Analyzing the Generalization and Reliability of Steering Vectors -- ICML 2024

0
Sign in to get full access
Overview
- This paper analyzes the generalization and reliability of steering vectors, which are used to guide the behavior of large language models.
- Steering vectors allow users to personalize the output of language models by specifying desired attributes or characteristics.
- The paper investigates the stability and consistency of steering vectors across different model architectures, training datasets, and inference settings.
Plain English Explanation
Large language models like GPT-3 are powerful tools that can generate human-like text on a wide range of topics. However, these models can sometimes produce biased or undesirable outputs. Steering vectors provide a way for users to "steer" the model's behavior to align with their preferred attributes or styles.
Steering vectors work by specifying a target direction in the model's latent space, which the model then tries to follow when generating text. For example, a user could provide a steering vector that encourages the model to use more formal language or to express a particular sentiment.
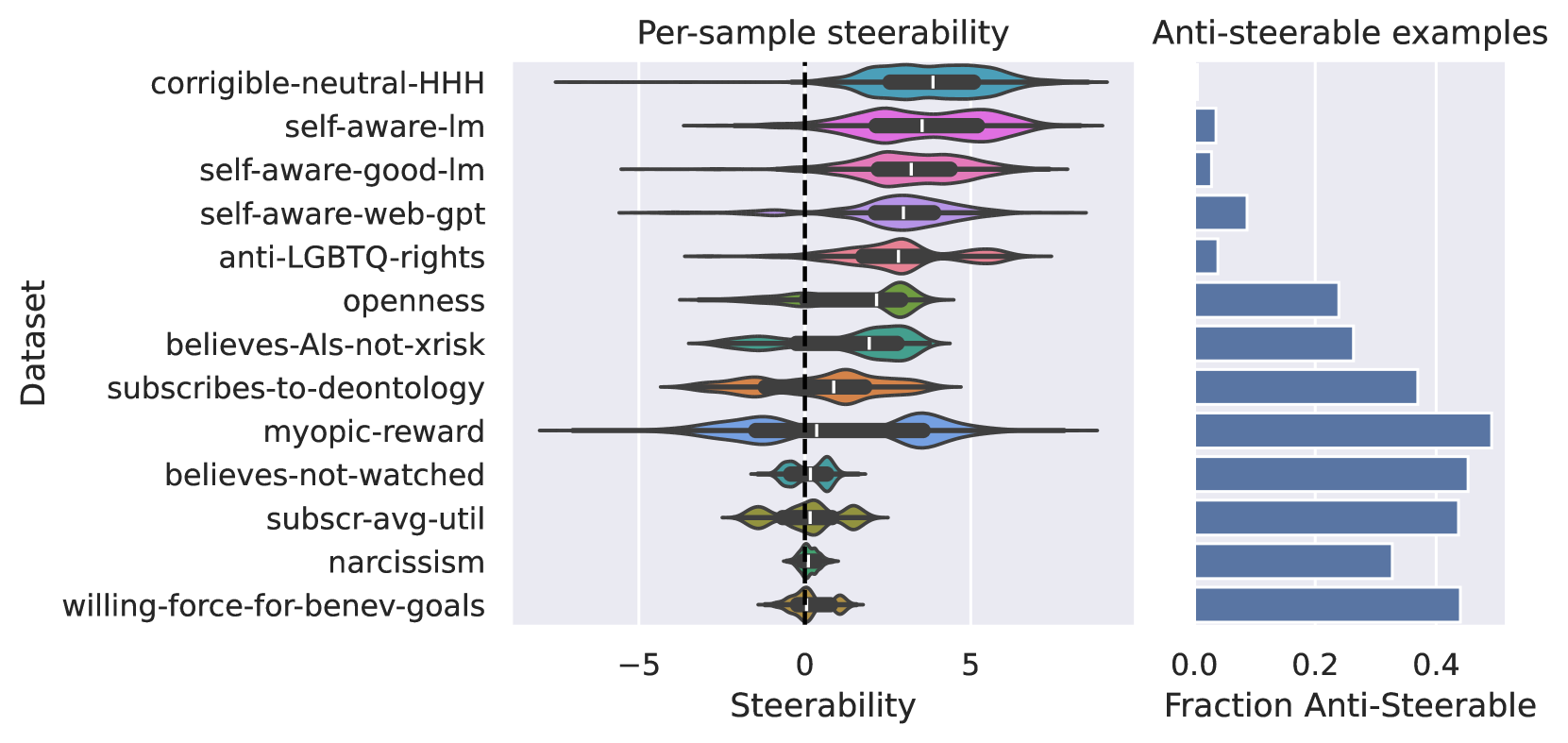
This paper investigates how reliable and consistent these steering vectors are. The researchers tested the steering vectors across different model architectures, training datasets, and inference settings to see how much the model's behavior changed. They wanted to understand how "robust" the steering vectors are and whether users can rely on them to consistently shape the model's outputs.
