Analysis of Distributed Algorithms for Big-data
2404.06461
0
0
Abstract
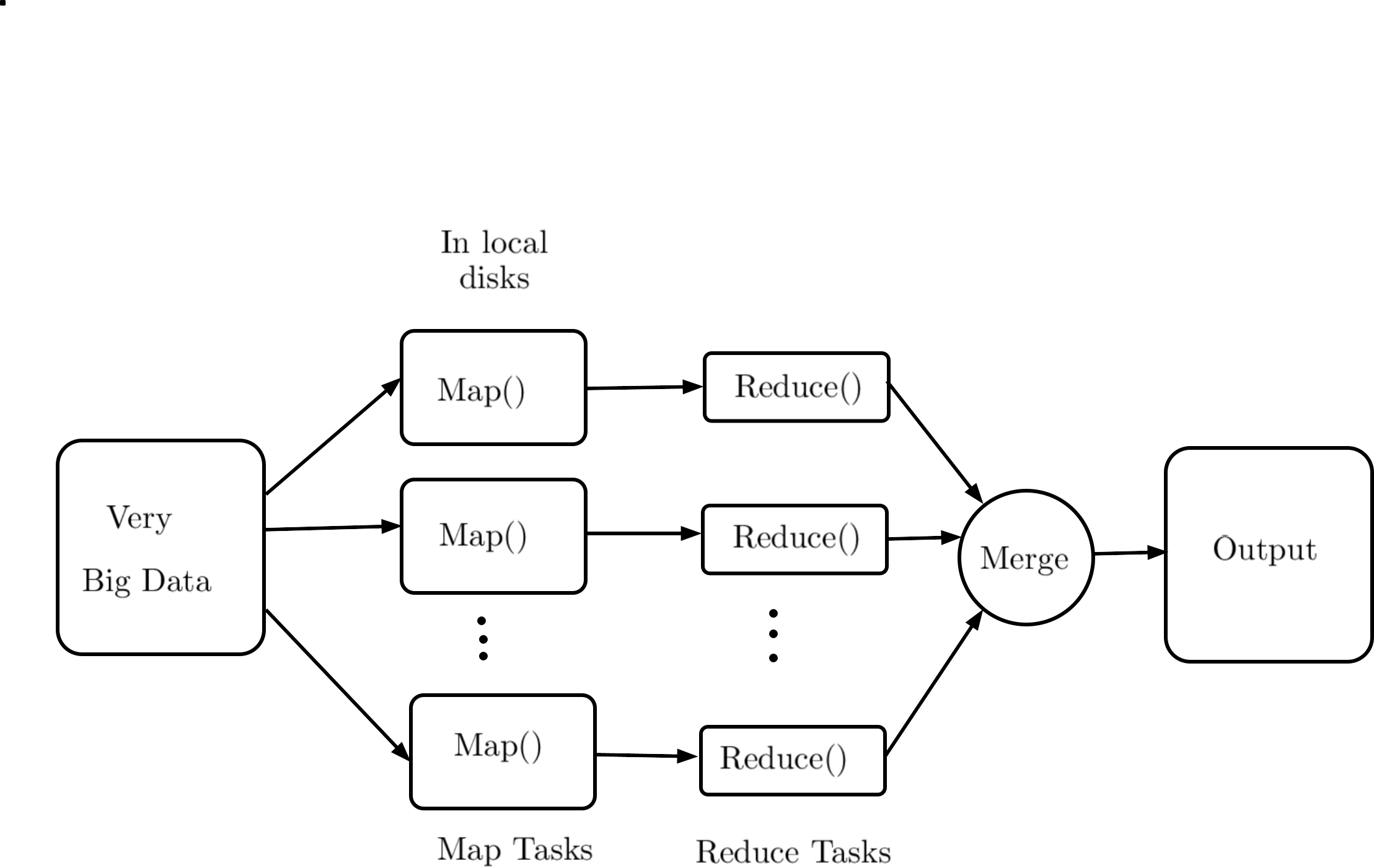
The parallel and distributed processing are becoming de facto industry standard, and a large part of the current research is targeted on how to make computing scalable and distributed, dynamically, without allocating the resources on permanent basis. The present article focuses on the study and performance of distributed and parallel algorithms their file systems, to achieve scalability at local level (OpenMP platform), and at global level where computing and file systems are distributed. Various applications, algorithms,file systems have been used to demonstrate the areas, and their performance studies have been presented. The systems and applications chosen here are of open-source nature, due to their wider applicability.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Examines distributed algorithms for processing large-scale "big data"
- Covers key distributed processing frameworks like MapReduce and OpenMP
- Analyzes performance and scalability of distributed algorithms for big data applications
Plain English Explanation
This research paper looks at different algorithms and methods for processing and analyzing very large datasets, often referred to as "big data." Big data can come from a variety of sources, like social media, scientific research, or business operations, and it is often too large and complex for a single computer to handle.
