Multi-speaker Text-to-speech Training with Speaker Anonymized Data

0
Sign in to get full access
Overview
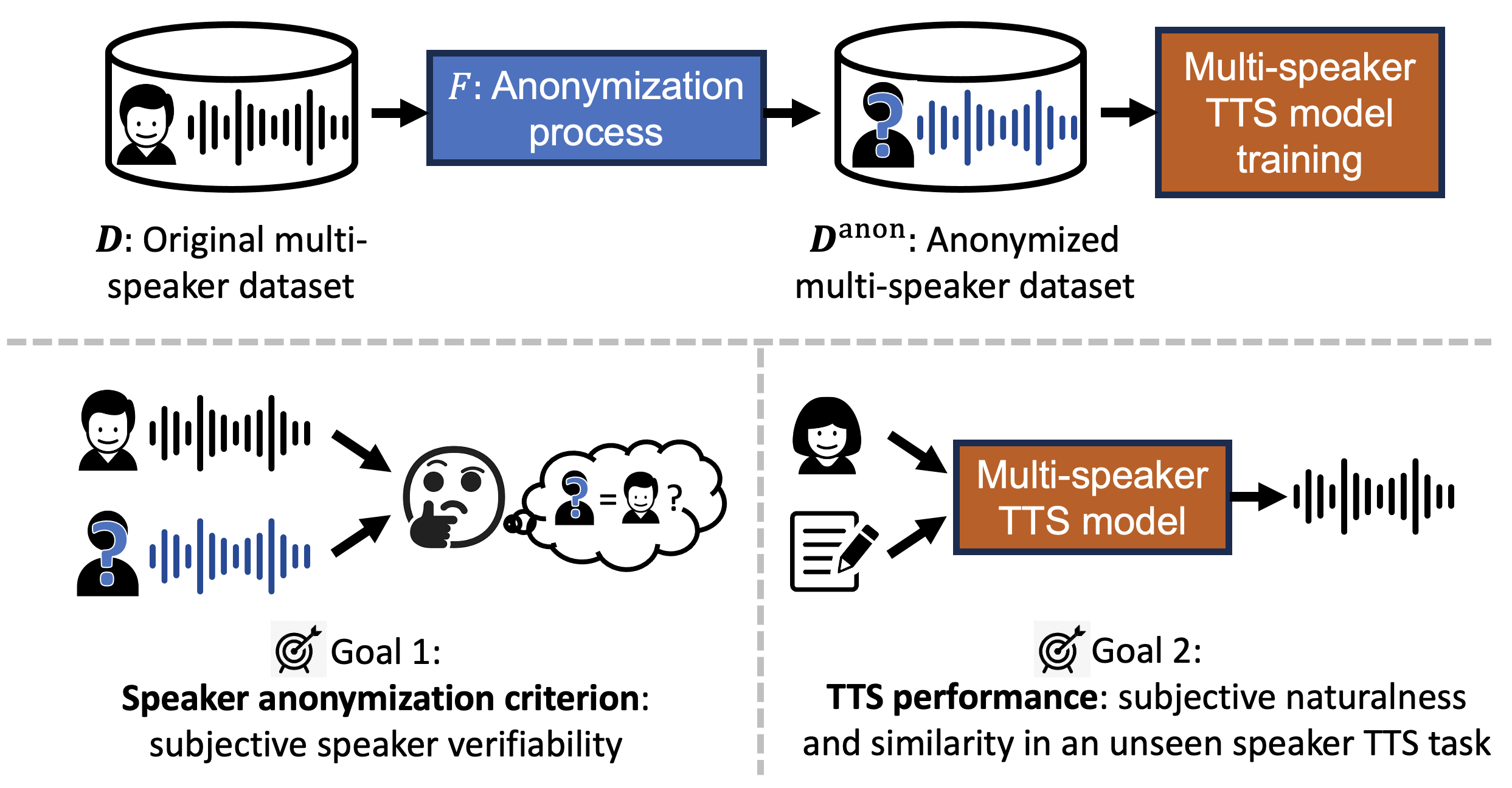
- This paper presents a method for training multi-speaker text-to-speech (TTS) models using speaker anonymized data.