The results suggest that steering vectors do have some generalization capabilities, meaning they can work across different models and settings. However, the researchers also found cases where the steering vectors were less reliable, leading to inconsistent or unpredictable behaviors. This highlights the need for further research and development to improve the robustness and reliability of steering methods.
Technical Explanation
The paper examines the generalization and reliability of steering vectors, which are used to guide the behavior of large language models. Steering vectors allow users to personalize the output of language models by specifying desired attributes or characteristics, such as formality, sentiment, or topic.
The researchers conducted experiments to test the stability and consistency of steering vectors across different model architectures, training datasets, and inference settings. They evaluated the extent to which steering vectors can maintain their effectiveness and produce coherent and reliable outputs under these varying conditions.
The results suggest that steering vectors do exhibit some generalization capabilities, meaning they can work across different models and settings to a certain degree. However, the paper also identifies cases where the steering vectors are less reliable, leading to inconsistent or unpredictable model behaviors.
This work builds on previous research in word embeddings as steering signals and affine steering methods. The findings highlight the need for further research and development to improve the robustness and reliability of steering techniques and to better assess the generalization of language models in the vicinity of steering vectors.
Critical Analysis
The paper provides valuable insights into the limitations and challenges of using steering vectors to control the behavior of large language models. While the results demonstrate that steering vectors can have some generalization capabilities, the researchers also identify cases where the steering vectors are less reliable and lead to inconsistent outputs.
One potential concern raised in the paper is the lack of a clear understanding of the underlying mechanisms that govern the effectiveness of steering vectors. The researchers note that more research is needed to better explain how steering vectors interact with the language model's internal representations and how this interaction affects the model's behavior.
Additionally, the paper acknowledges that the evaluation of steering vector reliability is limited to the specific experiments conducted. It is possible that there are other factors, such as the complexity of the desired steering objective or the scale of the language model, that could further impact the consistency and robustness of steering vectors.
The paper also highlights the need for improved techniques and metrics to assess the generalization and reliability of steering methods. The current approaches may not fully capture the nuances and potential pitfalls of using steering vectors in real-world applications.
Overall, this paper represents an important step in understanding the practical limitations and challenges of using steering vectors to control large language models. The findings encourage researchers and practitioners to think critically about the assumptions and limitations of these techniques and to continue exploring ways to improve their reliability and robustness.
Conclusion
This paper provides a comprehensive analysis of the generalization and reliability of steering vectors, which are used to guide the behavior of large language models. The researchers conducted extensive experiments to evaluate the stability and consistency of steering vectors across different model architectures, training datasets, and inference settings.
The findings suggest that steering vectors do exhibit some generalization capabilities, allowing them to maintain their effectiveness to a certain degree under varying conditions. However, the paper also identifies cases where the steering vectors are less reliable, leading to inconsistent or unpredictable model outputs.
These insights are crucial for the continued development and deployment of personalized and controllable language models. The paper highlights the need for further research to better understand the underlying mechanisms of steering vectors, to improve the robustness and reliability of steering techniques, and to develop more comprehensive evaluation methods for assessing the generalization of language models in the vicinity of steering vectors.
By addressing these challenges, researchers and practitioners can work towards building more reliable and trustworthy language models that can be effectively steered to align with users' preferences and objectives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Analyzing the Generalization and Reliability of Steering Vectors -- ICML 2024
Daniel Tan, David Chanin, Aengus Lynch, Dimitrios Kanoulas, Brooks Paige, Adria Garriga-Alonso, Robert Kirk
Steering vectors (SVs) are a new approach to efficiently adjust language model behaviour at inference time by intervening on intermediate model activations. They have shown promise in terms of improving both capabilities and model alignment. However, the reliability and generalisation properties of this approach are unknown. In this work, we rigorously investigate these properties, and show that steering vectors have substantial limitations both in- and out-of-distribution. In-distribution, steerability is highly variable across different inputs. Depending on the concept, spurious biases can substantially contribute to how effective steering is for each input, presenting a challenge for the widespread use of steering vectors. Out-of-distribution, while steering vectors often generalise well, for several concepts they are brittle to reasonable changes in the prompt, resulting in them failing to generalise well. Overall, our findings show that while steering can work well in the right circumstances, there remain many technical difficulties of applying steering vectors to guide models' behaviour at scale.
