segmentation involves identifying and separating object instances in a medical image to delineate various tissues and structures, a task complicated by the significant variations in size, shape, and density of these features. Convolutional neural networks (CNNs) have traditionally been used for this task but have limitations in capturing long-range dependencies. Transformers, equipped with self-attention mechanisms, aim to address this problem. However, in medical image segmentation it is beneficial to merge both local and global features to effectively integrate feature maps across various scales, capturing both detailed features and broader semantic elements for dealing with variations in structures. In this paper, we introduce MSA$^2$Net, a new deep segmentation framework featuring an expedient design of skip-connections. These connections facilitate feature fusion by dynamically weighting and combining coarse-grained encoder features with fine-grained decoder feature maps. Specifically, we propose a Multi-Scale Adaptive Spatial Attention Gate (MASAG), which dynamically adjusts the receptive field (Local and Global contextual information) to ensure that spatially relevant features are selectively highlighted while minimizing background distractions. Extensive evaluations involving dermatology, and radiological datasets demonstrate that our MSA$^2$Net outperforms state-of-the-art (SOTA) works or matches their performance. The source code is publicly available at https://github.com/xmindflow/MSA-2Net.
Read more8/6/2024
0
Haze-Aware Attention Network for Single-Image Dehazing
Lihan Tong, Yun Liu, Weijia Li, Liyuan Chen, Erkang Chen
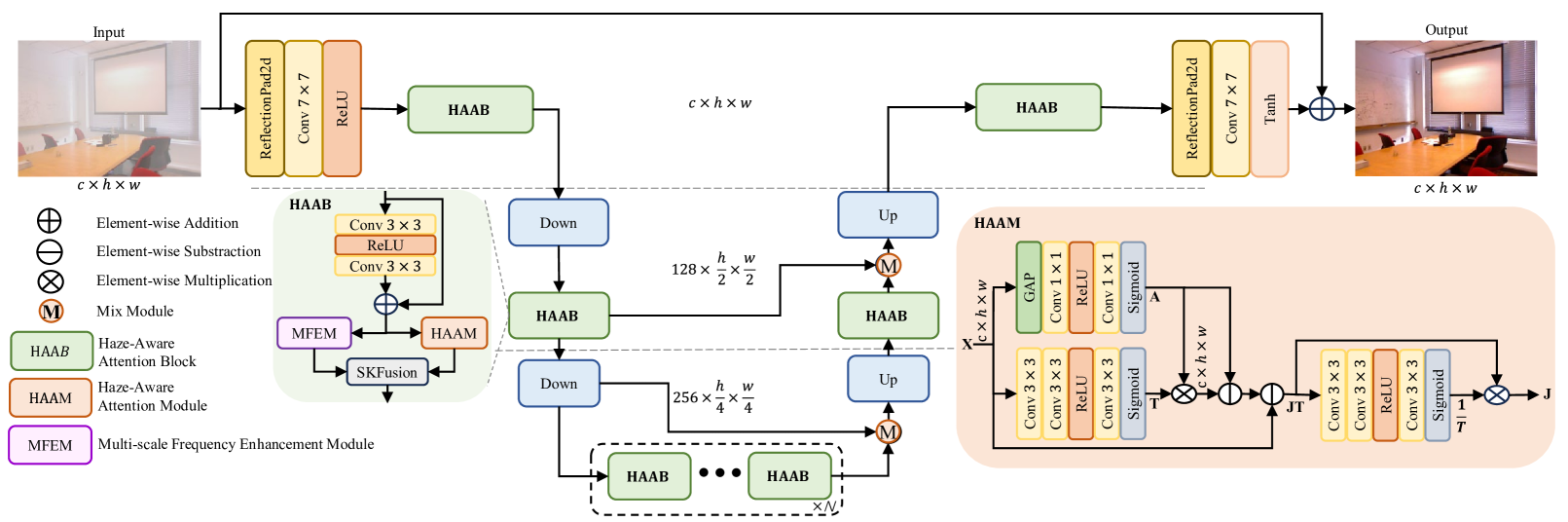
Single-image dehazing is a pivotal challenge in computer vision that seeks to remove haze from images and restore clean background details. Recognizing the limitations of traditional physical model-based methods and the inefficiencies of current attention-based solutions, we propose a new dehazing network combining an innovative Haze-Aware Attention Module (HAAM) with a Multiscale Frequency Enhancement Module (MFEM). The HAAM is inspired by the atmospheric scattering model, thus skillfully integrating physical principles into high-dimensional features for targeted dehazing. It picks up on latent features during the image restoration process, which gives a significant boost to the metrics, while the MFEM efficiently enhances high-frequency details, thus sidestepping wavelet or Fourier transform complexities. It employs multiscale fields to extract and emphasize key frequency components with minimal parameter overhead. Integrated into a simple U-Net framework, our Haze-Aware Attention Network (HAA-Net) for single-image dehazing significantly outperforms existing attention-based and transformer models in efficiency and effectiveness. Tested across various public datasets, the HAA-Net sets new performance benchmarks. Our work not only advances the field of image dehazing but also offers insights into the design of attention mechanisms for broader applications in computer vision.
Read more7/17/2024