- The goal is to enable TTS systems to generate speech without revealing the original speaker's identity.
- The proposed approach uses a speaker anonymization module to remove speaker-specific features from the input speech.
- The TTS model is then trained on the anonymized speech data to generate speech without the original speaker's voice characteristics.
Plain English Explanation
The paper describes a way to train text-to-speech (TTS) systems that can generate speech without revealing the original speaker's identity. This is useful for protecting people's privacy, especially in applications where sensitive information is being spoken.
The key idea is to first "anonymize" the input speech by removing the unique characteristics of the speaker's voice. This is done using a special module in the model. The TTS system is then trained on this anonymized speech data, so that when it generates new speech, it doesn't sound like any particular person.
This allows the TTS model to produce synthetic speech that sounds natural and fluent, but without the identifying voice features of the original speakers. It's kind of like creating a "voice double" that can speak the words without giving away who originally said them.
The researchers who worked on speaker anonymization via singular value decomposition and the team that looked at authenticating speakers have explored related techniques for preserving speaker privacy. This work builds on those foundations to enable multi-speaker TTS training with anonymized data.
Technical Explanation
The paper proposes a method for training multi-speaker text-to-speech (TTS) models using speaker anonymized data. The key components are:
-
Speaker Anonymization Module: This module takes the input speech and removes the unique characteristics of the speaker's voice. It does this by applying a linear transformation to the speech features, which effectively "anonymizes" the speaker identity.
-
Multi-speaker TTS Model: The TTS model is trained on the anonymized speech data from multiple speakers. It learns to generate natural-sounding speech without the original speaker's voice characteristics.
The authors evaluate their approach on several TTS benchmarks, including the USAT universal speaker-adaptive TTS model and a multi-lingual zero-shot speaker verification task similar to the work on clinical speaker verification. The results show that the anonymized TTS model can generate high-quality speech while effectively hiding the original speaker's identity.
Critical Analysis
The paper presents a compelling approach for enabling multi-speaker TTS with speaker anonymization. However, there are a few potential limitations and areas for further research:
-
Preserving Speaker Expressivity: While the anonymization module removes speaker-specific features, it's unclear how this affects the emotional expressiveness and prosody of the generated speech. Further work may be needed to maintain these important aspects of natural-sounding speech.
-
Impact on Downstream Applications: The impact of speaker anonymization on downstream applications that rely on speaker identity, such as speaker authentication, should be investigated more thoroughly.
-
Generalization to Diverse Datasets: The evaluation was conducted on relatively clean, high-quality speech datasets. It would be important to test the approach on more diverse and challenging data, such as conversational or noisy speech.
-
Interpretability of the Anonymization Process: The paper does not provide much insight into how the anonymization module works or what specific aspects of the speaker's voice it is removing. More transparency around this could help users better understand the implications of the approach.
Overall, the proposed method is a valuable contribution to the field of privacy-preserving speech technology. Further research to address the above considerations could strengthen the practical applicability and robustness of the approach.
Conclusion
This paper presents a novel technique for training multi-speaker text-to-speech (TTS) models using speaker anonymized data. The key innovation is a speaker anonymization module that removes the unique voice characteristics of the original speakers, enabling the TTS model to generate natural-sounding speech without revealing the identity of the people whose voices were used for training.
