Analyzing and reducing the synthetic-to-real transfer gap in Music Information Retrieval: the task of automatic drum transcription

0
Sign in to get full access
Overview
- The research paper analyzes and aims to reduce the gap between synthetic and real-world data in the task of automatic drum transcription, a key problem in Music Information Retrieval (MIR).
- Automatic drum transcription involves using machine learning models to convert audio recordings into a musical score representation of the drum parts.
- The paper focuses on understanding and minimizing the "synthetic-to-real transfer gap" - the performance difference between models trained on synthetic data versus real-world data.
Plain English Explanation
The paper examines the challenge of automatically transcribing the drum parts in music recordings. Automatic drum transcription is a key task in the field of Music Information Retrieval, where machine learning models are used to convert audio into a written musical score for the drum parts.
A key issue is the "synthetic-to-real transfer gap" - the performance difference between models trained on synthetic (computer-generated) drum data versus models trained on real-world recordings. The paper aims to analyze and find ways to reduce this gap, so that models trained on cheaper, more available synthetic data can perform well on real-world music.
Technical Explanation
The paper explores several aspects to address the synthetic-to-real transfer gap in automatic drum transcription:
-
Analyzing the transfer gap - The researchers quantify the performance difference between models trained on synthetic versus real data, and investigate the underlying causes.
-
Leveraging real-world data - The paper explores techniques to effectively incorporate limited amounts of real-world drum recordings into the training process.
-
Synthetic data augmentation - Novel methods are proposed to generate more diverse synthetic drum data to bridge the gap to real-world recordings.
-
Architectural modifications - The researchers experiment with changes to the model architecture to improve its ability to generalize from synthetic to real data.
Through a series of experiments, the paper provides insights into the key factors contributing to the synthetic-to-real transfer gap, and demonstrates effective techniques to narrow this gap and improve the performance of automatic drum transcription models on real-world music.
Critical Analysis
The paper takes a comprehensive approach to addressing an important practical challenge in the field of Music Information Retrieval. By thoroughly analyzing the synthetic-to-real transfer gap and exploring multiple strategies to mitigate it, the research provides valuable guidance for developing robust drum transcription systems.
However, the paper does acknowledge some limitations, such as the need for further investigation into the generalization of the proposed techniques to other types of music and instruments beyond drums. Additionally, the reliance on certain synthetic dataset characteristics or model architectures may limit the broader applicability of the findings.
It would be interesting to see the researchers extend this work to explore the transfer gap in other MIR tasks, such as piano transcription or multi-instrument transcription. Investigating how the transfer gap manifests and can be addressed in these related domains could lead to more generalized insights and solutions.
Conclusion
This research paper tackles the critical challenge of reducing the performance gap between machine learning models trained on synthetic data versus real-world data for the task of automatic drum transcription. By thoroughly analyzing the underlying factors contributing to this "synthetic-to-real transfer gap" and exploring various techniques to bridge it, the paper provides valuable insights and practical strategies for developing robust MIR systems.
The findings have the potential to significantly improve the applicability of automatic drum transcription in real-world music analysis and production workflows, where the ability to effectively leverage synthetic data can lead to more scalable and cost-effective solutions. This work represents an important step forward in addressing a key practical challenge in the field of Music Information Retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Analyzing and reducing the synthetic-to-real transfer gap in Music Information Retrieval: the task of automatic drum transcription
Mickael Zehren, Marco Alunno, Paolo Bientinesi
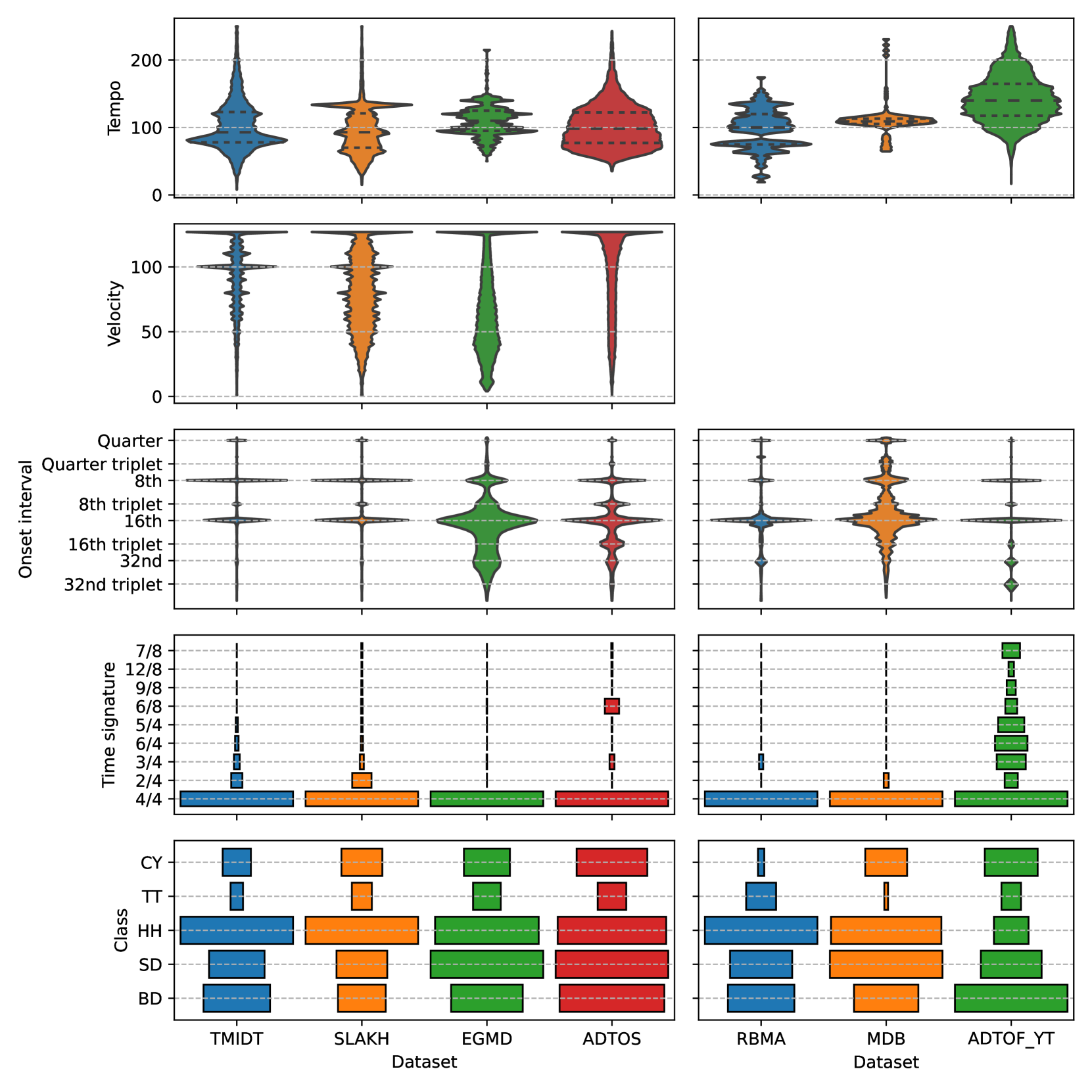
