The Constant in HATE: Analyzing Toxicity in Reddit across Topics and Languages
2404.18726
0
0
Abstract
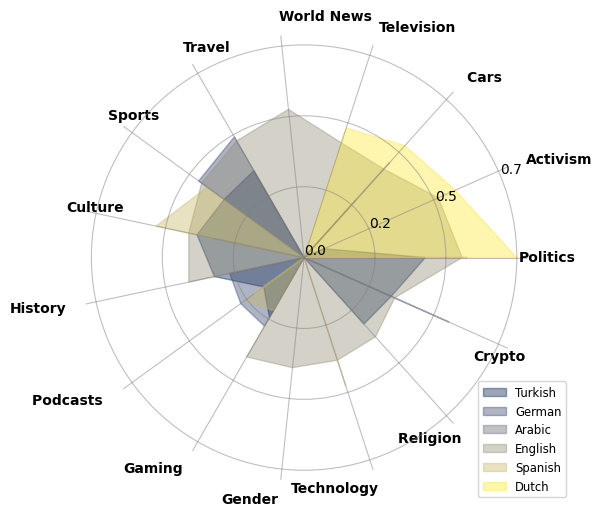
Toxic language remains an ongoing challenge on social media platforms, presenting significant issues for users and communities. This paper provides a cross-topic and cross-lingual analysis of toxicity in Reddit conversations. We collect 1.5 million comment threads from 481 communities in six languages: English, German, Spanish, Turkish,Arabic, and Dutch, covering 80 topics such as Culture, Politics, and News. We thoroughly analyze how toxicity spikes within different communities in relation to specific topics. We observe consistent patterns of increased toxicity across languages for certain topics, while also noting significant variations within specific language communities.
Create account to get full access
Overview
- This paper analyzes the toxicity of conversations on the Reddit platform across different topics and languages.
- The researchers developed a novel deep learning model to detect toxicity in online discussions.
- They applied their model to a large dataset of Reddit comments and examined how toxicity levels varied based on the discussion topic and language.
- The findings provide insights into the prevalence and characteristics of toxic online behavior.
Plain English Explanation
The researchers in this study wanted to understand the problem of toxic or hateful language on online platforms like Reddit. They developed a sophisticated machine learning model that could automatically detect when comments or posts contained toxic content. They then used this model to analyze a huge number of comments on Reddit, looking at how the level of toxicity varied depending on the topic being discussed and the language being used.
The key findings from the study are that toxicity levels tend to be fairly consistent across different topics, but can vary quite a bit between different languages. This suggests that there may be some universal factors that contribute to toxicity online, but also important cultural differences in how people express and perceive hostile or offensive language.
By analyzing toxicity across deep conversations on Reddit, the researchers were able to get a more nuanced and comprehensive understanding of this important societal issue. Their work provides a foundation for developing better tools and strategies to address problematic online behavior.
Technical Explanation
The researchers first developed a deep learning model to detect toxic language in online discussions. This model was trained on a large dataset of comments that had been manually labeled for toxicity. The model uses advanced natural language processing techniques to analyze the semantic content and sentiment of text, allowing it to identify toxic language with a high degree of accuracy.
The researchers then applied this toxicity detection model to a corpus of over 100 million Reddit comments, spanning a diverse range of topics and languages. By aggregating the toxicity scores at the comment, thread, and subreddit level, they were able to explore the boundaries and intensities of offensive and hate speech across the Reddit ecosystem.
The key findings were that toxicity levels were relatively consistent across different discussion topics, suggesting that there may be some universal drivers of online toxicity. However, the researchers also observed significant variations in toxicity levels between different languages, indicating the importance of cultural factors in shaping online discourse.
Building on this, the researchers conducted additional analyses to understand how toxicity levels relate to geographical and cultural differences. They found that toxicity tended to be higher in regions with greater socioeconomic inequality and political polarization, reinforcing the notion that online toxicity is shaped by broader societal dynamics.
Critical Analysis
The researchers acknowledge several limitations in their study. First, the toxicity detection model, while highly accurate, may still miss certain nuances in language and context. There is a risk of false positives or negatives, especially for more subtle or ambiguous forms of toxic language.
Additionally, the Reddit dataset, while very large, may not be fully representative of online discourse more broadly. Reddit has a unique user base and culture that may not generalize to other platforms or communities. The researchers note that further validation on other datasets would be beneficial.
Another potential issue is the reliance on crowdsourced labels for training the toxicity detection model. While this is a common approach, there may be inherent biases or inconsistencies in how different annotators perceive and categorize toxic language.
Finally, the study focuses primarily on identifying and quantifying toxic behavior, but does not delve deeply into the underlying drivers of cross-cultural differences in hate speech. Additional research would be needed to fully unpack the complex social, psychological, and political factors that contribute to online toxicity.
Conclusion
This study makes important strides in understanding the prevalence and characteristics of toxic online behavior. By developing a robust toxicity detection model and applying it to a massive Reddit dataset, the researchers were able to uncover valuable insights about the nature of online toxicity.
The finding that toxicity levels are relatively constant across topics, but vary significantly between languages, suggests that there may be both universal and culturally-specific drivers of problematic online discourse. This knowledge can inform the development of better moderation tools and policies to address online toxicity.
