Anonymization of Voices in Spaces for Civic Dialogue: Measuring Impact on Empathy, Trust, and Feeling Heard

0

Sign in to get full access
Overview
- The paper explores the impact of voice anonymization on empathy, trust, and feeling heard in civic dialogue spaces.
- It examines how anonymizing speakers' voices affects the dynamics and outcomes of online discussions on public issues.
- The researchers conducted experiments to measure the effects of voice anonymization on participants' perceptions and experiences.
Plain English Explanation
The paper looks at how hiding people's voices in online discussions about public topics can influence how others feel. When people can't tell who's speaking, does it change how much empathy, trust, and sense of being heard the participants have?
The researchers set up experiments to test this. They had people participate in online discussions, sometimes with the speakers' voices anonymized and sometimes not. Then they measured things like how much the participants felt they could relate to the speakers, how much they trusted what was said, and how heard they felt their own voices were.
The goal was to understand how voice anonymization - making speakers' identities less clear - might impact the quality and dynamics of civic dialogue. This could have important implications for designing online platforms and tools to support productive public discussions.
Technical Explanation
The paper presents an empirical study on the effects of voice anonymization in civic dialogue spaces. The researchers conducted a series of experiments where participants engaged in online discussions on public issues, with the speakers' voices either anonymized or not.
The experimental design involved two conditions: a voice anonymization condition where speakers' voices were altered to be unidentifiable, and a control condition with normal, un-anonymized voices. Participants were randomly assigned to one of these conditions and then completed surveys to assess their sense of empathy, trust, and feeling heard during the discussion.
The voice anonymization was implemented using a text-to-speech synthesis pipeline that converted the speakers' audio to synthetic voices. This allowed the researchers to isolate the impact of voice anonymity while holding the content and information conveyed constant.
The results showed that voice anonymization had a significant effect on participants' perceptions and experiences. Compared to the control condition, the anonymized voice condition led to lower reported empathy, trust, and feeling heard. These findings suggest that preserving speaker identity through non-anonymous voices may be important for fostering productive civic dialogue.
Critical Analysis
The paper provides valuable insights into the role of speaker identity in online discussions, but also acknowledges several limitations and areas for further research.
One key limitation is the artificial nature of the experimental setup. While this allowed for controlled comparisons, it may not fully capture the complexities of real-world civic dialogue spaces. Further research is needed to understand how the effects of voice anonymization play out in more naturalistic settings.
Additionally, the paper does not explore potential moderating factors, such as the specific topics being discussed or the demographics of the participants. It's possible that the impact of voice anonymization could vary depending on the context and the individuals involved.
The researchers also note that their study focused solely on voice anonymization, but there are other forms of anonymity (e.g., text-only, avatar-based) that could have different effects. Examining a broader range of anonymity interventions would provide a more comprehensive understanding of this issue.
Despite these limitations, the paper makes an important contribution by highlighting the potential trade-offs involved in voice anonymization for civic dialogue. As online platforms continue to evolve, these findings can inform the design of tools and policies to support productive public discussions.
Conclusion
This paper demonstrates that voice anonymization can have significant impacts on the quality of civic dialogue, as measured by participants' empathy, trust, and feeling of being heard. The findings suggest that preserving speaker identity may be important for fostering productive discussions on public issues.
The research provides a foundation for further exploration of the role of speaker identity in online civic spaces, and highlights the need to consider the potential unintended consequences of anonymity features. As designers and policymakers work to create more inclusive and effective platforms for public discourse, the insights from this study can help inform their decisions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Anonymization of Voices in Spaces for Civic Dialogue: Measuring Impact on Empathy, Trust, and Feeling Heard
Wonjune Kang, Margaret A. Hughes, Deb Roy
Anonymity is a powerful component of many participatory media platforms that can afford people greater freedom of expression and protection from external coercion and interference. However, it can be difficult to effectively implement on platforms that leverage spoken language due to distinct biomarkers present in the human voice. In this work, we explore the use of voice anonymization methods within the context of a technology-enhanced civic dialogue network based in the United States, whose purpose is to increase feelings of agency and being heard within civic processes. Specifically, we investigate the use of two different speech transformation and synthesis methods for anonymization: voice conversion (VC) and text-to-speech (TTS). Through a series of two studies, we examine the impact that each method has on 1) the empathy and trust that listeners feel towards a person sharing a personal story, and 2) a speaker's own perception of being heard, finding that voice conversion is an especially suitable method for our purposes. Our findings open up interesting potential research directions related to anonymous spoken discourse, as well as additional ways of engaging with voice-based civic technologies.