Automatic drum transcription is a critical tool in Music Information Retrieval for extracting and analyzing the rhythm of a music track, but it is limited by the size of the datasets available for training. A popular method used to increase the amount of data is by generating them synthetically from music scores rendered with virtual instruments. This method can produce a virtually infinite quantity of tracks, but empirical evidence shows that models trained on previously created synthetic datasets do not transfer well to real tracks. In this work, besides increasing the amount of data, we identify and evaluate three more strategies that practitioners can use to improve the realism of the generated data and, thus, narrow the synthetic-to-real transfer gap. To explore their efficacy, we used them to build a new synthetic dataset and then we measured how the performance of a model scales and, specifically, at what value it will stagnate when increasing the number of training tracks for different datasets. By doing this, we were able to prove that the aforementioned strategies contribute to make our dataset the one with the most realistic data distribution and the lowest synthetic-to-real transfer gap among the synthetic datasets we evaluated. We conclude by highlighting the limits of training with infinite data in drum transcription and we show how they can be overcome.
Read more7/30/2024

0
Annotation-free Automatic Music Transcription with Scalable Synthetic Data and Adversarial Domain Confusion
Gakusei Sato, Taketo Akama
Automatic Music Transcription (AMT) is a vital technology in the field of music information processing. Despite recent enhancements in performance due to machine learning techniques, current methods typically attain high accuracy in domains where abundant annotated data is available. Addressing domains with low or no resources continues to be an unresolved challenge. To tackle this issue, we propose a transcription model that does not require any MIDI-audio paired data through the utilization of scalable synthetic audio for pre-training and adversarial domain confusion using unannotated real audio. In experiments, we evaluate methods under the real-world application scenario where training datasets do not include the MIDI annotation of audio in the target data domain. Our proposed method achieved competitive performance relative to established baseline methods, despite not utilizing any real datasets of paired MIDI-audio. Additionally, ablation studies have provided insights into the scalability of this approach and the forthcoming challenges in the field of AMT research.
Read more7/4/2024
0
Towards Musically Informed Evaluation of Piano Transcription Models
Patricia Hu, Luk'av{s} Samuel Mart'ak, Carlos Cancino-Chac'on, Gerhard Widmer
Automatic piano transcription models are typically evaluated using simple frame- or note-wise information retrieval (IR) metrics. Such benchmark metrics do not provide insights into the transcription quality of specific musical aspects such as articulation, dynamics, or rhythmic precision of the output, which are essential in the context of expressive performance analysis. Furthermore, in recent years, MAESTRO has become the de-facto training and evaluation dataset for such models. However, inference performance has been observed to deteriorate substantially when applied on out-of-distribution data, thereby questioning the suitability and reliability of transcribed outputs from such models for specific MIR tasks. In this work, we investigate the performance of three state-of-the-art piano transcription models in two experiments. In the first one, we propose a variety of musically informed evaluation metrics which, in contrast to the IR metrics, offer more detailed insight into the musical quality of the transcriptions. In the second experiment, we compare inference performance on real-world and perturbed audio recordings, and highlight musical dimensions which our metrics can help explain. Our experimental results highlight the weaknesses of existing piano transcription metrics and contribute to a more musically sound error analysis of transcription outputs.
Read more7/30/2024
0
Leveraging Electric Guitar Tones and Effects to Improve Robustness in Guitar Tablature Transcription Modeling
Hegel Pedroza, Wallace Abreu, Ryan Corey, Iran Roman
Guitar tablature transcription (GTT) aims at automatically generating symbolic representations from real solo guitar performances. Due to its applications in education and musicology, GTT has gained traction in recent years. However, GTT robustness has been limited due to the small size of available datasets. Researchers have recently used synthetic data that simulates guitar performances using pre-recorded or computer-generated tones and can be automatically generated at large scales. The present study complements these efforts by demonstrating that GTT robustness can be improved by including synthetic training data created using recordings of real guitar tones played with different audio effects. We evaluate our approach on a new evaluation dataset with professional solo guitar performances that we composed and collected, featuring a wide array of tones, chords, and scales.
Read more7/16/2024