Analytical Uncertainty-Based Loss Weighting in Multi-Task Learning

0
Sign in to get full access
Overview
- Explores an approach for weighting the losses in multi-task learning based on analytical uncertainty
- Aims to address challenges in balancing the training of different tasks in multi-task learning
- Proposes a loss weighting scheme that dynamically adjusts the contribution of each task's loss during training
Plain English Explanation
In machine learning, there are often situations where a single model needs to perform multiple related tasks, like classifying images and detecting objects in those images. This is known as multi-task learning. A key challenge in multi-task learning is how to balance the training of the different tasks so that the model performs well on all of them.
The paper introduces a new approach called Analytical Uncertainty-Based Loss Weighting that aims to address this challenge. The core idea is to dynamically adjust the importance, or weight, of each task's loss during training based on an analytical estimate of the uncertainty associated with that task.
The intuition is that tasks with higher uncertainty should be given more weight during training, as the model has more room for improvement on those tasks. Conversely, tasks with lower uncertainty should be given less weight, as the model is already performing well on those tasks.
By adjusting the loss weights in this way, the approach is designed to help the model learn a balanced representation that performs well across all the tasks, rather than specializing too much on some tasks at the expense of others.
Technical Explanation
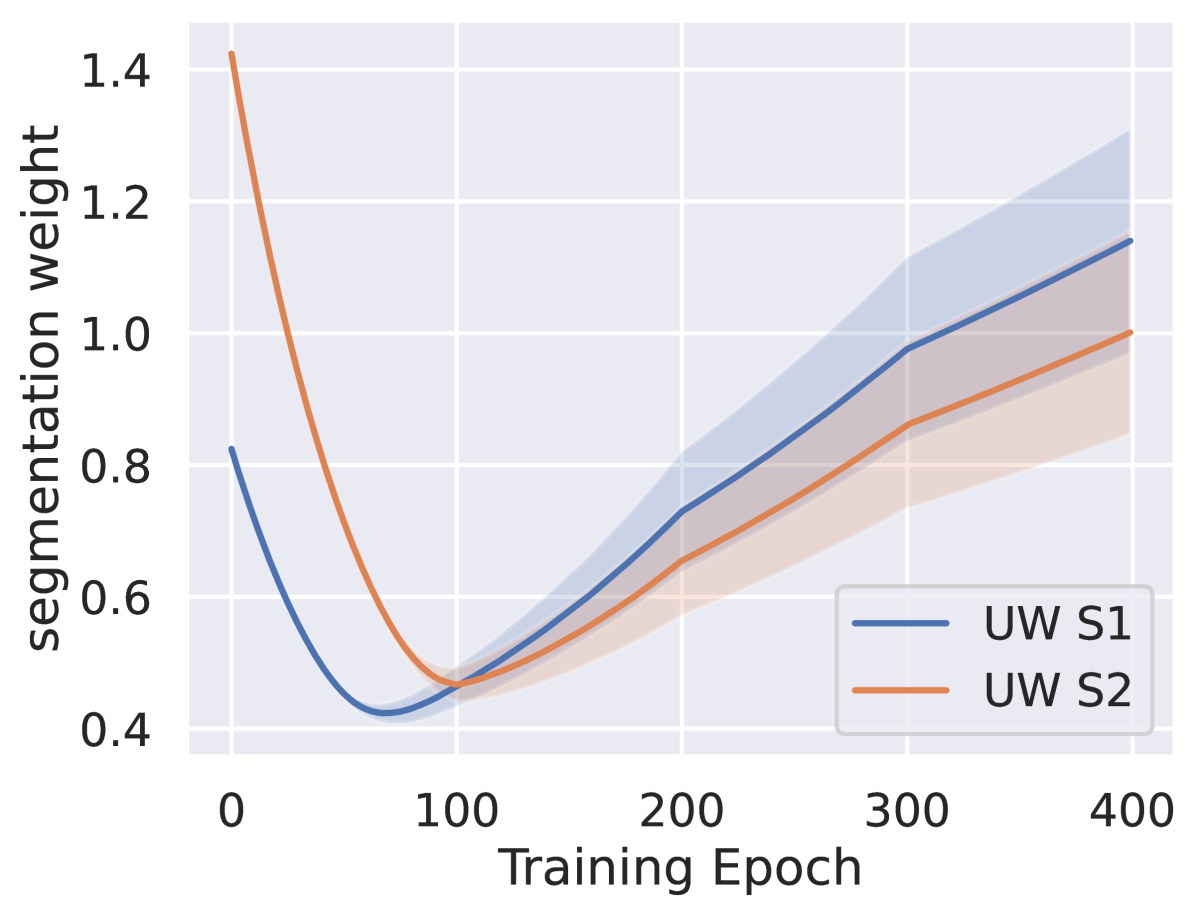
The paper proposes an Analytical Uncertainty-Based Loss Weighting (AULW) approach for multi-task learning. The key idea is to dynamically adjust the weights of each task's loss function during training based on an analytical estimate of the task-specific uncertainty.
The authors start by formulating the multi-task learning problem as a weighted sum of the individual task losses. They then derive an analytical expression for the task-specific uncertainty, which depends on factors like the task-specific data distribution and the model's current parameters.
This analytical uncertainty estimate is then used to compute dynamic loss weights for each task, which are updated throughout the training process. Tasks with higher uncertainty are assigned higher weights, encouraging the model to focus more on improving its performance on those tasks.
The authors evaluate their AULW approach on several multi-task learning benchmarks, including computer vision tasks like image classification and object detection. The results show that AULW can outperform other popular multi-task learning methods, demonstrating the benefits of the uncertainty-based loss weighting scheme.
