Towards Musically Informed Evaluation of Piano Transcription Models

0
Sign in to get full access
Overview
- This paper proposes a new approach to evaluating piano transcription models that considers musical characteristics beyond just note-level accuracy.
- The authors argue that current evaluation metrics may not fully capture the musical quality of transcriptions, and they introduce a set of musically-informed metrics to address this.
- The paper also presents a new dataset of piano performances with detailed ground truth annotations, which can be used to train and evaluate transcription models.
Plain English Explanation
The paper focuses on improving the way we evaluate piano transcription models, which are AI systems that can convert audio recordings of piano music into a written score or "transcription." Towards efficient real-time piano transcription using and BERT-like pre-training for symbolic piano music are examples of recent work in this area.
Current evaluation methods for these models often just look at how accurately they can identify individual notes. However, the authors argue that this doesn't fully capture the musical quality of the transcriptions. Just because a model gets the notes right doesn't mean the resulting music will sound natural or expressive.
To address this, the researchers introduce a set of new evaluation metrics that take into account musical elements like rhythm, dynamics, and phrasing. They also present a new dataset of piano performances with detailed annotations that can be used to train and test transcription models in a more musically-informed way.
The goal is to push the field of piano transcription towards models that don't just accurately identify notes, but can also capture the nuance and expression of human piano playing. This could lead to transcriptions that sound more natural and pleasing to the ear, which could have applications in areas like sheet music transformer for end-to-end optical music recognition and sheet music transformer for end-to-end full piano transcription.
Technical Explanation
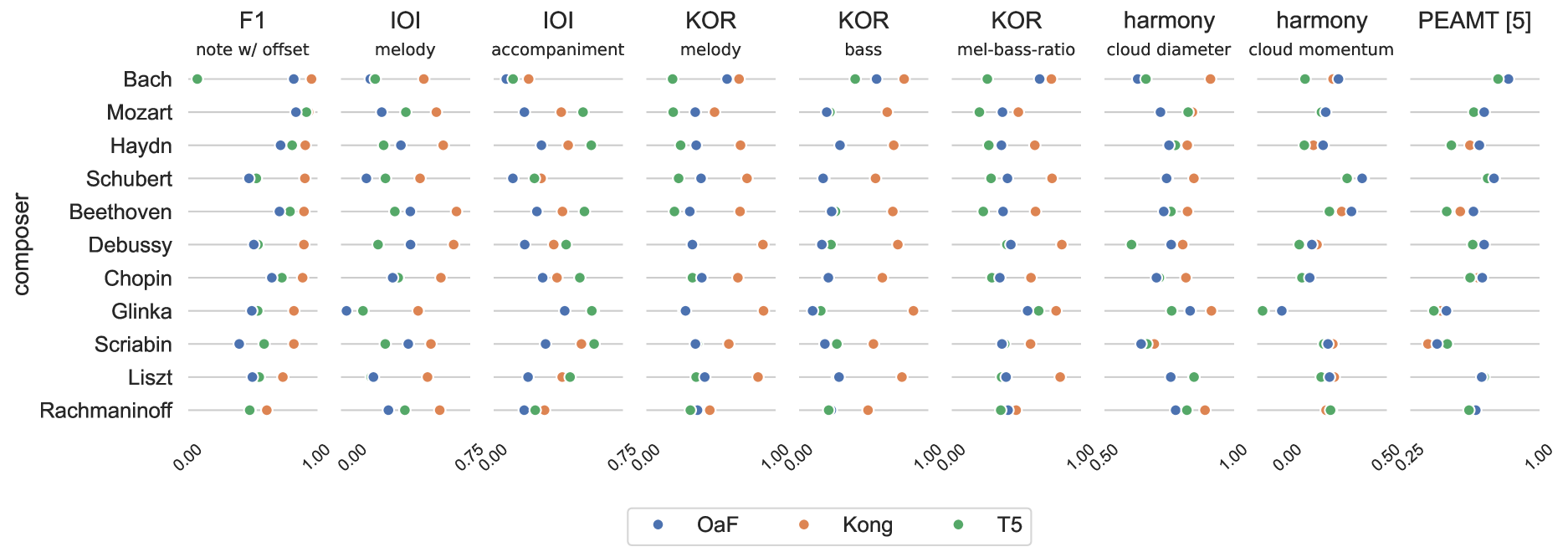
The paper first reviews existing approaches to evaluating piano transcription models, which typically focus on metrics like note-level precision, recall, and F-measure. The authors argue that while these metrics are useful, they don't capture more nuanced musical qualities.