Read more8/27/2024
0
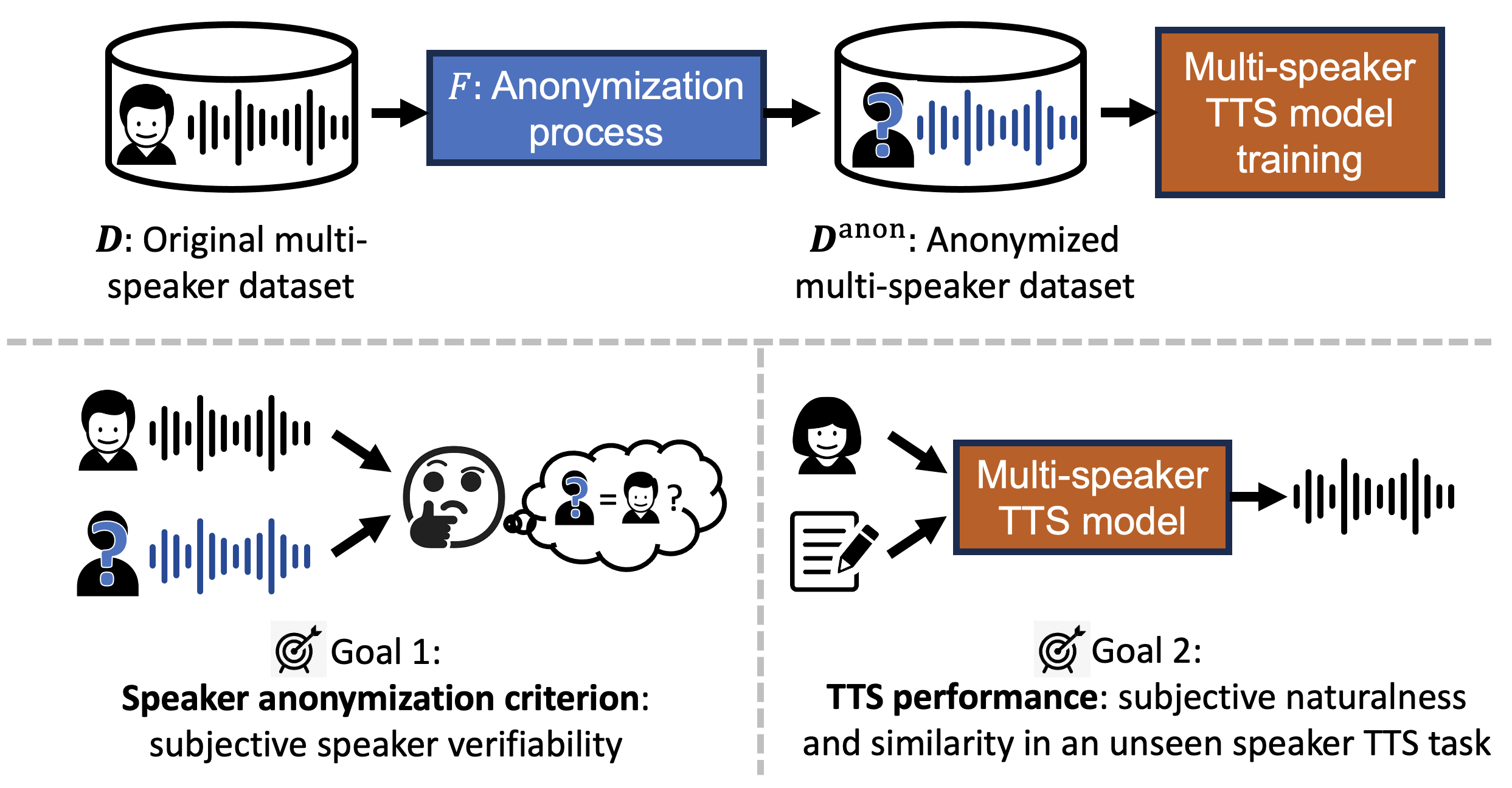
Multi-speaker Text-to-speech Training with Speaker Anonymized Data
Wen-Chin Huang, Yi-Chiao Wu, Tomoki Toda
The trend of scaling up speech generation models poses a threat of biometric information leakage of the identities of the voices in the training data, raising privacy and security concerns. In this paper, we investigate training multi-speaker text-to-speech (TTS) models using data that underwent speaker anonymization (SA), a process that tends to hide the speaker identity of the input speech while maintaining other attributes. Two signal processing-based and three deep neural network-based SA methods were used to anonymize VCTK, a multi-speaker TTS dataset, which is further used to train an end-to-end TTS model, VITS, to perform unseen speaker TTS during the testing phase. We conducted extensive objective and subjective experiments to evaluate the anonymized training data, as well as the performance of the downstream TTS model trained using those data. Importantly, we found that UTMOS, a data-driven subjective rating predictor model, and GVD, a metric that measures the gain of voice distinctiveness, are good indicators of the downstream TTS performance. We summarize insights in the hope of helping future researchers determine the goodness of the SA system for multi-speaker TTS training.
