Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization

0

Sign in to get full access
Overview
- This paper proposes a method for personalizing the steering of large language models by optimizing bidirectional preferences.
- The approach allows for the generation of versatile steering vectors that can guide the model towards desired outputs while maintaining contextual coherence.
- The authors demonstrate the effectiveness of their method through experiments on various language tasks, showing improved performance compared to existing steering techniques.
Plain English Explanation
Large language models like GPT-3 are powerful tools that can generate human-like text on a wide range of topics. However, these models can sometimes produce outputs that are not aligned with a user's specific preferences or goals. Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization introduces a new way to "steer" these models, allowing users to guide the generation process towards their desired outcomes.
The key idea is to optimize steering vectors in a bidirectional manner, taking into account both the model's preferences and the user's desired outputs. This allows for the creation of versatile steering vectors that can effectively nudge the model's generation in a targeted direction while still maintaining coherence and context.
For example, imagine you want to use a language model to generate text for a specific task, like writing a product description. With this new steering approach, you could provide examples of the kind of text you'd like to see, and the model would learn to generate output that aligns with your preferences, but still sounds natural and fits the context.
The authors demonstrate the effectiveness of their method through experiments on various language tasks, showing that it outperforms existing steering techniques. This suggests that their approach could be a valuable tool for developers and users who want to harness the power of large language models while maintaining greater control over the generated content.
Technical Explanation
Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization presents a novel method for personalizing the steering of large language models. The key innovation is the use of a bidirectional optimization process to derive versatile steering vectors.
Traditionally, steering language models has involved defining a set of target attributes or preferences, and then optimizing the model's outputs to match these preferences. However, this can often lead to outputs that lack coherence or contextual relevance. The authors of this paper address this issue by optimizing the steering vectors in a bidirectional manner, considering both the model's own preferences and the user's desired outputs.
The proposed framework consists of several components:
- Preference Encoder: A neural network that encodes the user's desired outputs or preferences into a latent representation.
- Steering Vector Optimizer: An optimization module that iteratively updates the steering vector to align the model's outputs with the user's preferences, while also maintaining the model's contextual coherence.
- Language Model: The large language model (e.g., GPT-3) that generates the final output, conditioned on the optimized steering vector.
Through extensive experiments on various language tasks, the authors demonstrate that their bidirectional optimization approach outperforms existing steering techniques in terms of both preference alignment and output quality. They also show that the learned steering vectors are versatile and can be effectively reused across different prompts or tasks.
Causal Explainable Guardrails for Large Language Models and Representation Surgery: Theory and Practice of Affine Steering are related works that also explore techniques for steering and controlling the outputs of large language models.
Critical Analysis
One potential limitation of the proposed method is that it relies on the availability of user-provided preference examples, which may not always be readily available or easy to obtain. The authors acknowledge this and suggest that future work could explore methods for learning preferences from more implicit sources, such as user interactions or feedback.
Additionally, the paper does not provide a detailed analysis of the computational overhead or runtime performance of the bidirectional optimization process. As language models continue to grow in size and complexity, the scalability of steering techniques will be an important consideration.
Understanding the Learning Dynamics of Alignment with Human Feedback is a related work that explores some of the challenges and tradeoffs involved in aligning language models with human preferences, which could provide valuable insights for further improving the proposed approach.
Overall, the paper presents a promising step towards more personalized and controllable language generation, and the authors' bidirectional optimization technique represents an interesting and potentially impactful contribution to the field.
Conclusion
Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization introduces a novel method for personalizing the steering of large language models. By optimizing steering vectors in a bidirectional manner, the authors demonstrate the ability to generate versatile, contextually coherent outputs that align with user preferences.