To address this, the researchers propose a set of new evaluation metrics inspired by music theory and previous work on expressive music performance analysis. These include:
- Rhythm Similarity: Measures how well the transcribed rhythm matches the ground truth.
- Dynamics Similarity: Compares the transcribed volume changes to the ground truth.
- Articulation Similarity: Assesses how well the transcription captures the timing and phrasing of notes.
- Pitch Similarity: Evaluates the accuracy of the transcribed pitches.
To enable this more musically-informed evaluation, the authors also introduce a new dataset called the "Piano Performance Dataset" (PPD). This dataset contains over 8 hours of high-quality piano recordings with detailed ground truth annotations of note onsets, offsets, velocities, and pedal information.
The paper then presents experiments using the PPD dataset to evaluate several state-of-the-art piano transcription models, including end-to-end real-world polyphonic piano transcription. The results show that the proposed metrics can provide additional insights beyond just note-level accuracy.
Critical Analysis
The authors make a compelling case for the need to move beyond note-level accuracy when evaluating piano transcription models. Their introduction of musically-informed metrics is a valuable contribution that could help drive the field towards more expressive and natural-sounding transcriptions.
However, the paper does not provide much discussion of the limitations or potential issues with these new metrics. For example, it's unclear how sensitive they are to small variations in performance, or how well they correlate with human judgments of musical quality.
Additionally, the dataset used in the experiments, while impressive, is still relatively small compared to the diversity of piano music. It remains to be seen how well the proposed evaluation approach will generalize to a wider range of musical styles and performance conditions.
Future research could explore ways to further validate and refine the musically-informed metrics, perhaps by conducting subjective listening tests or comparing the model rankings to expert opinions. Expanding the dataset to include more diverse musical content could also help solidify the practical utility of this approach.
Conclusion
This paper presents a novel approach to evaluating piano transcription models that goes beyond just note-level accuracy. By introducing a set of musically-informed metrics and a new dataset for training and testing, the authors aim to push the field towards models that can capture the nuance and expression of human piano performance.
While further research is needed to fully validate and refine this approach, the work represents an important step forward in the quest for AI systems that can produce piano transcriptions that sound natural and pleasing to the ear. This could have applications in areas like sheet music transformer for end-to-end optical music recognition and sheet music transformer for end-to-end full piano transcription, as well as potentially end-to-end real-world polyphonic piano transcription.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Musically Informed Evaluation of Piano Transcription Models
Patricia Hu, Luk'av{s} Samuel Mart'ak, Carlos Cancino-Chac'on, Gerhard Widmer
Automatic piano transcription models are typically evaluated using simple frame- or note-wise information retrieval (IR) metrics. Such benchmark metrics do not provide insights into the transcription quality of specific musical aspects such as articulation, dynamics, or rhythmic precision of the output, which are essential in the context of expressive performance analysis. Furthermore, in recent years, MAESTRO has become the de-facto training and evaluation dataset for such models. However, inference performance has been observed to deteriorate substantially when applied on out-of-distribution data, thereby questioning the suitability and reliability of transcribed outputs from such models for specific MIR tasks. In this work, we investigate the performance of three state-of-the-art piano transcription models in two experiments. In the first one, we propose a variety of musically informed evaluation metrics which, in contrast to the IR metrics, offer more detailed insight into the musical quality of the transcriptions. In the second experiment, we compare inference performance on real-world and perturbed audio recordings, and highlight musical dimensions which our metrics can help explain. Our experimental results highlight the weaknesses of existing piano transcription metrics and contribute to a more musically sound error analysis of transcription outputs.
