Evaluating the Performance of Large Language Models in Competitive Programming: A Multi-Year, Multi-Grade Analysis

0
Sign in to get full access
Overview
- This paper evaluates the performance of Large Language Models (LLMs) in competitive programming contests.
- The study analyzes LLM performance across multiple years and grade levels of the International Olympiad in Informatics (IOI) competition.
- The researchers assess the ability of LLMs to generate and evaluate code for programming problems at the high school and university level.
Plain English Explanation
The paper investigates how well Large Language Models (LLMs) perform on programming tasks that are commonly used in competitive coding competitions. The researchers looked at the International Olympiad in Informatics (IOI), which is a prestigious high school programming competition, as well as university-level programming challenges.
The goal was to see if these powerful AI language models could generate and evaluate code at the level of human experts in competitive programming. This is an important question as AI systems become more advanced and may start to outperform humans on certain programming tasks.
By testing the LLMs on problems from multiple years and grade levels, the researchers were able to get a comprehensive assessment of the models' programming abilities. This provides insights into how well these AI systems can tackle advanced, real-world programming challenges.
Technical Explanation
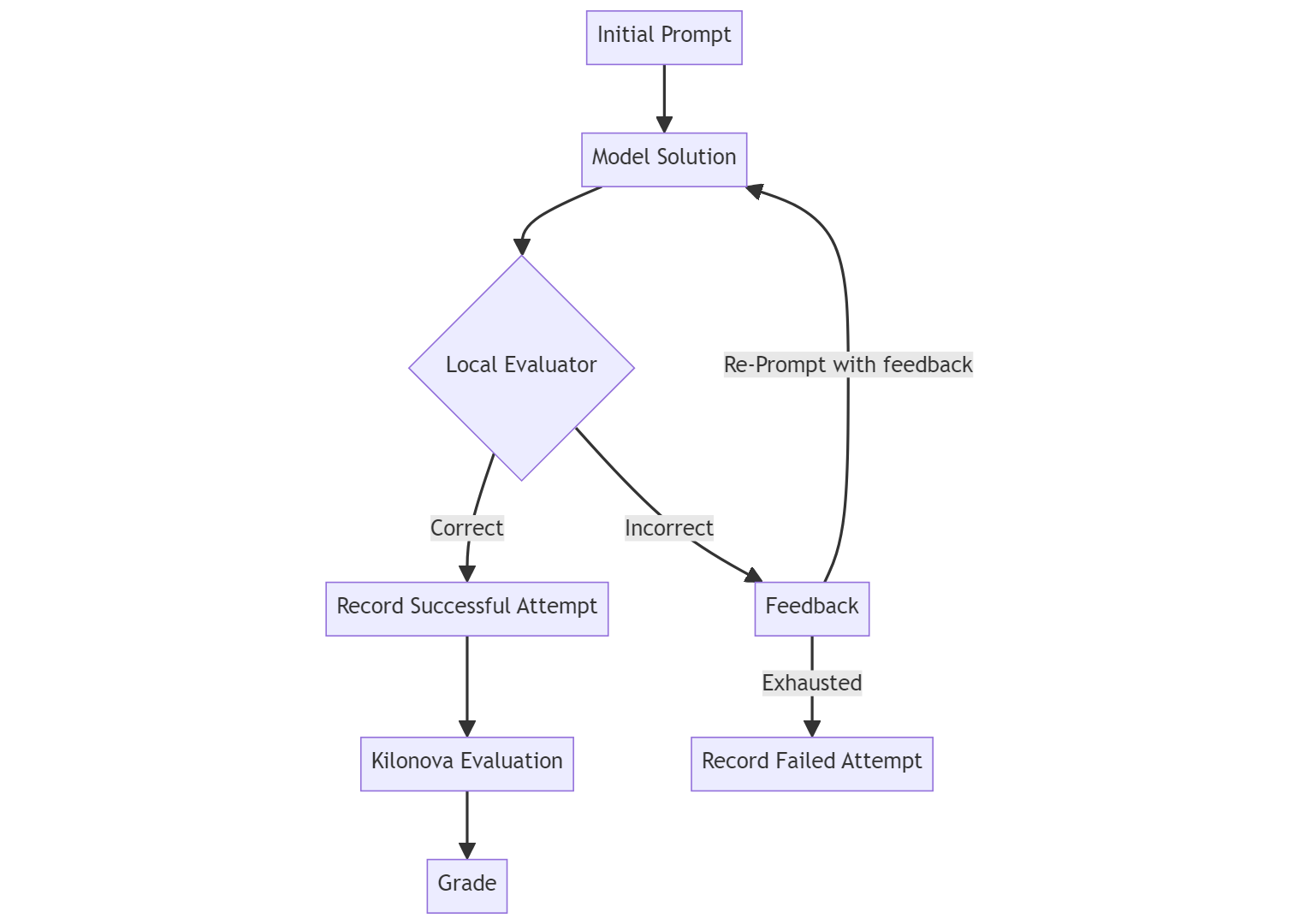
The researchers evaluated the performance of several prominent Large Language Models (LLMs) on programming problems from the International Olympiad in Informatics (IOI), a prestigious high school-level coding competition, as well as university-level programming challenges.
The LLMs were tasked with both generating and evaluating code for these problems, which tested their ability to understand programming concepts, algorithms, and syntax at a high level. The models' performance was assessed across multiple years and grade levels to provide a comprehensive evaluation of their programming skills.
The results show that the LLMs were able to achieve strong performance on the IOI and university-level problems, demonstrating their potential to outperform humans on certain programming tasks. However, the researchers also identified some limitations and areas for further improvement, such as the models' struggles with edge cases and their need for more training data on advanced programming concepts.