The paper explores how to divide up and distribute this big data across multiple computers or processing nodes, so the work can be done in parallel. This is known as distributed processing. The researchers evaluate the performance and scalability of various distributed algorithms and frameworks, like MapReduce and OpenMP.
The goal is to understand which techniques work best for processing big data efficiently and reliably, across a large number of computers. This is an important area of research as the volume of data being generated continues to grow exponentially, and organizations need effective ways to extract insights and value from it.
Technical Explanation
The paper begins by providing an overview of distributed algorithms and how they can be used to tackle big data challenges. It discusses key concepts like data partitioning, load balancing, and fault tolerance.
The researchers then dive into an analysis of two widely-used distributed processing frameworks - MapReduce and OpenMP. They examine the architectural details of each system, including how they divide up data and coordinate computations across multiple nodes. Experiments are conducted to measure the performance and scalability of these frameworks as the size of the dataset increases.
The results show that both MapReduce and OpenMP can effectively parallelize big data workloads, but their relative strengths depend on factors like data access patterns and the nature of the computations. For example, MapReduce may be better suited for batch processing, while OpenMP can excel at shared-memory, iterative algorithms.
Critical Analysis
The paper provides a thorough technical analysis of distributed algorithms and frameworks for big data processing. However, it does acknowledge some key limitations and areas for future research.
For instance, the experiments were conducted on relatively homogeneous clusters of computers. The researchers note that real-world big data deployments often involve more heterogeneous and dynamic environments, which can introduce additional challenges around load balancing and fault tolerance.
Additionally, the paper focuses mainly on batch processing scenarios. It does not extensively explore how these distributed algorithms might perform in more interactive, streaming data use cases, which are becoming increasingly common.
Further research could also investigate hybrid approaches that combine the strengths of different distributed computing paradigms, or ways to automatically select the most appropriate framework based on the characteristics of the data and workload.
Conclusion
This research paper offers a detailed examination of distributed algorithms and frameworks for processing large-scale big data. It provides valuable insights into the performance and scalability tradeoffs of popular systems like MapReduce and OpenMP.
The findings suggest that distributed processing is a critical enabler for extracting value from the ever-growing volumes of data being generated. However, there is still room for improvement in terms of handling more diverse and dynamic big data environments. Ongoing research in this area will help organizations develop more robust and efficient big data solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Survey of Distributed Graph Algorithms on Massive Graphs
Lingkai Meng, Yu Shao, Long Yuan, Longbin Lai, Peng Cheng, Xue Li, Wenyuan Yu, Wenjie Zhang, Xuemin Lin, Jingren Zhou
0
0
Distributed processing of large-scale graph data has many practical applications and has been widely studied. In recent years, a lot of distributed graph processing frameworks and algorithms have been proposed. While many efforts have been devoted to analyzing these, with most analyzing them based on programming models, less research focuses on understanding their challenges in distributed environments. Applying graph tasks to distributed environments is not easy, often facing numerous challenges through our analysis, including parallelism, load balancing, communication overhead, and bandwidth. In this paper, we provide an extensive overview of the current state-of-the-art in this field by outlining the challenges and solutions of distributed graph algorithms. We first conduct a systematic analysis of the inherent challenges in distributed graph processing, followed by presenting an overview of existing general solutions. Subsequently, we survey the challenges highlighted in recent distributed graph processing papers and the strategies adopted to address them. Finally, we discuss the current research trends and identify potential future opportunities.
4/10/2024
Efficient Distributed Data Structures for Future Many-core Architectures
Panagiota Fatourou, Nikolaos D. Kallimanis, Eleni Kanellou, Odysseas Makridakis, Christi Symeonidou
0
0
We study general techniques for implementing distributed data structures on top of future many-core architectures with non cache-coherent or partially cache-coherent memory. With the goal of contributing towards what might become, in the future, the concurrency utilities package in Java collections for such architectures, we end up with a comprehensive collection of data structures by considering different variants of these techniques. To achieve scalability, we study a generic scheme which makes all our implementations hierarchical. We consider a collection of known techniques for improving the scalability of concurrent data structures and we adjust them to work in our setting. We have performed experiments which illustrate that some of these techniques have indeed high impact on achieving scalability. Our experiments also reveal the performance and scalability power of the hierarchical approach. We finally present experiments to study energy consumption aspects of the proposed techniques by using an energy model recently proposed for such architectures.
4/9/2024
👁️
Scheduling of Distributed Applications on the Computing Continuum: A Survey
Narges Mehran, Dragi Kimovski, Hermann Hellwagner, Dumitru Roman, Ahmet Soylu, Radu Prodan
0
0
The demand for distributed applications has significantly increased over the past decade, with improvements in machine learning techniques fueling this growth. These applications predominantly utilize Cloud data centers for high-performance computing and Fog and Edge devices for low-latency communication for small-size machine learning model training and inference. The challenge of executing applications with different requirements on heterogeneous devices requires effective methods for solving NP-hard resource allocation and application scheduling problems. The state-of-the-art techniques primarily investigate conflicting objectives, such as the completion time, energy consumption, and economic cost of application execution on the Cloud, Fog, and Edge computing infrastructure. Therefore, in this work, we review these research works considering their objectives, methods, and evaluation tools. Based on the review, we provide a discussion on the scheduling methods in the Computing Continuum.