Critical Analysis
The paper presents a novel and principled approach to addressing the challenge of balancing training in multi-task learning. The use of analytical uncertainty estimates to dynamically adjust loss weights is an interesting and well-motivated idea.
One potential limitation of the approach is the reliance on analytical expressions for the task-specific uncertainty, which may not always be easy to derive or may make simplifying assumptions. The authors acknowledge this and suggest that the approach could potentially be extended to use data-driven uncertainty estimates instead.
Additionally, the paper focuses on homogeneous multi-task learning, where all tasks share the same model architecture. It would be interesting to see how the AULW approach might be adapted to handle heterogeneous multi-task learning, where the tasks have different model architectures.
Overall, the paper presents a promising and well-designed approach to multi-task learning that could have important implications for a wide range of applications where a single model needs to perform multiple related tasks.
Conclusion
This paper introduces an Analytical Uncertainty-Based Loss Weighting (AULW) method for multi-task learning. The key idea is to dynamically adjust the weights of each task's loss function during training based on an analytical estimate of the task-specific uncertainty.
By focusing training on the tasks with higher uncertainty, the AULW approach aims to help the model learn a more balanced representation that performs well across all the tasks. The experimental results demonstrate the effectiveness of this approach compared to other multi-task learning methods.
While the paper has some limitations, such as the reliance on analytical uncertainty estimates, it represents an important contribution to the field of multi-task learning. The principles and insights presented could inspire further research and development in this area, with potential applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Analytical Uncertainty-Based Loss Weighting in Multi-Task Learning
Lukas Kirchdorfer, Cathrin Elich, Simon Kutsche, Heiner Stuckenschmidt, Lukas Schott, Jan M. Kohler
With the rise of neural networks in various domains, multi-task learning (MTL) gained significant relevance. A key challenge in MTL is balancing individual task losses during neural network training to improve performance and efficiency through knowledge sharing across tasks. To address these challenges, we propose a novel task-weighting method by building on the most prevalent approach of Uncertainty Weighting and computing analytically optimal uncertainty-based weights, normalized by a softmax function with tunable temperature. Our approach yields comparable results to the combinatorially prohibitive, brute-force approach of Scalarization while offering a more cost-effective yet high-performing alternative. We conduct an extensive benchmark on various datasets and architectures. Our method consistently outperforms six other common weighting methods. Furthermore, we report noteworthy experimental findings for the practical application of MTL. For example, larger networks diminish the influence of weighting methods, and tuning the weight decay has a low impact compared to the learning rate.
Read more8/16/2024

0
Robust Multi-Task Learning with Excess Risks
Yifei He, Shiji Zhou, Guojun Zhang, Hyokun Yun, Yi Xu, Belinda Zeng, Trishul Chilimbi, Han Zhao
Multi-task learning (MTL) considers learning a joint model for multiple tasks by optimizing a convex combination of all task losses. To solve the optimization problem, existing methods use an adaptive weight updating scheme, where task weights are dynamically adjusted based on their respective losses to prioritize difficult tasks. However, these algorithms face a great challenge whenever label noise is present, in which case excessive weights tend to be assigned to noisy tasks that have relatively large Bayes optimal errors, thereby overshadowing other tasks and causing performance to drop across the board. To overcome this limitation, we propose Multi-Task Learning with Excess Risks (ExcessMTL), an excess risk-based task balancing method that updates the task weights by their distances to convergence instead. Intuitively, ExcessMTL assigns higher weights to worse-trained tasks that are further from convergence. To estimate the excess risks, we develop an efficient and accurate method with Taylor approximation. Theoretically, we show that our proposed algorithm achieves convergence guarantees and Pareto stationarity. Empirically, we evaluate our algorithm on various MTL benchmarks and demonstrate its superior performance over existing methods in the presence of label noise. Our code is available at https://github.com/yifei-he/ExcessMTL.
Read more7/22/2024
📶
0
Epistemic Uncertainty-Weighted Loss for Visual Bias Mitigation
Rebecca S Stone, Nishant Ravikumar, Andrew J Bulpitt, David C Hogg
Deep neural networks are highly susceptible to learning biases in visual data. While various methods have been proposed to mitigate such bias, the majority require explicit knowledge of the biases present in the training data in order to mitigate. We argue the relevance of exploring methods which are completely ignorant of the presence of any bias, but are capable of identifying and mitigating them. Furthermore, we propose using Bayesian neural networks with a predictive uncertainty-weighted loss function to dynamically identify potential bias in individual training samples and to weight them during training. We find a positive correlation between samples subject to bias and higher epistemic uncertainties. Finally, we show the method has potential to mitigate visual bias on a bias benchmark dataset and on a real-world face detection problem, and we consider the merits and weaknesses of our approach.
Read more6/5/2024
🏷️
0
Bayesian Uncertainty for Gradient Aggregation in Multi-Task Learning
Idan Achituve, Idit Diamant, Arnon Netzer, Gal Chechik, Ethan Fetaya
As machine learning becomes more prominent there is a growing demand to perform several inference tasks in parallel. Running a dedicated model for each task is computationally expensive and therefore there is a great interest in multi-task learning (MTL). MTL aims at learning a single model that solves several tasks efficiently. Optimizing MTL models is often achieved by computing a single gradient per task and aggregating them for obtaining a combined update direction. However, these approaches do not consider an important aspect, the sensitivity in the gradient dimensions. Here, we introduce a novel gradient aggregation approach using Bayesian inference. We place a probability distribution over the task-specific parameters, which in turn induce a distribution over the gradients of the tasks. This additional valuable information allows us to quantify the uncertainty in each of the gradients dimensions, which can then be factored in when aggregating them. We empirically demonstrate the benefits of our approach in a variety of datasets, achieving state-of-the-art performance.
Read more5/14/2024