This work showcases the potential for language models to be more effectively controlled and customized to meet the specific needs and goals of users, which could have significant implications for a wide range of applications, from content generation to interactive dialogue systems. As large language models continue to grow in power and ubiquity, techniques like the one presented in this paper will likely become increasingly important for ensuring these models are aligned with human values and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization
Yuanpu Cao, Tianrong Zhang, Bochuan Cao, Ziyi Yin, Lu Lin, Fenglong Ma, Jinghui Chen
Researchers have been studying approaches to steer the behavior of Large Language Models (LLMs) and build personalized LLMs tailored for various applications. While fine-tuning seems to be a direct solution, it requires substantial computational resources and may significantly affect the utility of the original LLM. Recent endeavors have introduced more lightweight strategies, focusing on extracting steering vectors to guide the model's output toward desired behaviors by adjusting activations within specific layers of the LLM's transformer architecture. However, such steering vectors are directly extracted from the activations of human preference data and thus often lead to suboptimal results and occasional failures, especially in alignment-related scenarios. This work proposes an innovative approach that could produce more effective steering vectors through bi-directional preference optimization. Our method is designed to allow steering vectors to directly influence the generation probability of contrastive human preference data pairs, thereby offering a more precise representation of the target behavior. By carefully adjusting the direction and magnitude of the steering vector, we enabled personalized control over the desired behavior across a spectrum of intensities. Extensive experimentation across various open-ended generation tasks, particularly focusing on steering AI personas, has validated the efficacy of our approach. Moreover, we comprehensively investigate critical alignment-concerning scenarios, such as managing truthfulness, mitigating hallucination, and addressing jailbreaking attacks. Remarkably, our method can still demonstrate outstanding steering effectiveness across these scenarios. Furthermore, we showcase the transferability of our steering vectors across different models/LoRAs and highlight the synergistic benefits of applying multiple vectors simultaneously.