5/2/2024
I/O in Machine Learning Applications on HPC Systems: A 360-degree Survey
Noah Lewis, Jean Luca Bez, Suren Byna
0
0
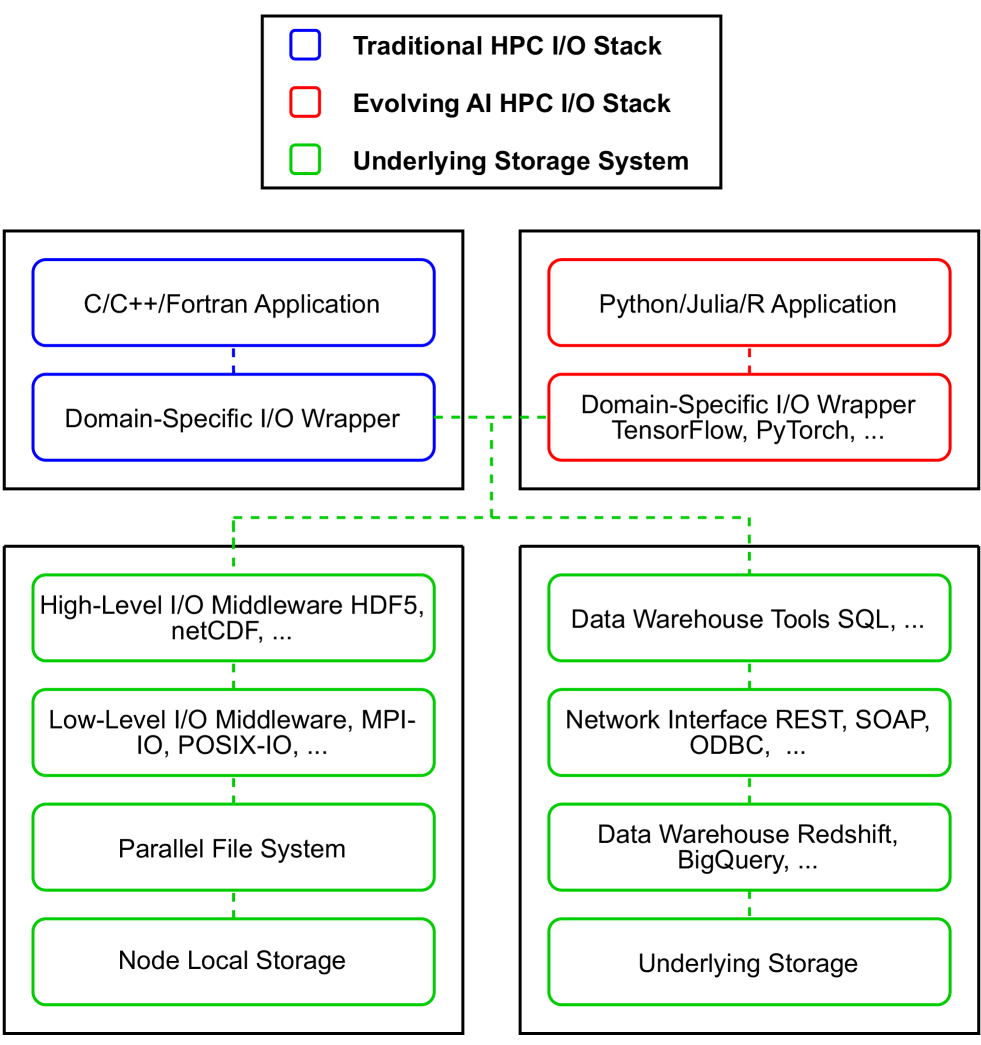
High-Performance Computing (HPC) systems excel in managing distributed workloads, and the growing interest in Artificial Intelligence (AI) has resulted in a surge in demand for faster methods of Machine Learning (ML) model training and inference. In the past, research on HPC I/O focused on optimizing the underlying storage system for modeling and simulation applications and checkpointing the results, causing writes to be the dominant I/O operation. These applications typically access large portions of the data written by simulations or experiments. ML workloads, in contrast, perform small I/O reads spread across a large number of random files. This shift of I/O access patterns poses several challenges to HPC storage systems. In this paper, we survey I/O in ML applications on HPC systems, and target literature within a 6-year time window from 2019 to 2024. We provide an overview of the common phases of ML, review available profilers and benchmarks, examine the I/O patterns encountered during ML training, explore I/O optimizations utilized in modern ML frameworks and proposed in recent literature, and lastly, present gaps requiring further R&D. We seek to summarize the common practices used in accessing data by ML applications and expose research gaps that could spawn further R&D.
4/17/2024