Analysis of Systems' Performance in Natural Language Processing Competitions

0

Sign in to get full access
Overview
- Analyzed the performance of natural language processing systems in major competitions
- Focused on the VaxxStance 2021 competition for multiclass textual classification
- Examined how systems performed across different tasks and datasets
Plain English Explanation
This research paper takes a close look at how well natural language processing (NLP) systems perform in major competitions. The researchers focused on the VaxxStance 2021 competition, which asked systems to classify text into different categories related to vaccine stances.
[A brief explanation of the VaxxStance 2021 competition and its goals]
The researchers wanted to understand how the competing systems handled this classification task across different datasets. They analyzed the systems' performance to gain insights into the strengths and limitations of current NLP technologies.
Technical Explanation
[A more detailed summary of the key elements of the research, including:]
- The specific competitions analyzed in the study, including VaxxStance 2021
- The experimental design and methodology used to evaluate the systems' performance
- The architectural details and approaches taken by the top-performing systems
- The insights gained from the performance analysis, such as which techniques worked well and where there is room for improvement
Critical Analysis
[A discussion of the caveats, limitations, and areas for further research mentioned in the paper, as well as any additional concerns or potential issues the researcher may raise, such as:]
- The potential biases or limitations of the datasets used in the competitions
- The challenges of generalizing the findings to real-world NLP applications
- The need for more diverse and representative evaluation benchmarks
- The importance of considering ethical implications in the development of NLP systems
Conclusion
[A summary of the main takeaways from the research and their potential implications for the field of NLP and society at large, such as:]
- The insights gained into the current capabilities and limitations of NLP systems
- The need for continued advancement and responsible development of NLP technologies
- The potential applications and societal impact of improved natural language processing
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Analysis of Systems' Performance in Natural Language Processing Competitions
Sergio Nava-Mu~noz, Mario Graff, Hugo Jair Escalante
Collaborative competitions have gained popularity in the scientific and technological fields. These competitions involve defining tasks, selecting evaluation scores, and devising result verification methods. In the standard scenario, participants receive a training set and are expected to provide a solution for a held-out dataset kept by organizers. An essential challenge for organizers arises when comparing algorithms' performance, assessing multiple participants, and ranking them. Statistical tools are often used for this purpose; however, traditional statistical methods often fail to capture decisive differences between systems' performance. This manuscript describes an evaluation methodology for statistically analyzing competition results and competition. The methodology is designed to be universally applicable; however, it is illustrated using eight natural language competitions as case studies involving classification and regression problems. The proposed methodology offers several advantages, including off-the-shell comparisons with correction mechanisms and the inclusion of confidence intervals. Furthermore, we introduce metrics that allow organizers to assess the difficulty of competitions. Our analysis shows the potential usefulness of our methodology for effectively evaluating competition results.
Read more8/22/2024
🤖
0
Investigating a Benchmark for Training-set free Evaluation of Linguistic Capabilities in Machine Reading Comprehension
Viktor Schlegel, Goran Nenadic, Riza Batista-Navarro
Performance of NLP systems is typically evaluated by collecting a large-scale dataset by means of crowd-sourcing to train a data-driven model and evaluate it on a held-out portion of the data. This approach has been shown to suffer from spurious correlations and the lack of challenging examples that represent the diversity of natural language. Instead, we examine a framework for evaluating optimised models in training-set free setting on synthetically generated challenge sets. We find that despite the simplicity of the generation method, the data can compete with crowd-sourced datasets with regard to naturalness and lexical diversity for the purpose of evaluating the linguistic capabilities of MRC models. We conduct further experiments and show that state-of-the-art language model-based MRC systems can learn to succeed on the challenge set correctly, although, without capturing the general notion of the evaluated phenomenon.
Read more8/12/2024