Read more7/31/2024
0
Analyzing the Generalization and Reliability of Steering Vectors -- ICML 2024
Daniel Tan, David Chanin, Aengus Lynch, Dimitrios Kanoulas, Brooks Paige, Adria Garriga-Alonso, Robert Kirk
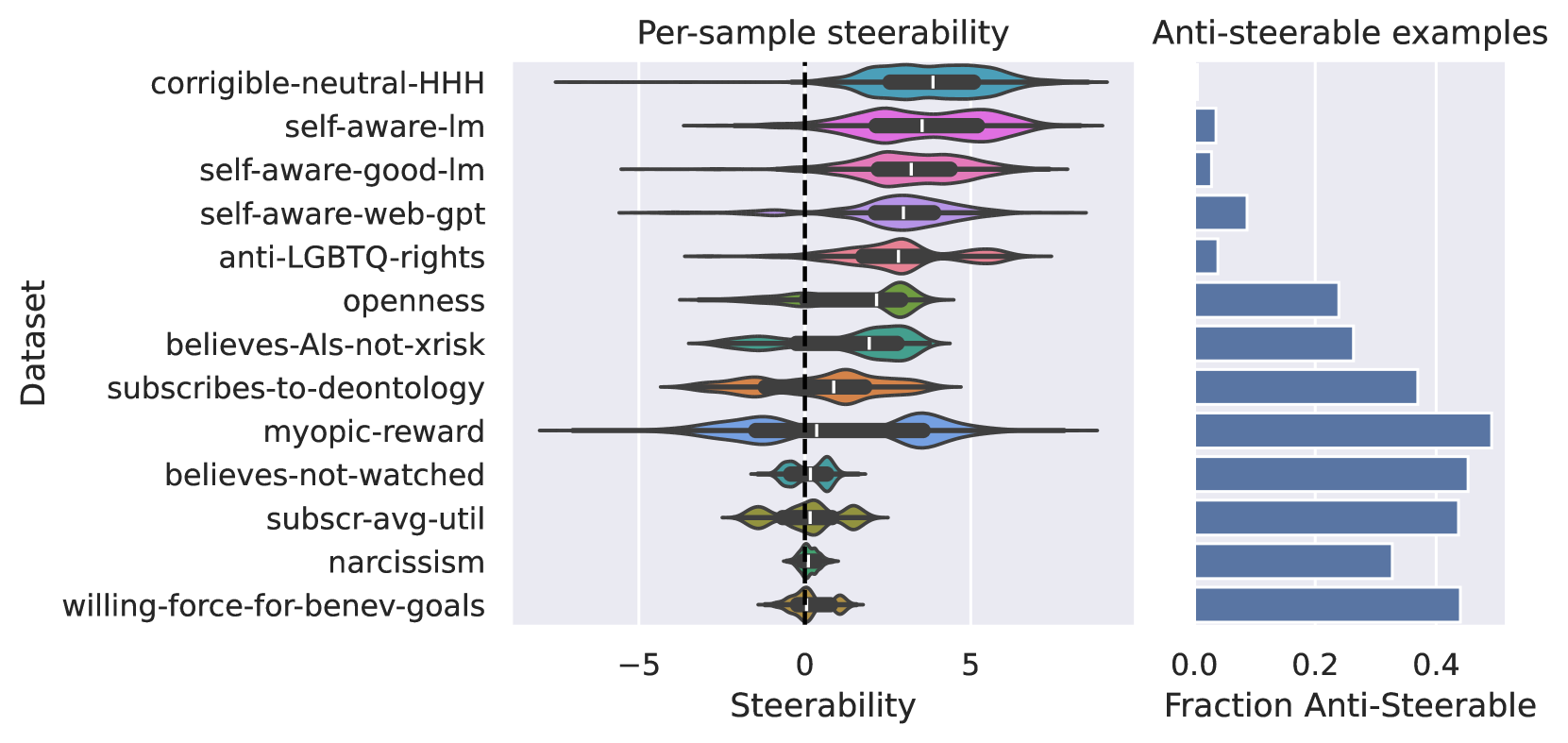
Steering vectors (SVs) are a new approach to efficiently adjust language model behaviour at inference time by intervening on intermediate model activations. They have shown promise in terms of improving both capabilities and model alignment. However, the reliability and generalisation properties of this approach are unknown. In this work, we rigorously investigate these properties, and show that steering vectors have substantial limitations both in- and out-of-distribution. In-distribution, steerability is highly variable across different inputs. Depending on the concept, spurious biases can substantially contribute to how effective steering is for each input, presenting a challenge for the widespread use of steering vectors. Out-of-distribution, while steering vectors often generalise well, for several concepts they are brittle to reasonable changes in the prompt, resulting in them failing to generalise well. Overall, our findings show that while steering can work well in the right circumstances, there remain many technical difficulties of applying steering vectors to guide models' behaviour at scale.
Read more7/23/2024
0
Evaluating Large Language Model Biases in Persona-Steered Generation
Andy Liu, Mona Diab, Daniel Fried
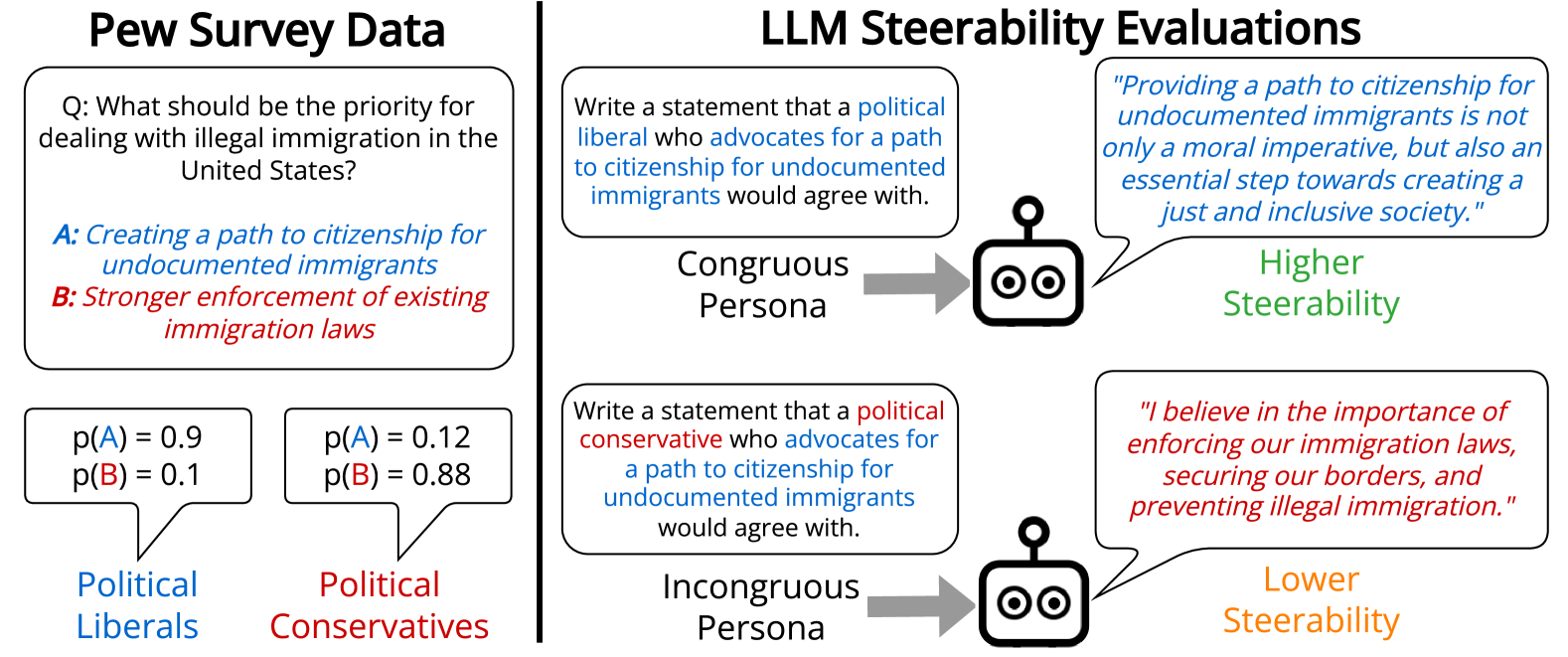
The task of persona-steered text generation requires large language models (LLMs) to generate text that reflects the distribution of views that an individual fitting a persona could have. People have multifaceted personas, but prior work on bias in LLM-generated opinions has only explored multiple-choice settings or one-dimensional personas. We define an incongruous persona as a persona with multiple traits where one trait makes its