Analysing the Behaviour of Tree-Based Neural Networks in Regression Tasks

0

Sign in to get full access
Overview
- This paper analyzes the behavior of tree-based neural networks (TreeNNs) in regression tasks.
- TreeNNs are a type of graph neural network (GNN) that leverage the tree-like structure of data, such as abstract syntax trees (ASTs) or XML documents.
- The researchers investigate the performance and interpretability of TreeNNs compared to other neural network architectures like transformers.
Plain English Explanation
Tree-based neural networks are a special kind of machine learning model that can work well with data that has a tree-like structure, like the code of a computer program or the layout of an XML document. This paper looks at how well these tree-based models perform on regression tasks, which means predicting a numerical value based on input data.
The researchers compare tree-based neural networks to other popular neural network architectures, like transformers, to see which one works better for these kinds of regression problems. They also look at how easy it is to understand and interpret the decisions made by the tree-based models, which is an important consideration when using AI systems in real-world applications.
Overall, the paper provides insights into the strengths and weaknesses of tree-based neural networks and how they compare to other cutting-edge AI techniques, like transformer models and graph neural networks. This can help researchers and developers choose the best tools for their specific machine learning tasks.
Technical Explanation
The paper investigates the performance and interpretability of TreeNNs, a type of graph neural network (GNN) that leverages the tree-like structure of data such as abstract syntax trees (ASTs) or XML documents. The researchers compare TreeNNs to other neural network architectures, including transformers, on regression tasks.
The authors design experiments to evaluate the TreeNN models on a range of regression benchmarks, including tasks related to code understanding and physical system modeling. They analyze the models' predictive accuracy, as well as their interpretability, by examining the importance of different input features in the decision-making process.
The results show that TreeNNs can achieve competitive performance compared to transformer-based models, while also providing better interpretability. The tree-structured inductive bias of TreeNNs appears to be well-suited for tasks that involve hierarchical or compositional relationships in the data.
The paper also discusses potential limitations of TreeNNs, such as their scalability to very large tree-structured inputs and their sensitivity to the quality of the initial tree representations. The authors suggest directions for future research, including exploring hybrid architectures that combine the strengths of TreeNNs and transformers.
Critical Analysis
The paper provides a comprehensive analysis of the behavior of TreeNNs in regression tasks, offering valuable insights for researchers and practitioners working with tree-structured data. The experimental design is thoughtful, and the results are well-presented and discussed.
One potential limitation of the study is the scope of the regression benchmarks used. While the tasks cover a range of domains, including code understanding and physical system modeling, it would be beneficial to expand the evaluation to even more diverse regression problems, such as those encountered in areas like finance, healthcare, or environmental modeling.
Additionally, the paper could have delved deeper into the interpretability analysis, perhaps providing more detailed case studies or visualizations to illustrate how the TreeNN models arrive at their predictions. This could further strengthen the claims about the interpretability advantages of these models.
Overall, the paper makes a strong case for the effectiveness of TreeNNs in regression tasks and highlights their potential as an alternative to transformer-based architectures, especially in domains where the hierarchical structure of the data is a key consideration. The insights presented here could inspire further research into the similarities and differences between various neural network architectures and their suitability for different machine learning problems.
Conclusion
This paper provides a comprehensive analysis of the behavior of tree-based neural networks (TreeNNs) in regression tasks, comparing their performance and interpretability to other neural network architectures like transformers. The results suggest that TreeNNs can be a competitive and interpretable option for machine learning problems involving tree-structured data, such as code or XML documents.
The insights from this research could have important implications for the development of more robust and explainable AI systems, particularly in domains where the hierarchical nature of the data is a key consideration. As the field of machine learning continues to evolve, studies like this one can help guide researchers and practitioners in choosing the most appropriate tools for their specific needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Analysing the Behaviour of Tree-Based Neural Networks in Regression Tasks
Peter Samoaa, Mehrdad Farahani, Antonio Longa, Philipp Leitner, Morteza Haghir Chehreghani
The landscape of deep learning has vastly expanded the frontiers of source code analysis, particularly through the utilization of structural representations such as Abstract Syntax Trees (ASTs). While these methodologies have demonstrated effectiveness in classification tasks, their efficacy in regression applications, such as execution time prediction from source code, remains underexplored. This paper endeavours to decode the behaviour of tree-based neural network models in the context of such regression challenges. We extend the application of established models--tree-based Convolutional Neural Networks (CNNs), Code2Vec, and Transformer-based methods--to predict the execution time of source code by parsing it to an AST. Our comparative analysis reveals that while these models are benchmarks in code representation, they exhibit limitations when tasked with regression. To address these deficiencies, we propose a novel dual-transformer approach that operates on both source code tokens and AST representations, employing cross-attention mechanisms to enhance interpretability between the two domains. Furthermore, we explore the adaptation of Graph Neural Networks (GNNs) to this tree-based problem, theorizing the inherent compatibility due to the graphical nature of ASTs. Empirical evaluations on real-world datasets showcase that our dual-transformer model outperforms all other tree-based neural networks and the GNN-based models. Moreover, our proposed dual transformer demonstrates remarkable adaptability and robust performance across diverse datasets.
Read more6/18/2024