This work advances the state of the art in privacy-preserving speech synthesis, with potential applications in areas where protecting speaker identity is important, such as in-home assistants, accessibility tools, and audio content generation. By combining speaker anonymization with multi-speaker TTS, the proposed approach could enable more inclusive and secure speech technology that respects individual privacy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-speaker Text-to-speech Training with Speaker Anonymized Data
Wen-Chin Huang, Yi-Chiao Wu, Tomoki Toda
The trend of scaling up speech generation models poses a threat of biometric information leakage of the identities of the voices in the training data, raising privacy and security concerns. In this paper, we investigate training multi-speaker text-to-speech (TTS) models using data that underwent speaker anonymization (SA), a process that tends to hide the speaker identity of the input speech while maintaining other attributes. Two signal processing-based and three deep neural network-based SA methods were used to anonymize VCTK, a multi-speaker TTS dataset, which is further used to train an end-to-end TTS model, VITS, to perform unseen speaker TTS during the testing phase. We conducted extensive objective and subjective experiments to evaluate the anonymized training data, as well as the performance of the downstream TTS model trained using those data. Importantly, we found that UTMOS, a data-driven subjective rating predictor model, and GVD, a metric that measures the gain of voice distinctiveness, are good indicators of the downstream TTS performance. We summarize insights in the hope of helping future researchers determine the goodness of the SA system for multi-speaker TTS training.
Read more5/21/2024

0
Probing the Feasibility of Multilingual Speaker Anonymization
Sarina Meyer, Florian Lux, Ngoc Thang Vu
In speaker anonymization, speech recordings are modified in a way that the identity of the speaker remains hidden. While this technology could help to protect the privacy of individuals around the globe, current research restricts this by focusing almost exclusively on English data. In this study, we extend a state-of-the-art anonymization system to nine languages by transforming language-dependent components to their multilingual counterparts. Experiments testing the robustness of the anonymized speech against privacy attacks and speech deterioration show an overall success of this system for all languages. The results suggest that speaker embeddings trained on English data can be applied across languages, and that the anonymization performance for a language is mainly affected by the quality of the speech synthesis component used for it.
Read more7/4/2024

0
A Benchmark for Multi-speaker Anonymization
Xiaoxiao Miao, Ruijie Tao, Chang Zeng, Xin Wang
Privacy-preserving voice protection approaches primarily suppress privacy-related information derived from paralinguistic attributes while preserving the linguistic content. Existing solutions focus on single-speaker scenarios. However, they lack practicality for real-world applications, i.e., multi-speaker scenarios. In this paper, we present an initial attempt to provide a multi-speaker anonymization benchmark by defining the task and evaluation protocol, proposing benchmarking solutions, and discussing the privacy leakage of overlapping conversations. Specifically, ideal multi-speaker anonymization should preserve the number of speakers and the turn-taking structure of the conversation, ensuring accurate context conveyance while maintaining privacy. To achieve that, a cascaded system uses speaker diarization to aggregate the speech of each speaker and speaker anonymization to conceal speaker privacy and preserve speech content. Additionally, we propose two conversation-level speaker vector anonymization methods to improve the utility further. Both methods aim to make the original and corresponding pseudo-speaker identities of each speaker unlinkable while preserving or even improving the distinguishability among pseudo-speakers in a conversation. The first method minimizes the differential similarity across speaker pairs in the original and anonymized conversations to maintain original speaker relationships in the anonymized version. The other method minimizes the aggregated similarity across anonymized speakers to achieve better differentiation between speakers. Experiments conducted on both non-overlap simulated and real-world datasets demonstrate the effectiveness of the multi-speaker anonymization system with the proposed speaker anonymizers. Additionally, we analyzed overlapping speech regarding privacy leakage and provide potential solutions.
Read more7/9/2024

0
Asynchronous Voice Anonymization Using Adversarial Perturbation On Speaker Embedding
Rui Wang, Liping Chen, Kong AiK Lee, Zhen-Hua Ling
Voice anonymization has been developed as a technique for preserving privacy by replacing the speaker's voice in a speech signal with that of a pseudo-speaker, thereby obscuring the original voice attributes from machine recognition and human perception. In this paper, we focus on altering the voice attributes against machine recognition while retaining human perception. We referred to this as the asynchronous voice anonymization. To this end, a speech generation framework incorporating a speaker disentanglement mechanism is employed to generate the anonymized speech. The speaker attributes are altered through adversarial perturbation applied on the speaker embedding, while human perception is preserved by controlling the intensity of perturbation. Experiments conducted on the LibriSpeech dataset showed that the speaker attributes were obscured with their human perception preserved for 60.71% of the processed utterances.
Read more6/14/2024