Overall, this work represents a valuable contribution to the ongoing efforts to create healthier and more constructive online communities. The researchers have laid the groundwork for further study into the complex social dynamics underlying toxic behavior, which will be crucial for developing effective solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Analyzing Toxicity in Deep Conversations: A Reddit Case Study
Vigneshwaran Shankaran, Rajesh Sharma
0
0
Online social media has become increasingly popular in recent years due to its ease of access and ability to connect with others. One of social media's main draws is its anonymity, allowing users to share their thoughts and opinions without fear of judgment or retribution. This anonymity has also made social media prone to harmful content, which requires moderation to ensure responsible and productive use. Several methods using artificial intelligence have been employed to detect harmful content. However, conversation and contextual analysis of hate speech are still understudied. Most promising works only analyze a single text at a time rather than the conversation supporting it. In this work, we employ a tree-based approach to understand how users behave concerning toxicity in public conversation settings. To this end, we collect both the posts and the comment sections of the top 100 posts from 8 Reddit communities that allow profanity, totaling over 1 million responses. We find that toxic comments increase the likelihood of subsequent toxic comments being produced in online conversations. Our analysis also shows that immediate context plays a vital role in shaping a response rather than the original post. We also study the effect of consensual profanity and observe overlapping similarities with non-consensual profanity in terms of user behavior and patterns.
4/12/2024
🛠️
Grounding Toxicity in Real-World Events across Languages
Wondimagegnhue Tsegaye Tufa, Ilia Markov, Piek Vossen
0
0
Social media conversations frequently suffer from toxicity, creating significant issues for users, moderators, and entire communities. Events in the real world, like elections or conflicts, can initiate and escalate toxic behavior online. Our study investigates how real-world events influence the origin and spread of toxicity in online discussions across various languages and regions. We gathered Reddit data comprising 4.5 million comments from 31 thousand posts in six different languages (Dutch, English, German, Arabic, Turkish and Spanish). We target fifteen major social and political world events that occurred between 2020 and 2023. We observe significant variations in toxicity, negative sentiment, and emotion expressions across different events and language communities, showing that toxicity is a complex phenomenon in which many different factors interact and still need to be investigated. We will release the data for further research along with our code.
5/24/2024

Toxic Memes: A Survey of Computational Perspectives on the Detection and Explanation of Meme Toxicities
Delfina Sol Martinez Pandiani, Erik Tjong Kim Sang, Davide Ceolin
0
0
Internet memes, channels for humor, social commentary, and cultural expression, are increasingly used to spread toxic messages. Studies on the computational analyses of toxic memes have significantly grown over the past five years, and the only three surveys on computational toxic meme analysis cover only work published until 2022, leading to inconsistent terminology and unexplored trends. Our work fills this gap by surveying content-based computational perspectives on toxic memes, and reviewing key developments until early 2024. Employing the PRISMA methodology, we systematically extend the previously considered papers, achieving a threefold result. First, we survey 119 new papers, analyzing 158 computational works focused on content-based toxic meme analysis. We identify over 30 datasets used in toxic meme analysis and examine their labeling systems. Second, after observing the existence of unclear definitions of meme toxicity in computational works, we introduce a new taxonomy for categorizing meme toxicity types. We also note an expansion in computational tasks beyond the simple binary classification of memes as toxic or non-toxic, indicating a shift towards achieving a nuanced comprehension of toxicity. Third, we identify three content-based dimensions of meme toxicity under automatic study: target, intent, and conveyance tactics. We develop a framework illustrating the relationships between these dimensions and meme toxicities. The survey analyzes key challenges and recent trends, such as enhanced cross-modal reasoning, integrating expert and cultural knowledge, the demand for automatic toxicity explanations, and handling meme toxicity in low-resource languages. Also, it notes the rising use of Large Language Models (LLMs) and generative AI for detecting and generating toxic memes. Finally, it proposes pathways for advancing toxic meme detection and interpretation.
6/12/2024

From One to Many: Expanding the Scope of Toxicity Mitigation in Language Models
Luiza Pozzobon, Patrick Lewis, Sara Hooker, Beyza Ermis
0
0
To date, toxicity mitigation in language models has almost entirely been focused on single-language settings. As language models embrace multilingual capabilities, it's crucial our safety measures keep pace. Recognizing this research gap, our approach expands the scope of conventional toxicity mitigation to address the complexities presented by multiple languages. In the absence of sufficient annotated datasets across languages, we employ translated data to evaluate and enhance our mitigation techniques. We also compare finetuning mitigation approaches against retrieval-augmented techniques under both static and continual toxicity mitigation scenarios. This allows us to examine the effects of translation quality and the cross-lingual transfer on toxicity mitigation. We also explore how model size and data quantity affect the success of these mitigation efforts. Covering nine languages, our study represents a broad array of linguistic families and levels of resource availability, ranging from high to mid-resource languages. Through comprehensive experiments, we provide insights into the complexities of multilingual toxicity mitigation, offering valuable insights and paving the way for future research in this increasingly important field. Code and data are available at https://github.com/for-ai/goodtriever.
5/31/2024