0
Beyond Metrics: A Critical Analysis of the Variability in Large Language Model Evaluation Frameworks
Marco AF Pimentel, Cl'ement Christophe, Tathagata Raha, Prateek Munjal, Praveen K Kanithi, Shadab Khan
As large language models (LLMs) continue to evolve, the need for robust and standardized evaluation benchmarks becomes paramount. Evaluating the performance of these models is a complex challenge that requires careful consideration of various linguistic tasks, model architectures, and benchmarking methodologies. In recent years, various frameworks have emerged as noteworthy contributions to the field, offering comprehensive evaluation tests and benchmarks for assessing the capabilities of LLMs across diverse domains. This paper provides an exploration and critical analysis of some of these evaluation methodologies, shedding light on their strengths, limitations, and impact on advancing the state-of-the-art in natural language processing.
Read more8/1/2024
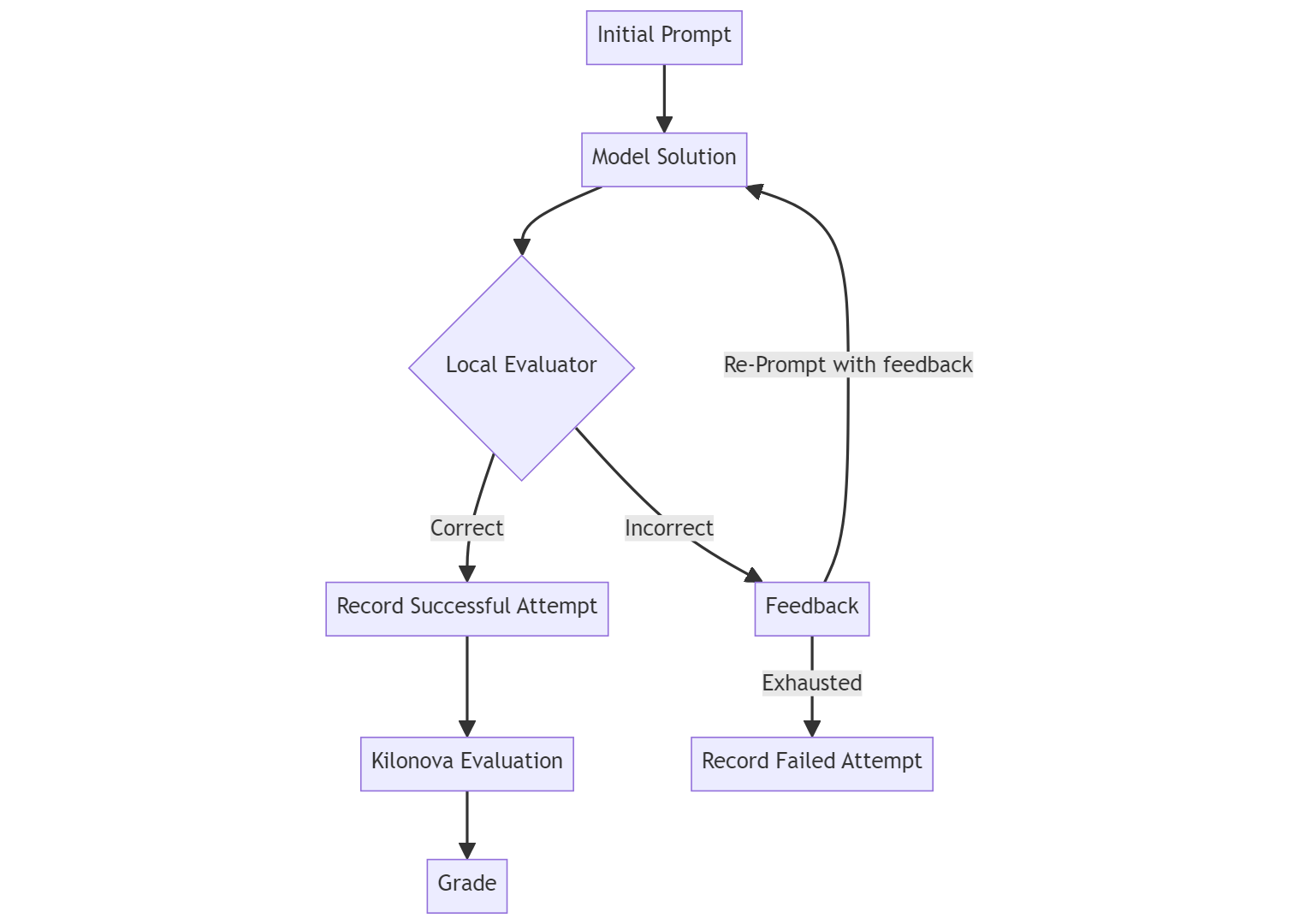
0
New!Evaluating the Performance of Large Language Models in Competitive Programming: A Multi-Year, Multi-Grade Analysis
Adrian Marius Dumitran, Adrian Catalin Badea, Stefan-Gabriel Muscalu
This study explores the performance of large language models (LLMs) in solving competitive programming problems from the Romanian Informatics Olympiad at the county level. Romania, a leading nation in computer science competitions, provides an ideal environment for evaluating LLM capabilities due to its rich history and stringent competition standards. We collected and analyzed a dataset comprising 304 challenges from 2002 to 2023, focusing on solutions written by LLMs in C++ and Python for these problems. Our primary goal is to understand why LLMs perform well or poorly on different tasks. We evaluated various models, including closed-source models like GPT-4 and open-weight models such as CodeLlama and RoMistral, using a standardized process involving multiple attempts and feedback rounds. The analysis revealed significant variations in LLM performance across different grades and problem types. Notably, GPT-4 showed strong performance, indicating its potential use as an educational tool for middle school students. We also observed differences in code quality and style across various LLMs
Read more9/17/2024