0
AST-T5: Structure-Aware Pretraining for Code Generation and Understanding
Linyuan Gong, Mostafa Elhoushi, Alvin Cheung
Large language models (LLMs) have made significant advancements in code-related tasks, yet many LLMs treat code as simple sequences, neglecting its structured nature. We introduce AST-T5, a novel pretraining paradigm that leverages the Abstract Syntax Tree (AST) for enhanced code generation, transpilation, and understanding. Using dynamic programming, our AST-Aware Segmentation retains code structure, while our AST-Aware Span Corruption objective equips the model to reconstruct various code structures. Unlike other models, AST-T5 avoids intricate program analyses or architectural changes, so it integrates seamlessly with any encoder-decoder Transformer. Evaluations show that AST-T5 consistently outperforms similar-sized LMs across various code-related tasks. Structure-awareness makes AST-T5 particularly powerful in code-to-code tasks, surpassing CodeT5 by 2 points in exact match score for the Bugs2Fix task and by 3 points in exact match score for Java-C# Transpilation in CodeXGLUE. Our code and model are publicly available at https://github.com/gonglinyuan/ast_t5.
Read more6/26/2024
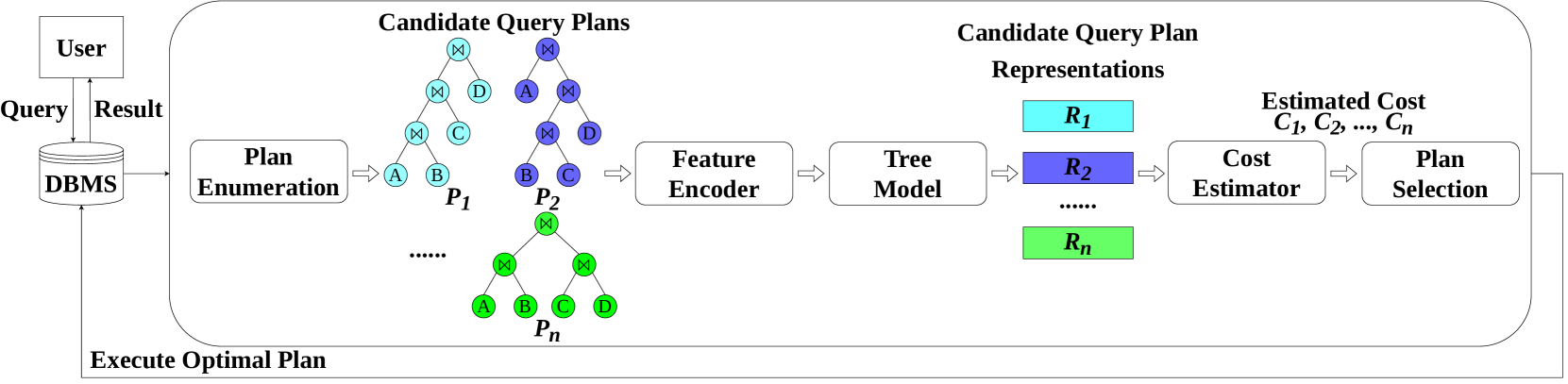
0
A Novel Technique for Query Plan Representation Based on Graph Neural Networks
Baoming Chang, Amin Kamali, Verena Kantere
Learning representations for query plans play a pivotal role in machine learning-based query optimizers of database management systems. To this end, particular model architectures are proposed in the literature to transform the tree-structured query plans into representations with formats learnable by downstream machine learning models. However, existing research rarely compares and analyzes the query plan representation capabilities of these tree models and their direct impact on the performance of the overall optimizer. To address this problem, we perform a comparative study to explore the effect of using different state-of-the-art tree models on the optimizer's cost estimation and plan selection performance in relatively complex workloads. Additionally, we explore the possibility of using graph neural networks (GNNs) in the query plan representation task. We propose a novel tree model BiGG employing Bidirectional GNN aggregated by Gated recurrent units (GRUs) and demonstrate experimentally that BiGG provides significant improvements to cost estimation tasks and relatively excellent plan selection performance compared to the state-of-the-art tree models.
Read more6/6/2024

0
Retrofitting Temporal Graph Neural Networks with Transformer
Qiang Huang, Xiao Yan, Xin Wang, Susie Xi Rao, Zhichao Han, Fangcheng Fu, Wentao Zhang, Jiawei Jiang
Temporal graph neural networks (TGNNs) outperform regular GNNs by incorporating time information into graph-based operations. However, TGNNs adopt specialized models (e.g., TGN, TGAT, and APAN ) and require tailored training frameworks (e.g., TGL and ETC). In this paper, we propose TF-TGN, which uses Transformer decoder as the backbone model for TGNN to enjoy Transformer's codebase for efficient training. In particular, Transformer achieves tremendous success for language modeling, and thus the community developed high-performance kernels (e.g., flash-attention and memory-efficient attention) and efficient distributed training schemes (e.g., PyTorch FSDP, DeepSpeed, and Megatron-LM). We observe that TGNN resembles language modeling, i.e., the message aggregation operation between chronologically occurring nodes and their temporal neighbors in TGNNs can be structured as sequence modeling. Beside this similarity, we also incorporate a series of algorithm designs including suffix infilling, temporal graph attention with self-loop, and causal masking self-attention to make TF-TGN work. During training, existing systems are slow in transforming the graph topology and conducting graph sampling. As such, we propose methods to parallelize the CSR format conversion and graph sampling. We also adapt Transformer codebase to train TF-TGN efficiently with multiple GPUs. We experiment with 9 graphs and compare with 2 state-of-the-art TGNN training frameworks. The results show that TF-TGN can accelerate training by over 2.20 while providing comparable or even superior accuracy to existing SOTA TGNNs. TF-TGN is available at https://github.com/qianghuangwhu/TF-TGN.
Read more9/11/2024