Critical Analysis
The study provides a thorough and rigorous evaluation of LLM performance on competitive programming tasks, which is an important step in understanding the capabilities and limitations of these AI systems. The multi-year, multi-grade analysis helps to paint a comprehensive picture of the models' abilities.
However, the researchers acknowledge that their study has some limitations. For example, the LLMs were only tested on a relatively small set of problems from the IOI and university competitions, and their performance may not generalize to a wider range of programming challenges. Additionally, the researchers did not directly compare the LLMs to human experts, which would provide more context for interpreting the models' performance.
Furthermore, the study does not delve into the potential societal implications of AI systems outperforming humans on programming tasks. As these models become more advanced, there may be concerns about their impact on the job market and the education system. The researchers could have explored these issues in more depth.
Overall, this paper makes a valuable contribution to the understanding of LLM capabilities in the context of competitive programming. However, further research is needed to fully assess the implications of these findings and to explore the broader impacts of AI in this domain.
Conclusion
This study provides a comprehensive evaluation of Large Language Models' (LLMs) performance on competitive programming tasks, including both code generation and evaluation. The researchers tested the models on problems from the International Olympiad in Informatics (IOI) and university-level programming challenges, and found that the LLMs were able to achieve strong results across multiple years and grade levels.
These findings suggest that AI systems may be able to outperform humans on certain programming tasks, which has important implications for the future of the technology industry and education. However, the researchers also identified limitations in the models' performance, such as their struggles with edge cases and the need for more advanced training data.