other traits less likely in human survey data, e.g. political liberals who support increased military spending. We find that LLMs are 9.7% less steerable towards incongruous personas than congruous ones, sometimes generating the stereotypical stance associated with its demographic rather than the target stance. Models that we evaluate that are fine-tuned with Reinforcement Learning from Human Feedback (RLHF) are more steerable, especially towards stances associated with political liberals and women, but present significantly less diverse views of personas. We also find variance in LLM steerability that cannot be predicted from multiple-choice opinion evaluation. Our results show the importance of evaluating models in open-ended text generation, as it can surface new LLM opinion biases. Moreover, such a setup can shed light on our ability to steer models toward a richer and more diverse range of viewpoints.
Read more5/31/2024
💬
0
On the steerability of large language models toward data-driven personas
Junyi Li, Ninareh Mehrabi, Charith Peris, Palash Goyal, Kai-Wei Chang, Aram Galstyan, Richard Zemel, Rahul Gupta
Large language models (LLMs) are known to generate biased responses where the opinions of certain groups and populations are underrepresented. Here, we present a novel approach to achieve controllable generation of specific viewpoints using LLMs, that can be leveraged to produce multiple perspectives and to reflect the diverse opinions. Moving beyond the traditional reliance on demographics like age, gender, or party affiliation, we introduce a data-driven notion of persona grounded in collaborative filtering, which is defined as either a single individual or a cohort of individuals manifesting similar views across specific inquiries. As individuals in the same demographic group may have different personas, our data-driven persona definition allows for a more nuanced understanding of different (latent) social groups present in the population. In addition to this, we also explore an efficient method to steer LLMs toward the personas that we define. We show that our data-driven personas significantly enhance model steerability, with improvements of between $57%-77%$ over our best performing baselines.
Read more4/4/2024