Read more7/30/2024

0
Towards Efficient and Real-Time Piano Transcription Using Neural Autoregressive Models
Taegyun Kwon, Dasaem Jeong, Juhan Nam
In recent years, advancements in neural network designs and the availability of large-scale labeled datasets have led to significant improvements in the accuracy of piano transcription models. However, most previous work focused on high-performance offline transcription, neglecting deliberate consideration of model size. The goal of this work is to implement real-time inference for piano transcription while ensuring both high performance and lightweight. To this end, we propose novel architectures for convolutional recurrent neural networks, redesigning an existing autoregressive piano transcription model. First, we extend the acoustic module by adding a frequency-conditioned FiLM layer to the CNN module to adapt the convolutional filters on the frequency axis. Second, we improve note-state sequence modeling by using a pitchwise LSTM that focuses on note-state transitions within a note. In addition, we augment the autoregressive connection with an enhanced recursive context. Using these components, we propose two types of models; one for high performance and the other for high compactness. Through extensive experiments, we show that the proposed models are comparable to state-of-the-art models in terms of note accuracy on the MAESTRO dataset. We also investigate the effective model size and real-time inference latency by gradually streamlining the architecture. Finally, we conduct cross-data evaluation on unseen piano datasets and in-depth analysis to elucidate the effect of the proposed components in the view of note length and pitch range.
Read more4/11/2024

0
From Audio Encoders to Piano Judges: Benchmarking Performance Understanding for Solo Piano
Huan Zhang, Jinhua Liang, Simon Dixon
Our study investigates an approach for understanding musical performances through the lens of audio encoding models, focusing on the domain of solo Western classical piano music. Compared to composition-level attribute understanding such as key or genre, we identify a knowledge gap in performance-level music understanding, and address three critical tasks: expertise ranking, difficulty estimation, and piano technique detection, introducing a comprehensive Pianism-Labelling Dataset (PLD) for this purpose. We leverage pre-trained audio encoders, specifically Jukebox, Audio-MAE, MERT, and DAC, demonstrating varied capabilities in tackling downstream tasks, to explore whether domain-specific fine-tuning enhances capability in capturing performance nuances. Our best approach achieved 93.6% accuracy in expertise ranking, 33.7% in difficulty estimation, and 46.7% in technique detection, with Audio-MAE as the overall most effective encoder. Finally, we conducted a case study on Chopin Piano Competition data using trained models for expertise ranking, which highlights the challenge of accurately assessing top-tier performances.
Read more7/22/2024
0
Analyzing and reducing the synthetic-to-real transfer gap in Music Information Retrieval: the task of automatic drum transcription
Mickael Zehren, Marco Alunno, Paolo Bientinesi
Automatic drum transcription is a critical tool in Music Information Retrieval for extracting and analyzing the rhythm of a music track, but it is limited by the size of the datasets available for training. A popular method used to increase the amount of data is by generating them synthetically from music scores rendered with virtual instruments. This method can produce a virtually infinite quantity of tracks, but empirical evidence shows that models trained on previously created synthetic datasets do not transfer well to real tracks. In this work, besides increasing the amount of data, we identify and evaluate three more strategies that practitioners can use to improve the realism of the generated data and, thus, narrow the synthetic-to-real transfer gap. To explore their efficacy, we used them to build a new synthetic dataset and then we measured how the performance of a model scales and, specifically, at what value it will stagnate when increasing the number of training tracks for different datasets. By doing this, we were able to prove that the aforementioned strategies contribute to make our dataset the one with the most realistic data distribution and the lowest synthetic-to-real transfer gap among the synthetic datasets we evaluated. We conclude by highlighting the limits of training with infinite data in drum transcription and we show how they can be overcome.
Read more7/30/2024