Read more7/23/2024

0
Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization
Yuanpu Cao, Tianrong Zhang, Bochuan Cao, Ziyi Yin, Lu Lin, Fenglong Ma, Jinghui Chen
Researchers have been studying approaches to steer the behavior of Large Language Models (LLMs) and build personalized LLMs tailored for various applications. While fine-tuning seems to be a direct solution, it requires substantial computational resources and may significantly affect the utility of the original LLM. Recent endeavors have introduced more lightweight strategies, focusing on extracting steering vectors to guide the model's output toward desired behaviors by adjusting activations within specific layers of the LLM's transformer architecture. However, such steering vectors are directly extracted from the activations of human preference data and thus often lead to suboptimal results and occasional failures, especially in alignment-related scenarios. This work proposes an innovative approach that could produce more effective steering vectors through bi-directional preference optimization. Our method is designed to allow steering vectors to directly influence the generation probability of contrastive human preference data pairs, thereby offering a more precise representation of the target behavior. By carefully adjusting the direction and magnitude of the steering vector, we enabled personalized control over the desired behavior across a spectrum of intensities. Extensive experimentation across various open-ended generation tasks, particularly focusing on steering AI personas, has validated the efficacy of our approach. Moreover, we comprehensively investigate critical alignment-concerning scenarios, such as managing truthfulness, mitigating hallucination, and addressing jailbreaking attacks. Remarkably, our method can still demonstrate outstanding steering effectiveness across these scenarios. Furthermore, we showcase the transferability of our steering vectors across different models/LoRAs and highlight the synergistic benefits of applying multiple vectors simultaneously.
Read more7/31/2024

0
Steering Without Side Effects: Improving Post-Deployment Control of Language Models
Asa Cooper Stickland, Alexander Lyzhov, Jacob Pfau, Salsabila Mahdi, Samuel R. Bowman
Language models (LMs) have been shown to behave unexpectedly post-deployment. For example, new jailbreaks continually arise, allowing model misuse, despite extensive red-teaming and adversarial training from developers. Given most model queries are unproblematic and frequent retraining results in unstable user experience, methods for mitigation of worst-case behavior should be targeted. One such method is classifying inputs as potentially problematic, then selectively applying steering vectors on these problematic inputs, i.e. adding particular vectors to model hidden states. However, steering vectors can also negatively affect model performance, which will be an issue on cases where the classifier was incorrect. We present KL-then-steer (KTS), a technique that decreases the side effects of steering while retaining its benefits, by first training a model to minimize Kullback-Leibler (KL) divergence between a steered and unsteered model on benign inputs, then steering the model that has undergone this training. Our best method prevents 44% of jailbreak attacks compared to the original Llama-2-chat-7B model while maintaining helpfulness (as measured by MT-Bench) on benign requests almost on par with the original LM. To demonstrate the generality and transferability of our method beyond jailbreaks, we show that our KTS model can be steered to reduce bias towards user-suggested answers on TruthfulQA. Code is available: https://github.com/AsaCooperStickland/kl-then-steer.
Read more6/26/2024
💬
0
Word Embeddings Are Steers for Language Models
Chi Han, Jialiang Xu, Manling Li, Yi Fung, Chenkai Sun, Nan Jiang, Tarek Abdelzaher, Heng Ji
Language models (LMs) automatically learn word embeddings during pre-training on language corpora. Although word embeddings are usually interpreted as feature vectors for individual words, their roles in language model generation remain underexplored. In this work, we theoretically and empirically revisit output word embeddings and find that their linear transformations are equivalent to steering language model generation styles. We name such steers LM-Steers and find them existing in LMs of all sizes. It requires learning parameters equal to 0.2% of the original LMs' size for steering each style. On tasks such as language model detoxification and sentiment control, LM-Steers can achieve comparable or superior performance compared with state-of-the-art controlled generation methods while maintaining a better balance with generation quality. The learned LM-Steer serves as a lens in text styles: it reveals that word embeddings are interpretable when associated with language model generations and can highlight text spans that most indicate the style differences. An LM-Steer is transferrable between different language models by an explicit form calculation. One can also continuously steer LMs simply by scaling the LM-Steer or compose multiple LM-Steers by adding their transformations. Our codes are publicly available at url{https://github.com/Glaciohound/LM-Steer}.
Read more6/7/2024