Overall, this paper provides valuable insights into the current state of LLM capabilities in the domain of competitive programming, and highlights the need for further research to fully understand the implications of these AI systems in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Evaluating the Performance of Large Language Models in Competitive Programming: A Multi-Year, Multi-Grade Analysis
Adrian Marius Dumitran, Adrian Catalin Badea, Stefan-Gabriel Muscalu
This study explores the performance of large language models (LLMs) in solving competitive programming problems from the Romanian Informatics Olympiad at the county level. Romania, a leading nation in computer science competitions, provides an ideal environment for evaluating LLM capabilities due to its rich history and stringent competition standards. We collected and analyzed a dataset comprising 304 challenges from 2002 to 2023, focusing on solutions written by LLMs in C++ and Python for these problems. Our primary goal is to understand why LLMs perform well or poorly on different tasks. We evaluated various models, including closed-source models like GPT-4 and open-weight models such as CodeLlama and RoMistral, using a standardized process involving multiple attempts and feedback rounds. The analysis revealed significant variations in LLM performance across different grades and problem types. Notably, GPT-4 showed strong performance, indicating its potential use as an educational tool for middle school students. We also observed differences in code quality and style across various LLMs
Read more9/17/2024
💬
0
Evaluating Language Models for Generating and Judging Programming Feedback
Charles Koutcheme, Nicola Dainese, Arto Hellas, Sami Sarsa, Juho Leinonen, Syed Ashraf, Paul Denny
The emergence of large language models (LLMs) has transformed research and practice in a wide range of domains. Within the computing education research (CER) domain, LLMs have received plenty of attention especially in the context of learning programming. Much of the work on LLMs in CER has however focused on applying and evaluating proprietary models. In this article, we evaluate the efficiency of open-source LLMs in generating high-quality feedback for programming assignments, and in judging the quality of the programming feedback, contrasting the results against proprietary models. Our evaluations on a dataset of students' submissions to Python introductory programming exercises suggest that the state-of-the-art open-source LLMs (Meta's Llama3) are almost on-par with proprietary models (GPT-4o) in both the generation and assessment of programming feedback. We further demonstrate the efficiency of smaller LLMs in the tasks, and highlight that there are a wide range of LLMs that are accessible even for free for educators and practitioners.
Read more7/9/2024
📉
0
Competition-Level Problems are Effective LLM Evaluators
Yiming Huang, Zhenghao Lin, Xiao Liu, Yeyun Gong, Shuai Lu, Fangyu Lei, Yaobo Liang, Yelong Shen, Chen Lin, Nan Duan, Weizhu Chen
Large language models (LLMs) have demonstrated impressive reasoning capabilities, yet there is ongoing debate about these abilities and the potential data contamination problem recently. This paper aims to evaluate the reasoning capacities of LLMs, specifically in solving recent competition-level programming problems in Codeforces, which are expert-crafted and unique, requiring deep understanding and robust reasoning skills. We first provide a comprehensive evaluation of GPT-4's peiceived zero-shot performance on this task, considering various aspects such as problems' release time, difficulties, and types of errors encountered. Surprisingly, the peiceived performance of GPT-4 has experienced a cliff like decline in problems after September 2021 consistently across all the difficulties and types of problems, which shows the potential data contamination, as well as the challenges for any existing LLM to solve unseen complex reasoning problems. We further explore various approaches such as fine-tuning, Chain-of-Thought prompting and problem description simplification, unfortunately none of them is able to consistently mitigate the challenges. Through our work, we emphasis the importance of this excellent data source for assessing the genuine reasoning capabilities of LLMs, and foster the development of LLMs with stronger reasoning abilities and better generalization in the future.
Read more6/5/2024
💬
2
Evaluation of the Programming Skills of Large Language Models
Luc Bryan Heitz, Joun Chamas, Christopher Scherb
The advent of Large Language Models (LLM) has revolutionized the efficiency and speed with which tasks are completed, marking a significant leap in productivity through technological innovation. As these chatbots tackle increasingly complex tasks, the challenge of assessing the quality of their outputs has become paramount. This paper critically examines the output quality of two leading LLMs, OpenAI's ChatGPT and Google's Gemini AI, by comparing the quality of programming code generated in both their free versions. Through the lens of a real-world example coupled with a systematic dataset, we investigate the code quality produced by these LLMs. Given their notable proficiency in code generation, this aspect of chatbot capability presents a particularly compelling area for analysis. Furthermore, the complexity of programming code often escalates to levels where its verification becomes a formidable task, underscoring the importance of our study. This research aims to shed light on the efficacy and reliability of LLMs in generating high-quality programming code, an endeavor that has significant implications for the field of software development and beyond.
Read more5/24/2024