Read more5/21/2024
🗣️
0
On the Impact of Voice Anonymization on Speech Diagnostic Applications: a Case Study on COVID-19 Detection
Yi Zhu, Mohamed Imoussaine-Aikous, Carolyn C^ot'e-Lussier, Tiago H. Falk
With advances seen in deep learning, voice-based applications are burgeoning, ranging from personal assistants, affective computing, to remote disease diagnostics. As the voice contains both linguistic and para-linguistic information (e.g., vocal pitch, intonation, speech rate, loudness), there is growing interest in voice anonymization to preserve speaker privacy and identity. Voice privacy challenges have emerged over the last few years and focus has been placed on removing speaker identity while keeping linguistic content intact. For affective computing and disease monitoring applications, however, the para-linguistic content may be more critical. Unfortunately, the effects that anonymization may have on these systems are still largely unknown. In this paper, we fill this gap and focus on one particular health monitoring application: speech-based COVID-19 diagnosis. We test three anonymization methods and their impact on five different state-of-the-art COVID-19 diagnostic systems using three public datasets. We validate the effectiveness of the anonymization methods, compare their computational complexity, and quantify the impact across different testing scenarios for both within- and across-dataset conditions. Additionally, we provided a comprehensive evaluation of the importance of different speech aspects for diagnostics and showed how they are affected by different types of anonymizers. Lastly, we show the benefits of using anonymized external data as a data augmentation tool to help recover some of the COVID-19 diagnostic accuracy loss seen with anonymization.
Read more6/27/2024
🗣️
0
The Impact of Speech Anonymization on Pathology and Its Limits
Soroosh Tayebi Arasteh, Tomas Arias-Vergara, Paula Andrea Perez-Toro, Tobias Weise, Kai Packhaeuser, Maria Schuster, Elmar Noeth, Andreas Maier, Seung Hee Yang
Integration of speech into healthcare has intensified privacy concerns due to its potential as a non-invasive biomarker containing individual biometric information. In response, speaker anonymization aims to conceal personally identifiable information while retaining crucial linguistic content. However, the application of anonymization techniques to pathological speech, a critical area where privacy is especially vital, has not been extensively examined. This study investigates anonymization's impact on pathological speech across over 2,700 speakers from multiple German institutions, focusing on privacy, pathological utility, and demographic fairness. We explore both deep-learning-based and signal processing-based anonymization methods. We document substantial privacy improvements across disorders-evidenced by equal error rate increases up to 1933%, with minimal overall impact on utility. Specific disorders such as Dysarthria, Dysphonia, and Cleft Lip and Palate experience minimal utility changes, while Dysglossia shows slight improvements. Our findings underscore that the impact of anonymization varies substantially across different disorders. This necessitates disorder-specific anonymization strategies to optimally balance privacy with diagnostic utility. Additionally, our fairness analysis reveals consistent anonymization effects across most of the demographics. This study demonstrates the effectiveness of anonymization in pathological speech for enhancing privacy, while also highlighting the importance of customized and disorder-specific approaches to account for inversion attacks.
Read more9/20/2024